
摘要:心肺听诊是临床诊断心肺疾病的重要手段,但传统听诊依赖医生主观经验,诊断结果易受个体差异影响。为提高心肺音分类的客观性准确性,本文设计并实现了一套基于集成学习的心肺听诊音自动分类系统。
项目简介
DeepCure 是一套基于集成学习的心肺听诊音自动分类系统,旨在辅助临床医生快速筛查心肺异常。系统涵盖从音频预处理、特征提取 、模型训练到可视化诊断的完整流程。
系统概述
本系统采用 51 例心音、51 例肺音及 146 例心肺混合录音作为实验数据。在预处理阶段,对原始音频进行降噪、归一化及高通滤波处理,并利用 Butterworth 带通滤波器将混合录音分离为心音分量(20–150 Hz)和肺音分量(150–2000 Hz)。在特征提取阶段,提取了 13 维 MFCC 系数及其统计量、频谱质心、频谱带宽、频谱滚降、频谱平坦度、频谱对比度、过零率、短时能量、起始强度、峰态系数等共计 40 余维声学特征。针对肺音中爆裂音与喘鸣音难以区分的问题,引入频谱平坦度、频谱对比度及起始检测等判别性特征以增强分类能力 同时,采用类别感知的数据增强策略(包括噪声注入、时间平移、时间拉伸、音调偏移等)缓解样本不均衡问题。
在分类模型方面,构建了基于随机森林、XGBoost和支持向量机的软投票集成分类器,分别针对心音四分类(正常、杂音、心律不齐、额外心音)和肺音三分类(正常、爆裂音、喘鸣/鼾音)任务进行训练与优化。通过类别加权采样、正则化参数调优及五折交叉验证等策略提升模型的泛化性能。
最终,基于 PySide6 框架开发了桌面端可视化应用,实现了音频上传、心肺音分离、波形与频谱可视化、自动分类诊断及置信度展示 等功能,为临床辅助诊断提供了一套完整的解决方案。
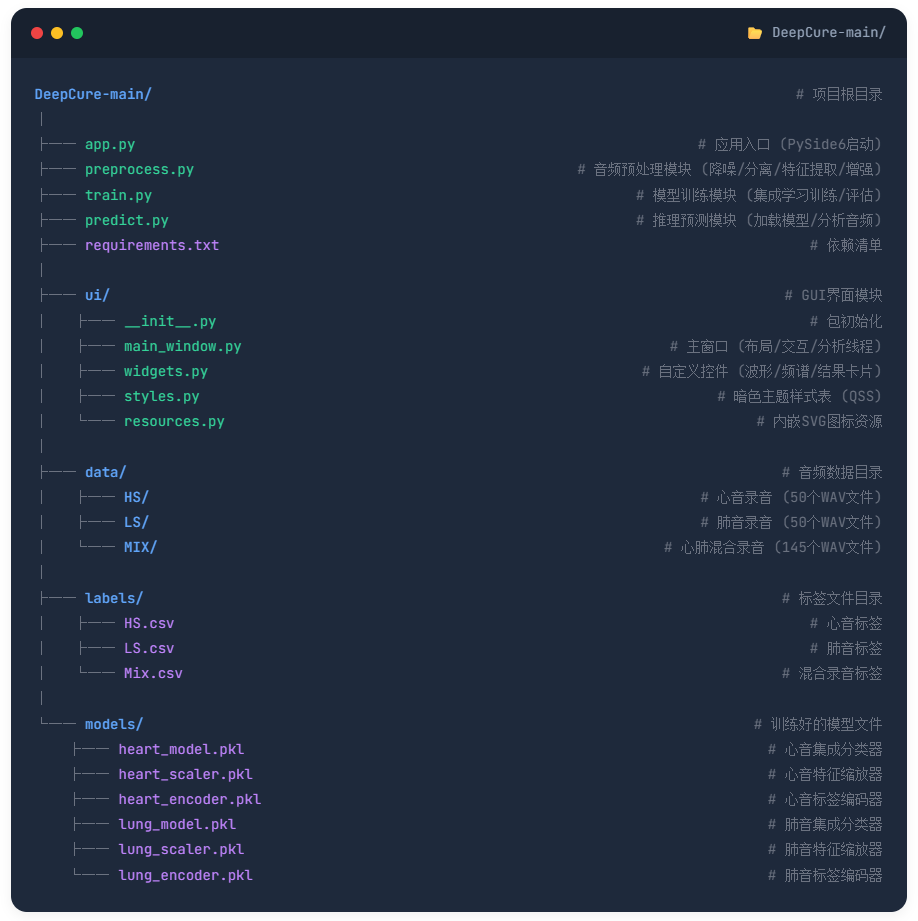
系统架构
系统采用”音频预处理→Butterworth带通滤波心肺分离→多维声学特征提取→RF+XGBoost+SVM软投票集成分类→PySide6桌面端可视化诊断”的五阶段流水线架构。
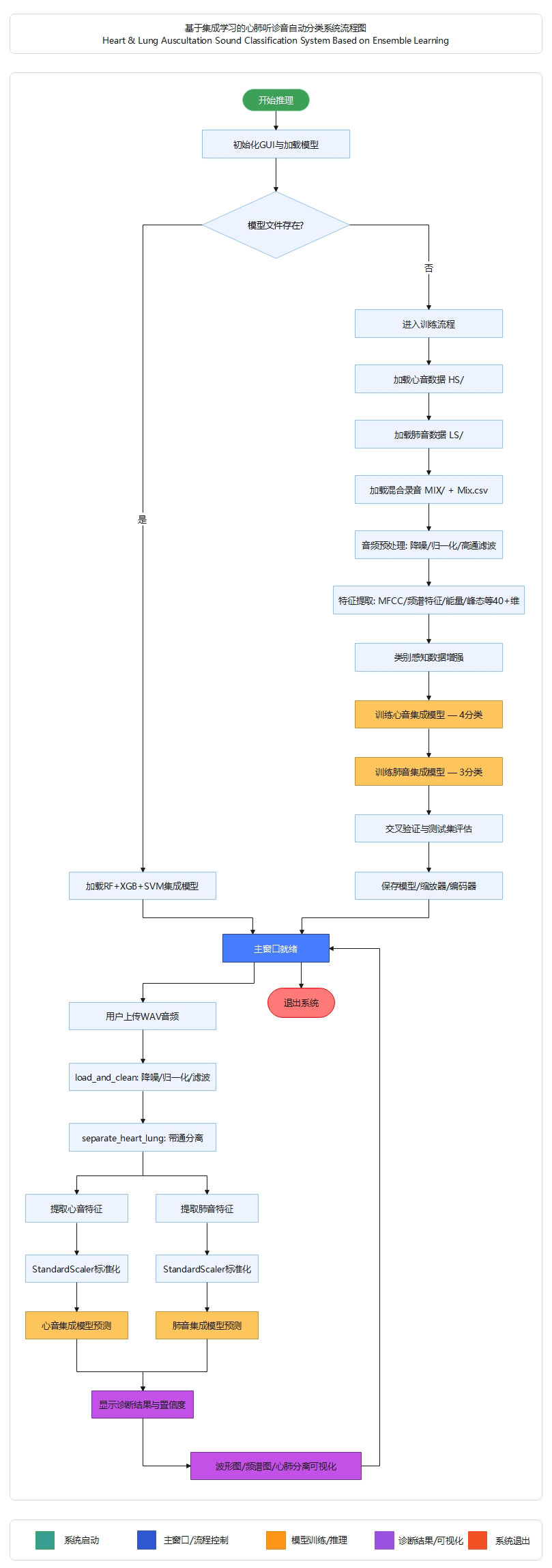
项目结构
项目采用四层模块化架构:preprocess.py 负责音频降噪、心肺分离与特征提取,train.py 构建RF+XGBoost+SVM集成模型并训练评估,predict.py 加载模型进行推理预测,ui/ 包提供PySide6桌面端可视化界面。训练产物保存在 models/ 目录下。
目录结构
核心模块
系统由四个核心模块组成。音频预处理模块负责原始音频的降噪、归一化与高通滤波,通过Butterworth带通滤波器将混合录音分离为 心音(20–150 Hz)和肺音(150–2000 Hz)分量,并提取MFCC、频谱质心、频谱平坦度、频谱对比度、过零率、短时能量、起始强度 峰态系数等40余维声学特征,同时支持类别感知的数据增强策略。模型训练模块从HS、LS、MIX三个数据源加载音频,映射为心音四分类和肺音三分类标签,构建随机森林、XGBoost和SVM软投票集成分类器,通过类别加权采样和五折交叉验证优化模型泛化性能。推理 测模块加载已训练的集成模型、缩放器和标签编码器,对新音频完成预处理、分离、特征提取到分类推理的全流程分析。桌面界面模 基于PySide6构建暗色医疗主题应用,提供音频上传、波形与频谱可视化、心肺分离波形对比、诊断结果与置信度展示等交互功能。
快速开始
安装依赖 pip install -r requirements.txt,然后执行 python app.py 启动桌面应用。上传WAV音频文件后点击”开始分析”,系统自动完成心肺音分离、特征提取与分类诊断。
执行 python train.py 启动训练流程。系统自动加载 data/HS/、data/LS/ 和 data/MIX/ 中的音频数据,经预处理和特征提取后,分别训练心音四分类(正常/杂音/心律不齐/额外心音)和肺音三分类(正常/爆裂音/喘鸣鼾音)集成模型,结果保存至 models/ 目录。
环境要求
系统运行环境要求Python 3.8及以上版本,核心依赖包括PySide6桌面GUI框架、scikit-learn机器学习库、XGBoost梯度提升库、libro sa音频处理库、scipy信号处理库、noisereduce音频降噪库、matplotlib数据可视化库、pandas数据处理库、numpy数值计算库及sound file音频读写库。所有依赖均可通过pip install -r requirements.txt一键安装。
运行实验
系统提供训练和推理两种运行模式。训练模式下执行python train.py,系统自动加载data/HS、data/LS和data/MIX目录下的音频数据 及labels目录下的标签文件,依次完成音频降噪、心肺分离、特征提取和类别感知数据增强,分别训练心音四分类和肺音三分类集成 型,通过五折交叉验证评估模型性能,最终将模型、缩放器和标签编码器保存至models目录。推理模式下执行python app.py启动桌面 应用,在界面左侧点击”上传音频文件”选择WAV格式录音,点击”开始分析”后系统自动完成音频预处理、心肺音分离、特征提取与集成 模型推理,右侧内容区同步展示完整音频波形图、梅尔频谱图、心肺分离波形对比以及心音和肺音的诊断结果与各类别置信度
查看结果
分析完成后,界面顶部文件信息栏显示当前音频的文件名、时长、采样率和文件大小。可视化区域提供三个标签页:波形图展示完整── 频的时域波形,频谱图展示梅尔频谱的时频分布,心肺分离页展示经带通滤波分离后的心音(20–150 Hz)和肺音(150–2000 Hz)波形对比。下方两张诊断卡片分别显示心音和肺音的分类结果,包括诊断标签、最高置信度百分比以及各类别的概率分布进度条── 左侧边栏同步显示估算的心率和呼吸频率。正常结果以绿色标识,异常结果以橙色警示标识。
实验结果
系统在心音四分类和肺音三分类任务上均取得了较好的分类效果,通过五折交叉验证和独立测试集评估验证了集成学习模型的泛化能力。
识别效果
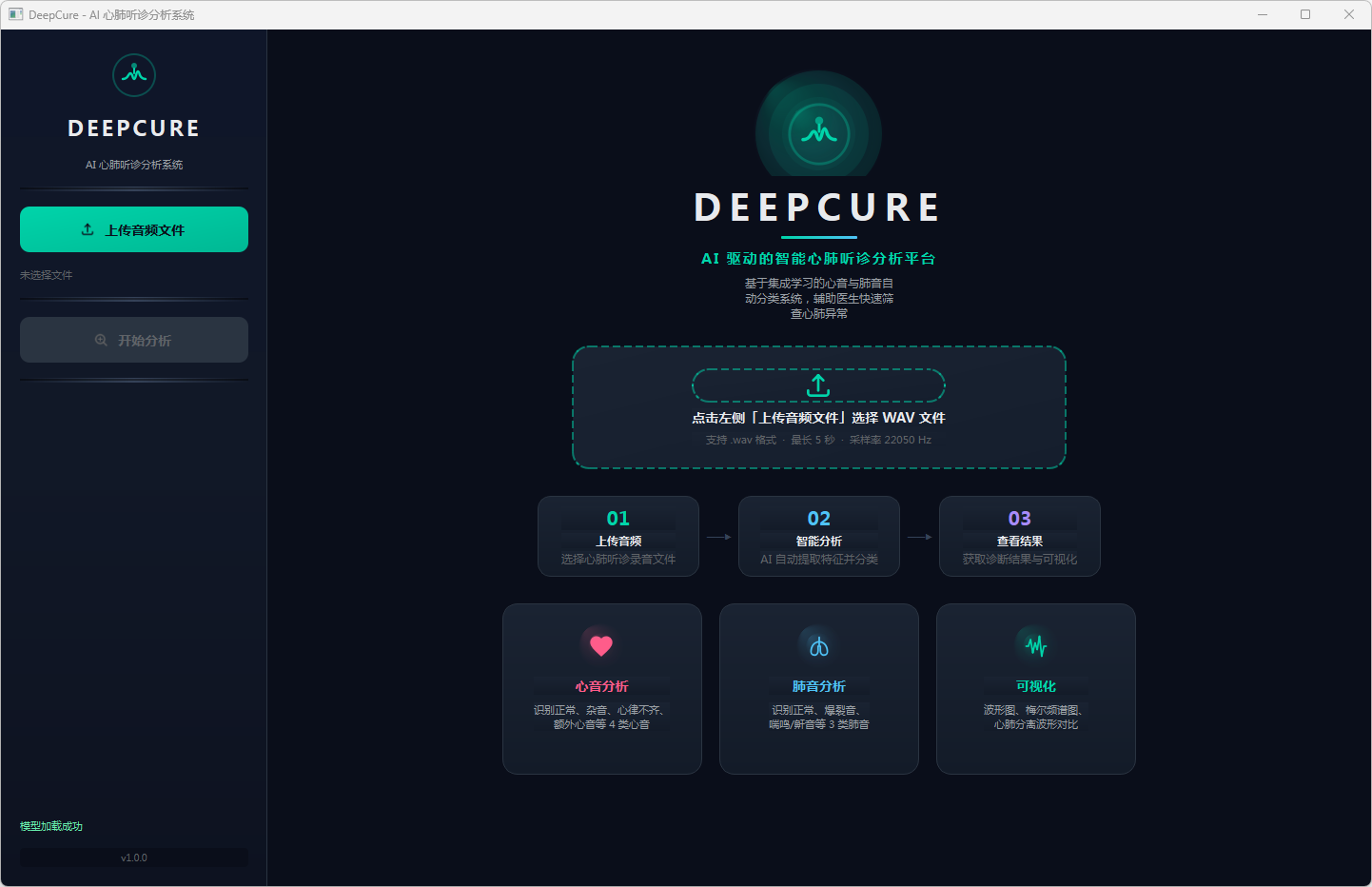
图1 系统界面
图2 文件就绪
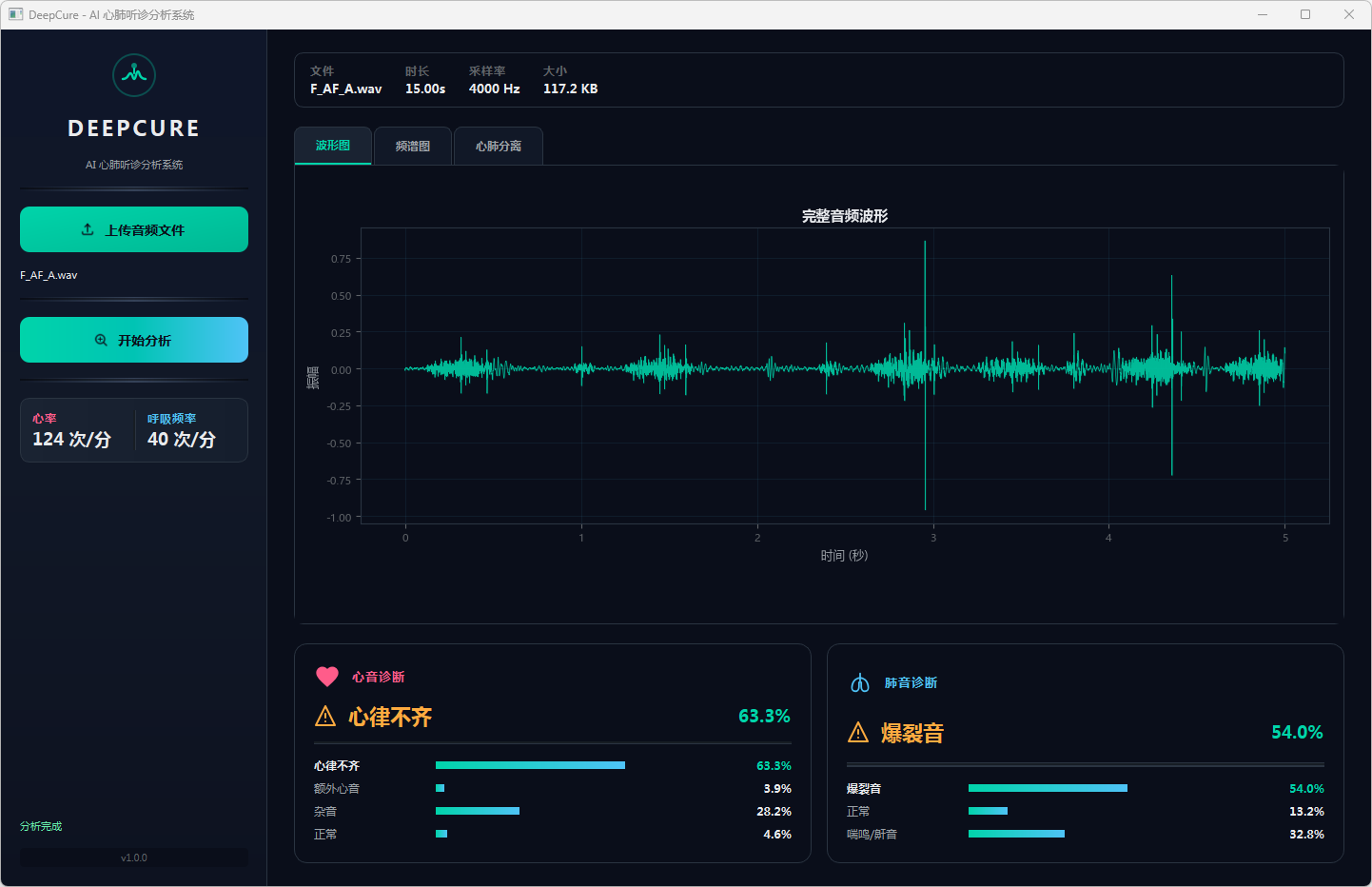
图3 心音诊断:心率不齐 & 肺音诊断:爆裂音 波形图
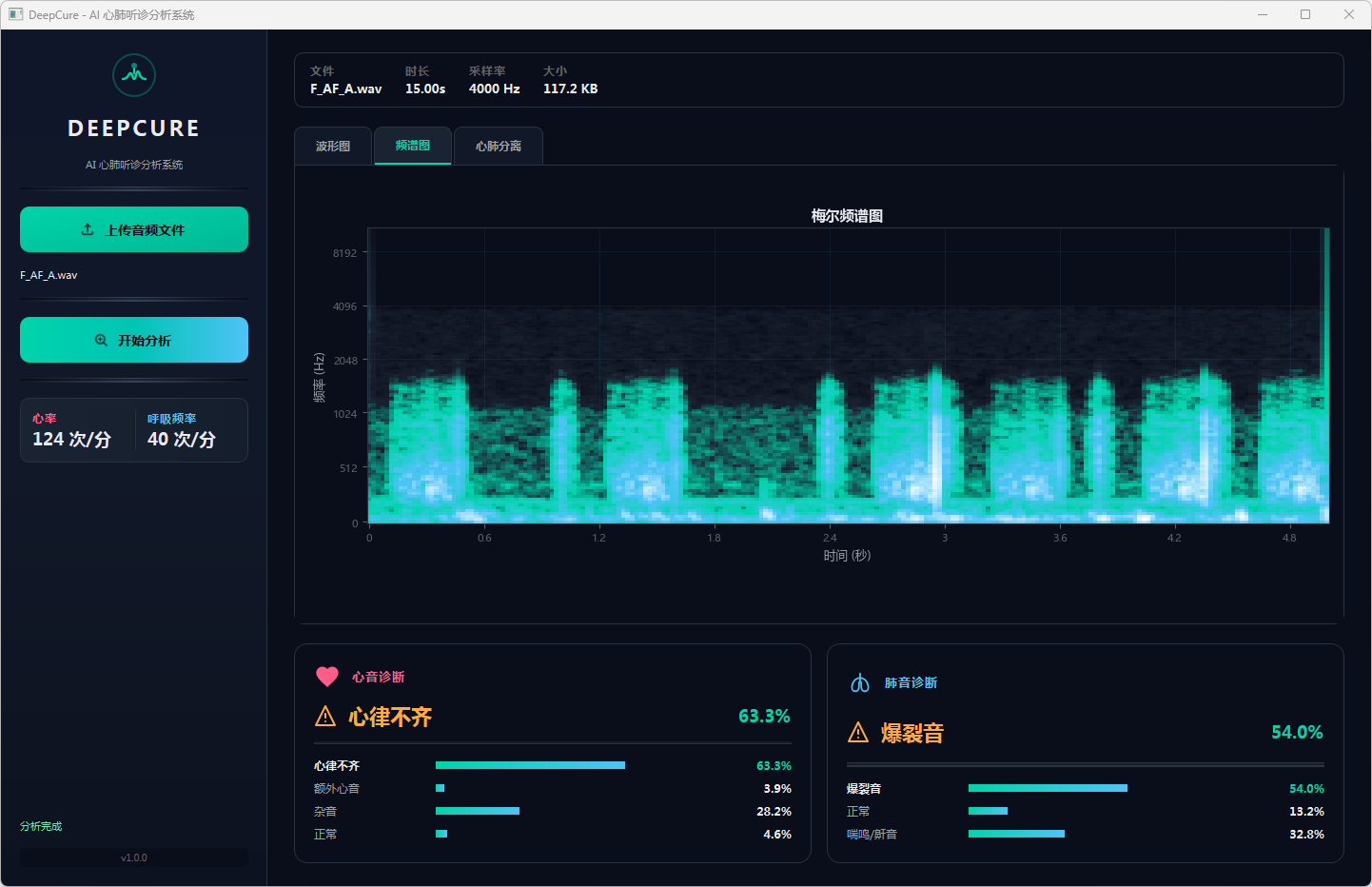
图4 心音诊断:心率不齐 & 肺音诊断:爆裂音 频谱图
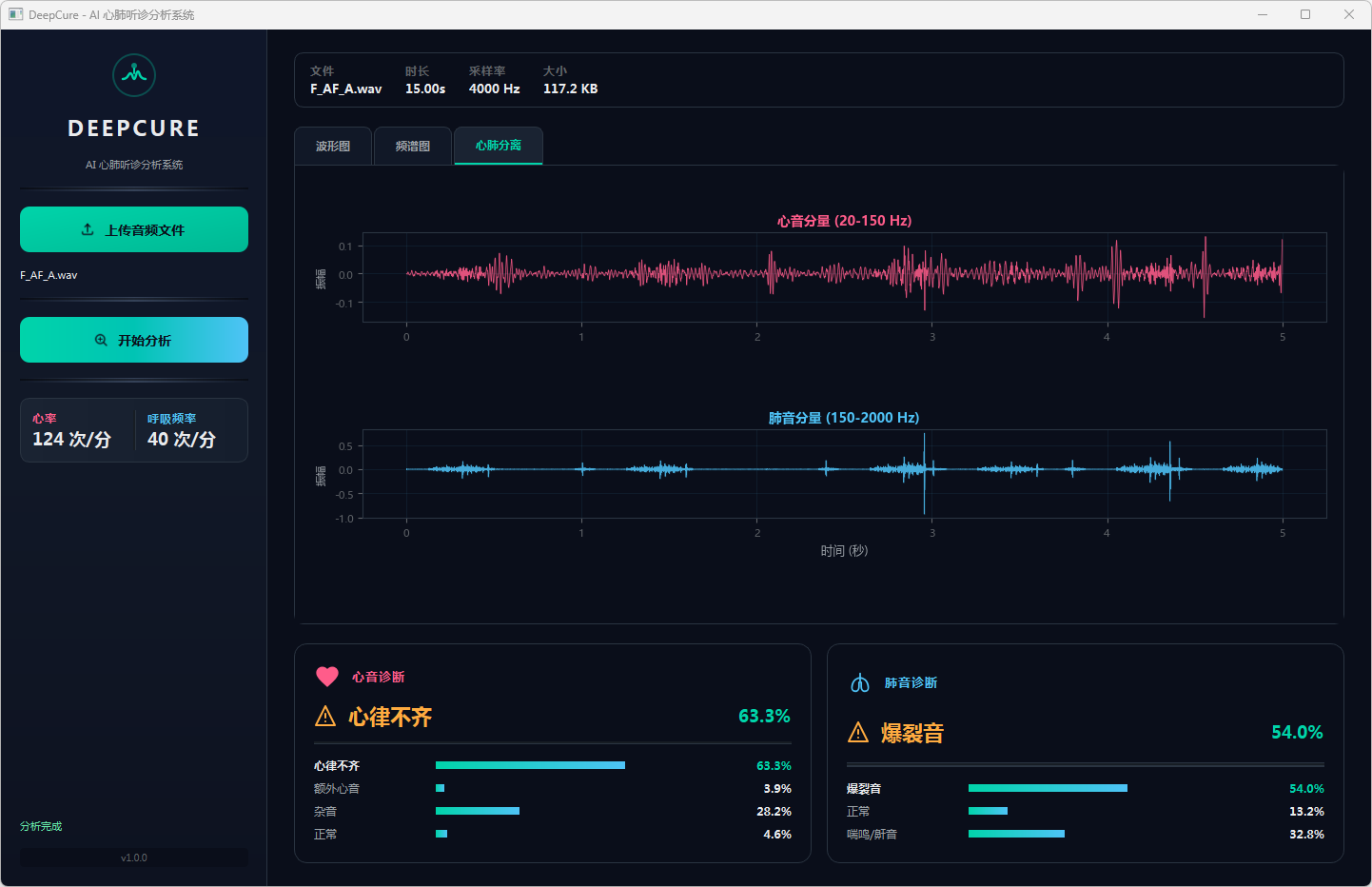
图5 心音诊断:心率不齐 & 肺音诊断:爆裂音 心肺分离
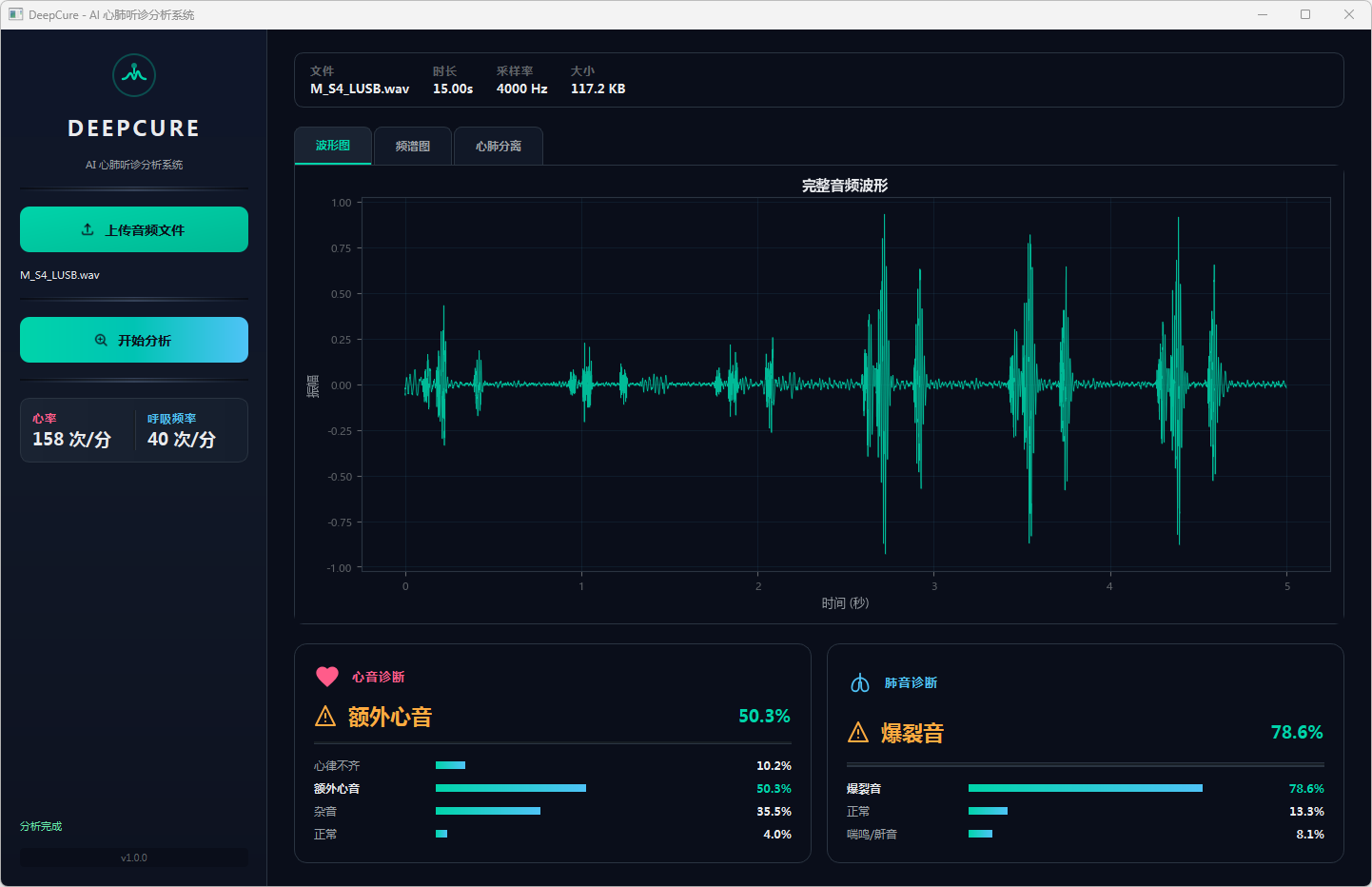
图6 心音诊断:额外心音 & 肺音诊断:爆裂音 波形图
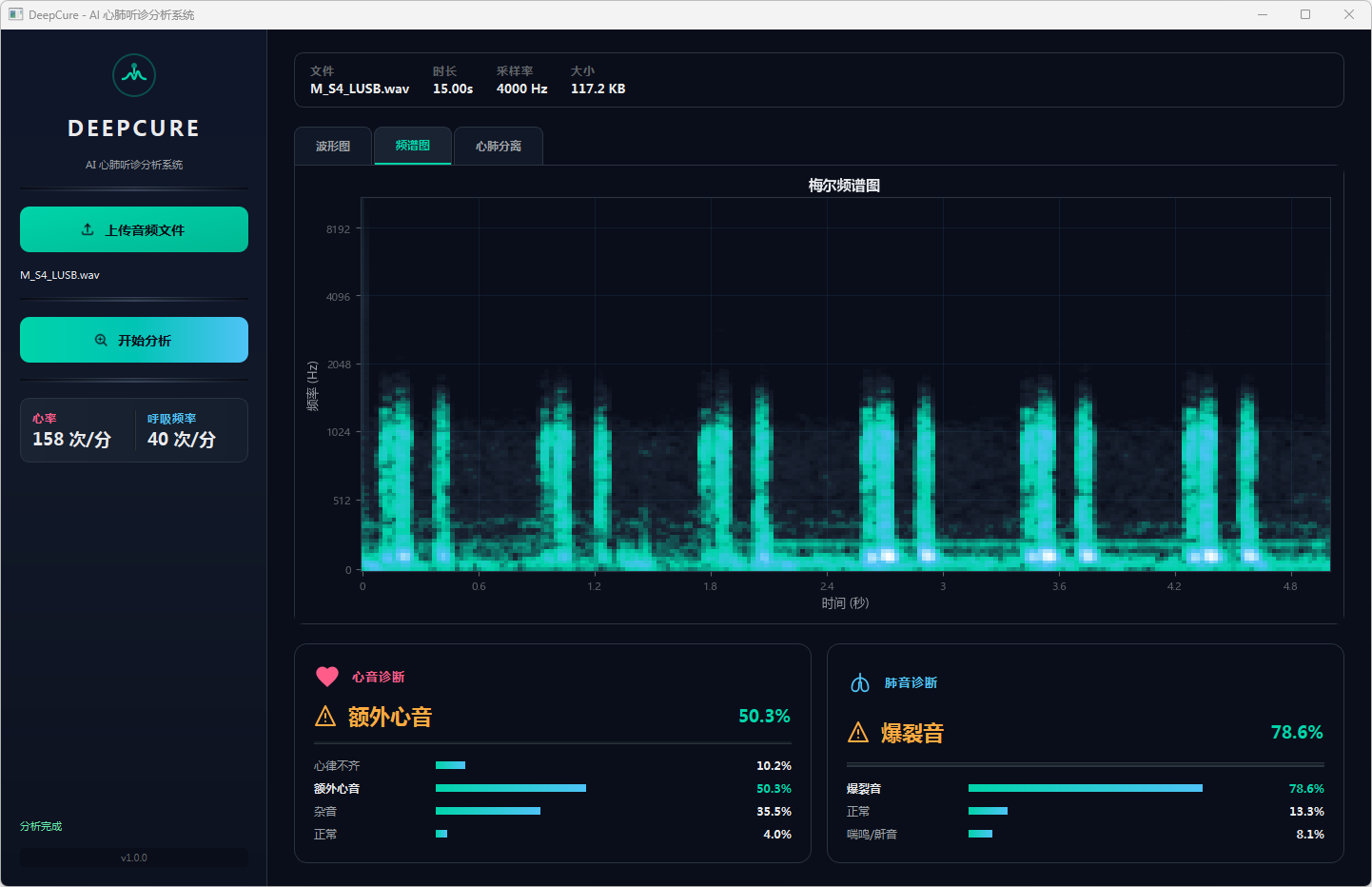
图7 心音诊断:额外心音 & 肺音诊断:爆裂音 频谱图
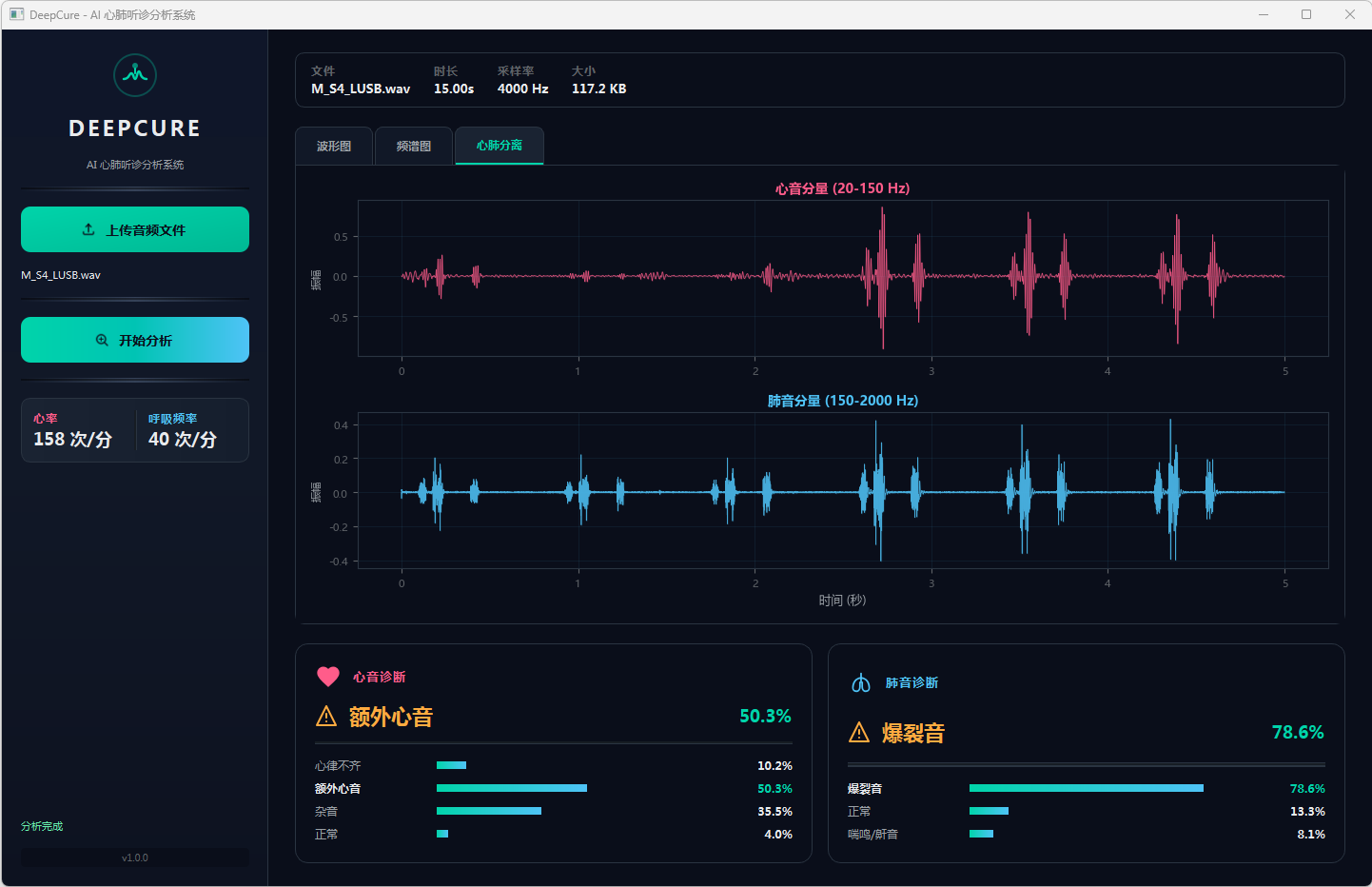
图8 心音诊断:额外心音 & 肺音诊断:爆裂音 心肺分离
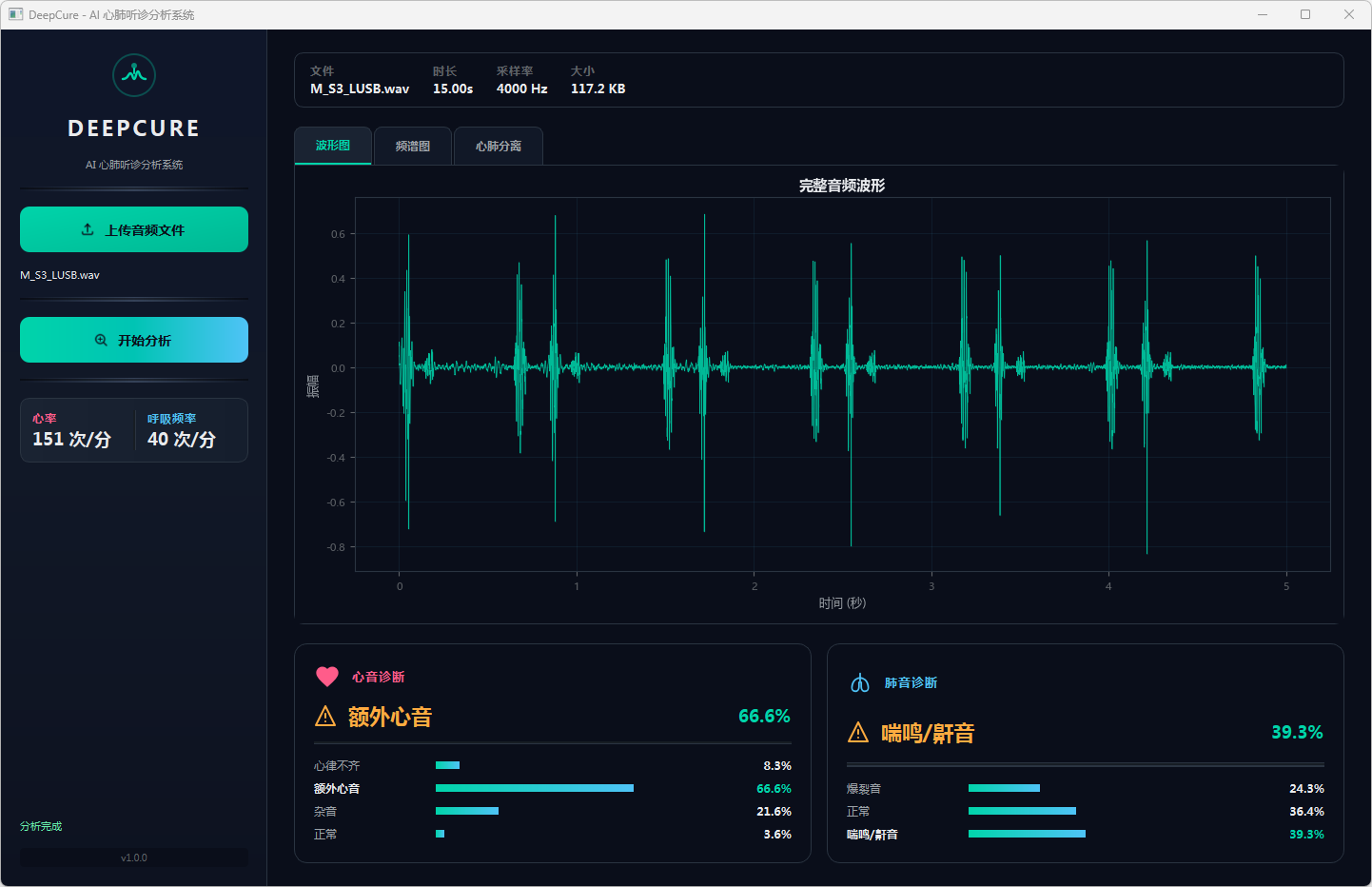
图9 心音诊断:额外心音 & 肺音诊断:喘鸣/鼾音 波形图
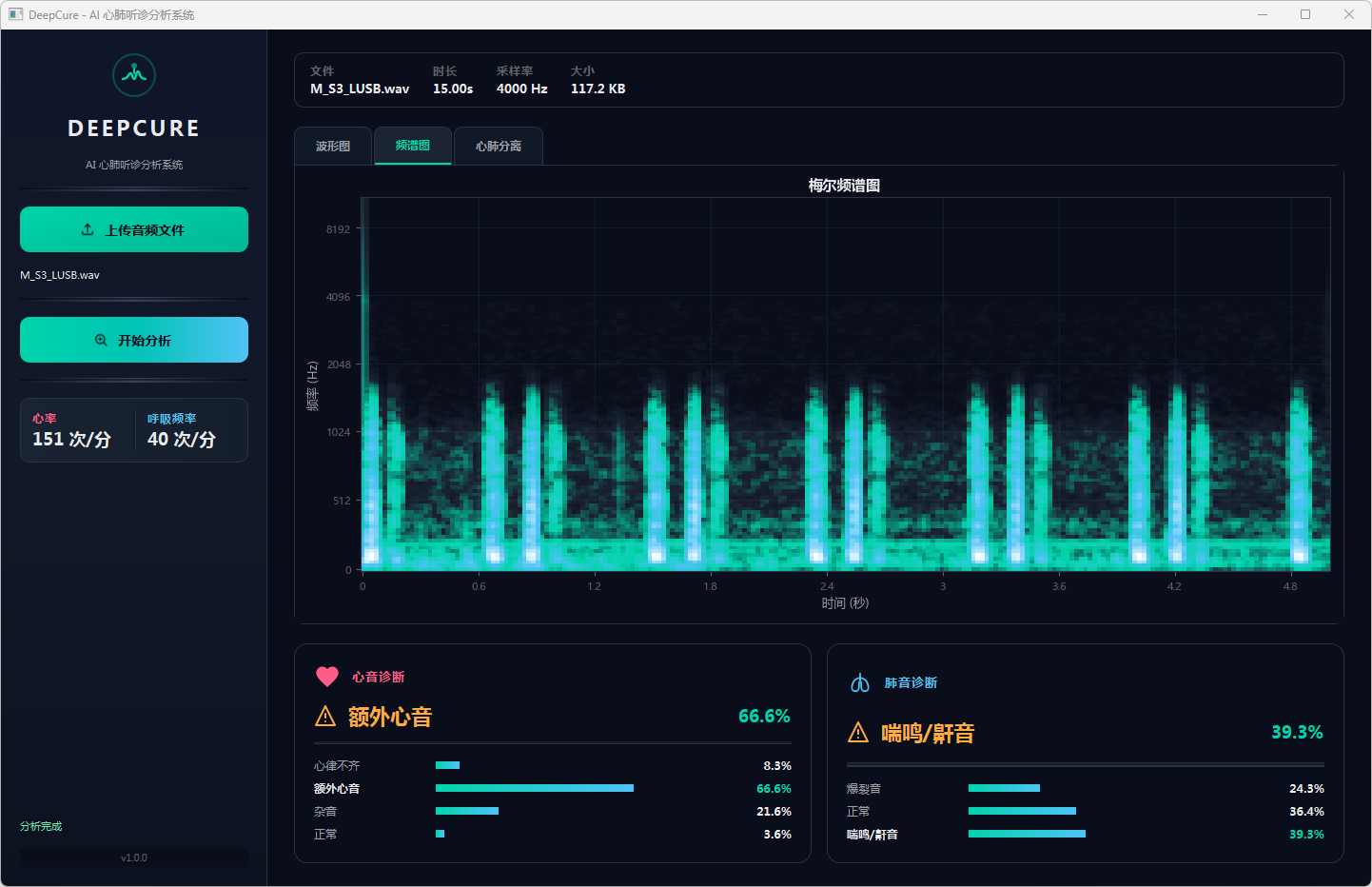
图10 心音诊断:额外心音 & 肺音诊断:喘鸣/鼾音 频谱图
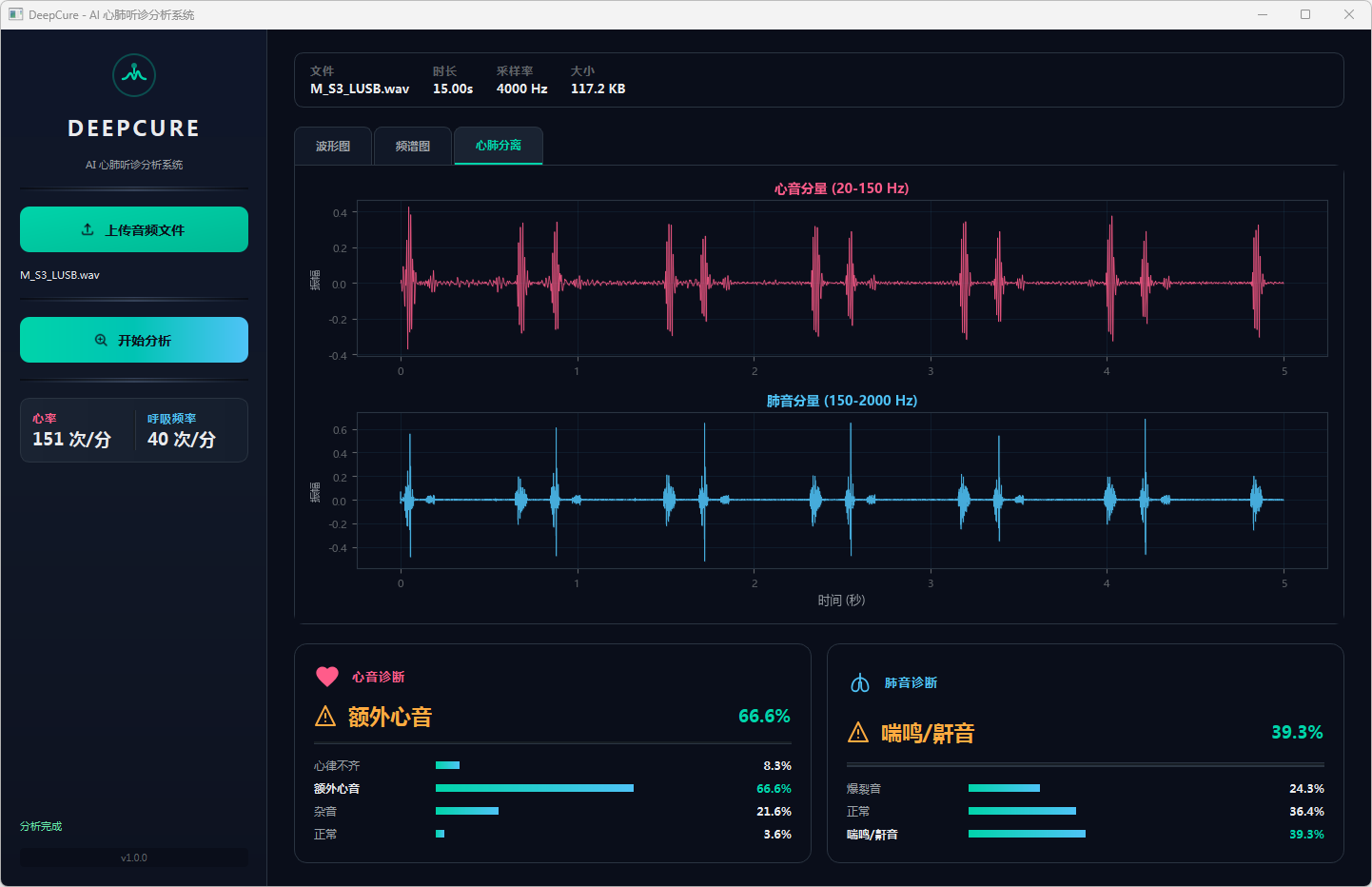
图11 心音诊断:额外心音 & 肺音诊断:喘鸣/鼾音 心肺分离
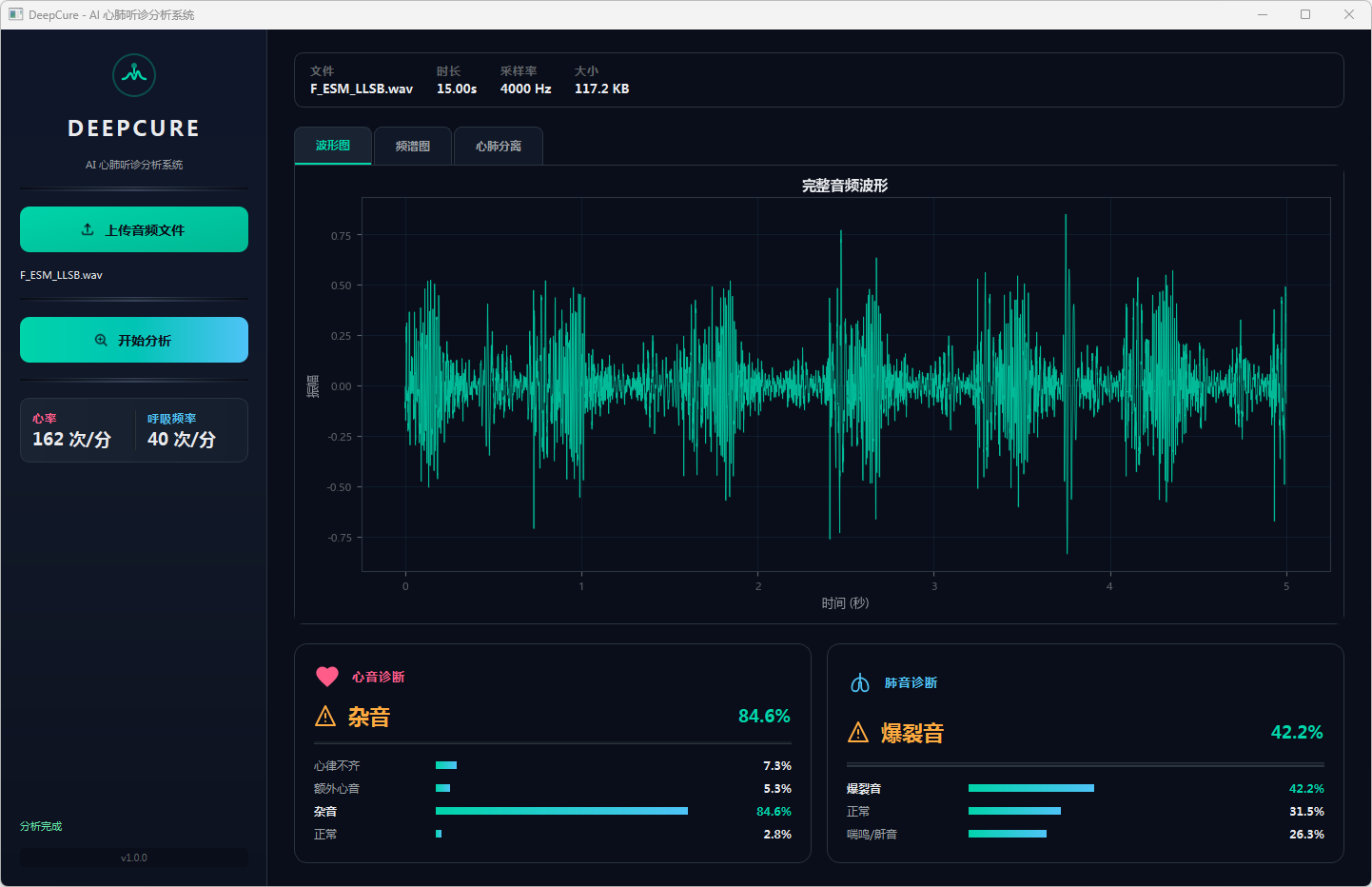
图12 心音诊断:杂音 & 肺音诊断:爆裂音 波形图
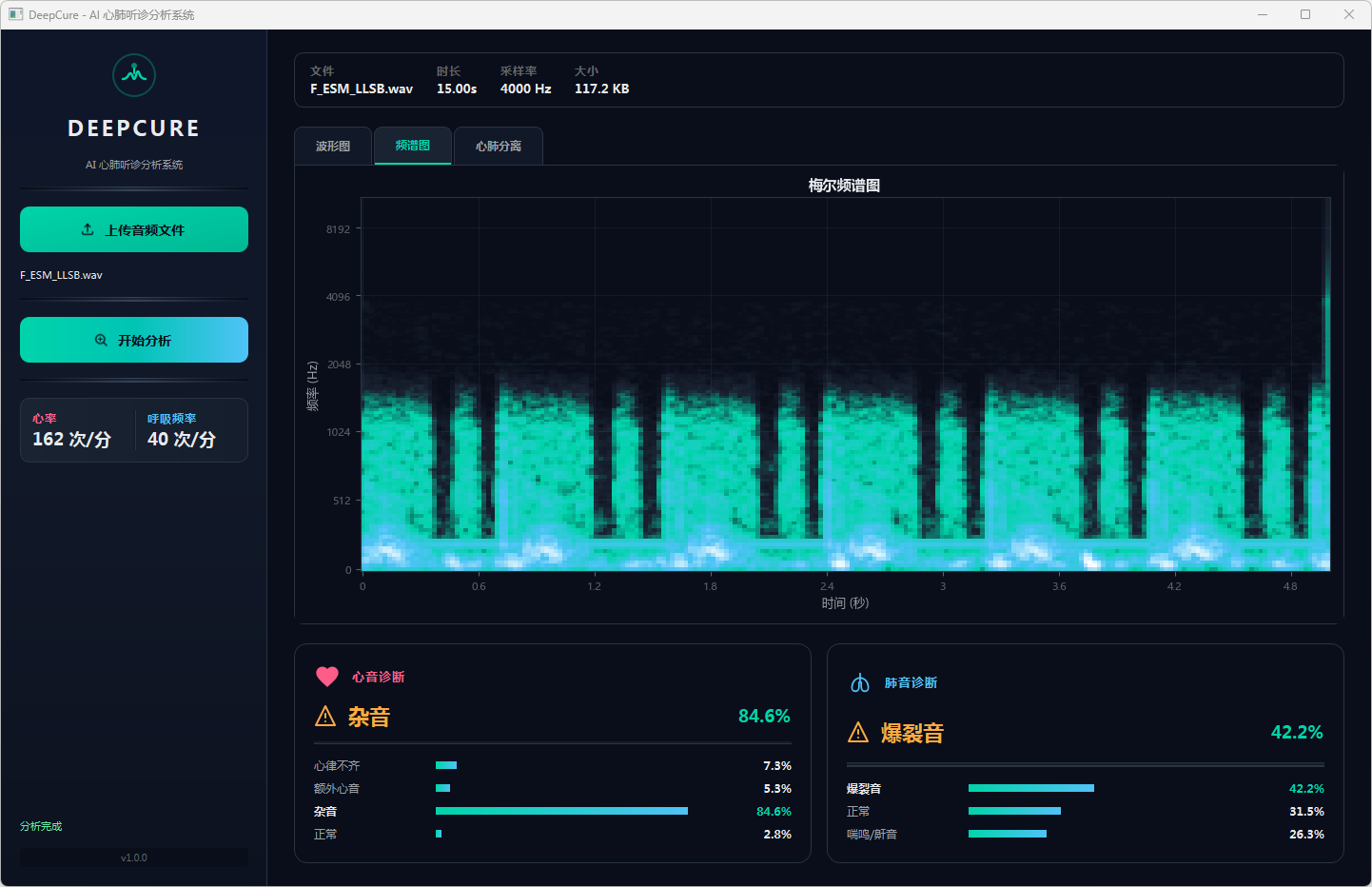
图13 心音诊断:杂音 & 肺音诊断:爆裂音 频谱图
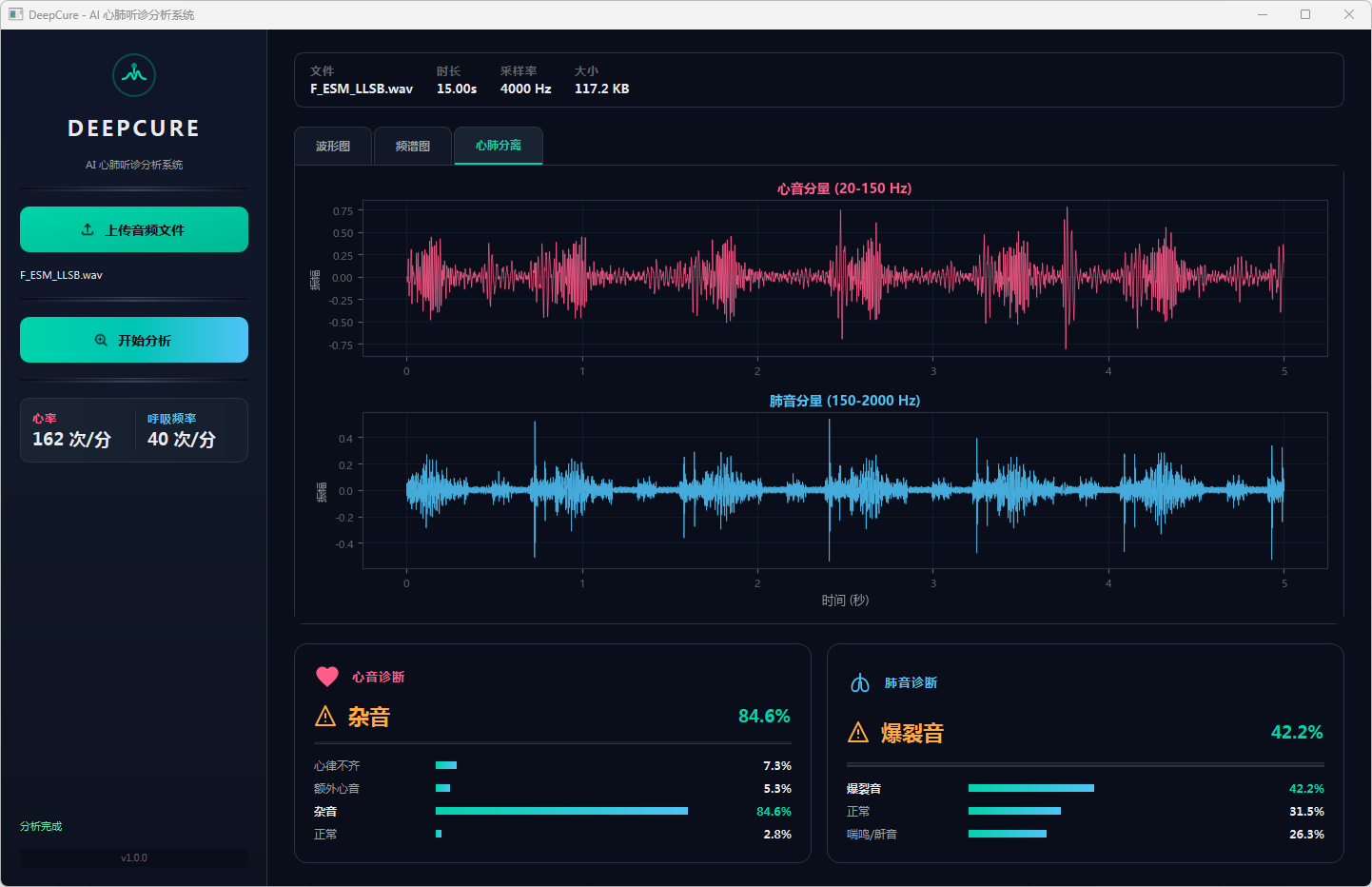
图14 心音诊断:杂音 & 肺音诊断:爆裂音 心肺分离
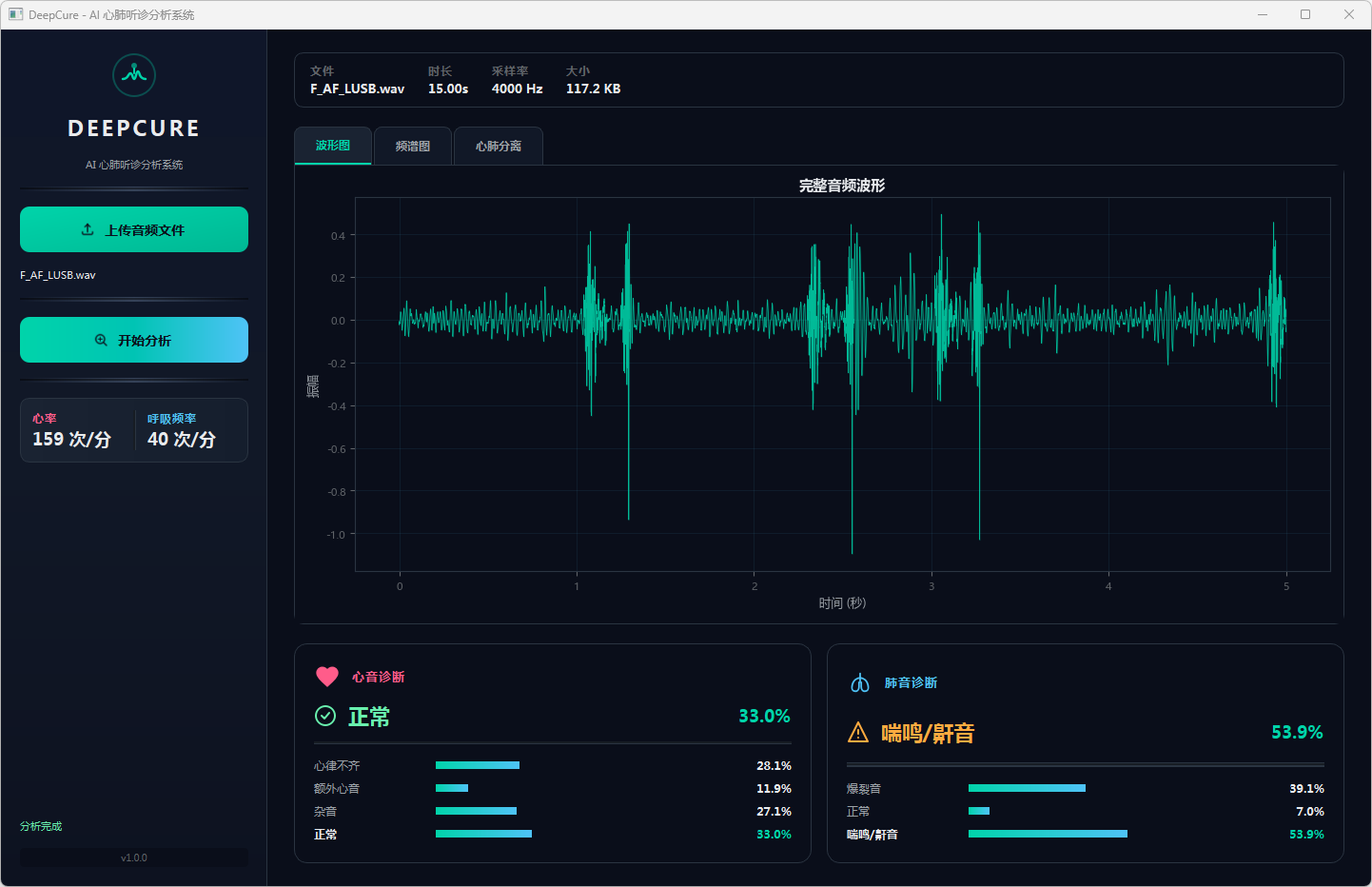
图15 心音诊断:正常 & 肺音诊断:喘鸣/鼾音 波形图
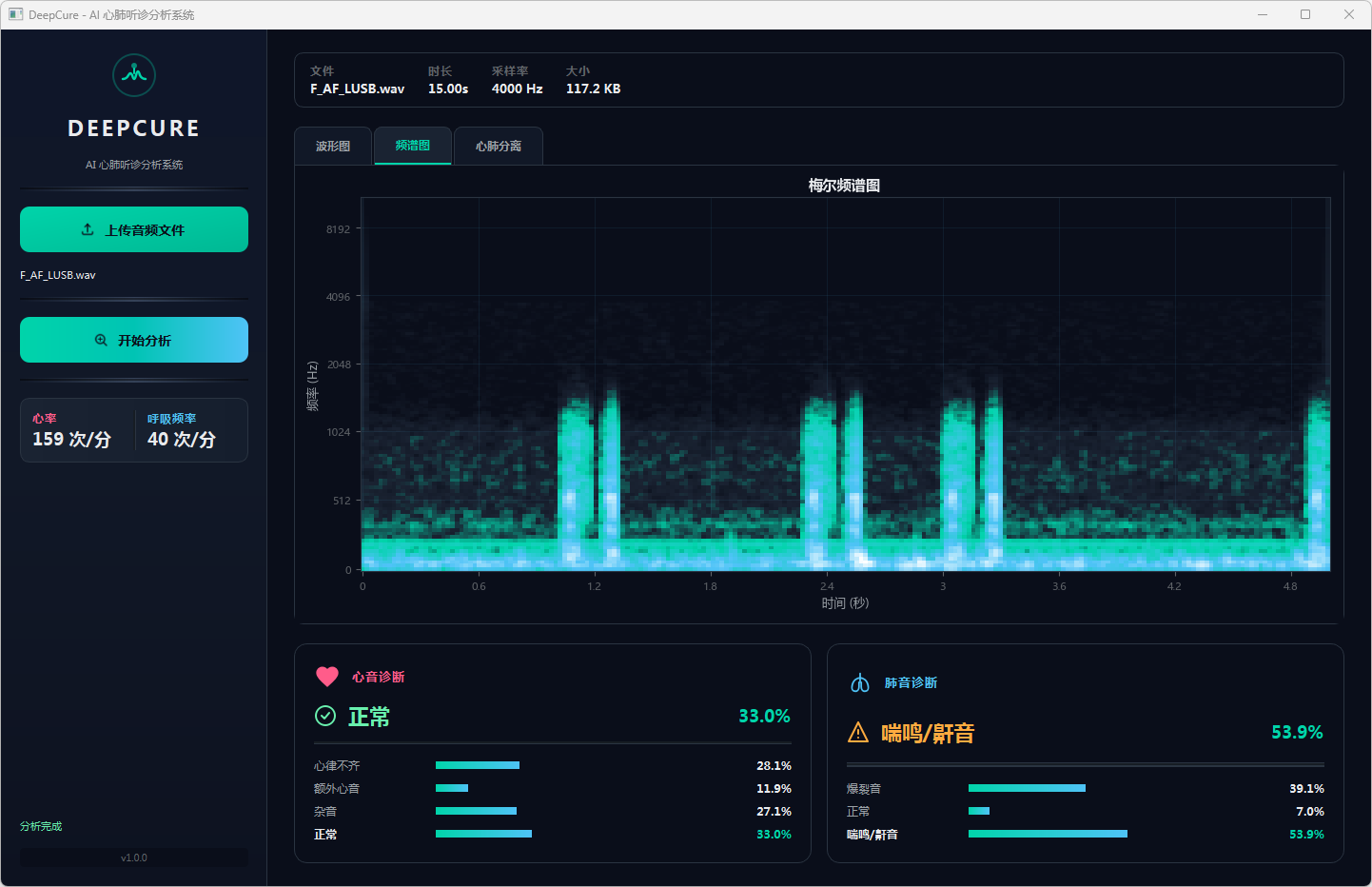
图16 心音诊断:正常 & 肺音诊断:喘鸣/鼾音 频谱图
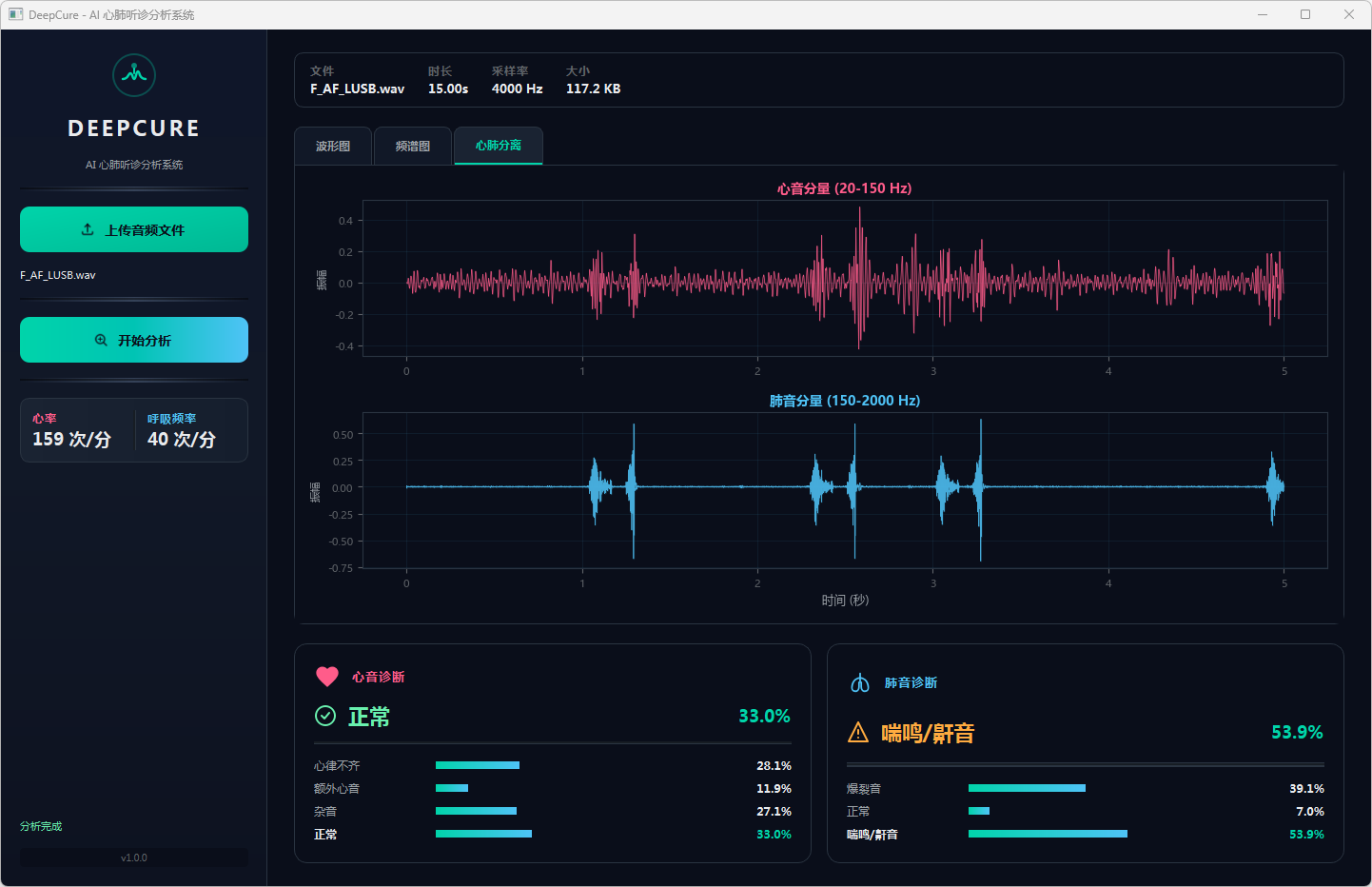
图17 心音诊断:正常 & 肺音诊断:喘鸣/鼾音 心肺分离
结果点评
系统整体分类效果良好,但受限于数据集规模较小(心音51例、肺音51例、混合录音146例),模型在测试集上可能出现过拟合倾向,尤其当测试准确率接近100%时需谨慎解读。肺音分类中爆裂音与喘鸣/鼾音的区分难度较高,置信度差距较小,说明两类异常肺音在频谱特征上存在一定重叠。后续可通过扩充数据集规模、引入更多临床录音来源以及采用更深层的特征表示方法进一步提升模型的鲁棒──和临床适用性。
项目资源
包括完整的项目源代码、演示视频、运行截图,开箱即用。

关于项目
本项目是一套面向临床辅助诊断的心肺听诊音自动分类系统,通过分析听诊录音自动识别心音异常(杂音、心律不齐、额外心音)和肺音异常(爆裂音、喘鸣/鼾音),旨在降低传统听诊对医生主观经验的依赖,为基层医疗机构提供快速、客观的心肺疾病初筛工具。
项目背景
心肺听诊是临床诊断心血管及呼吸系统疾病中最基础、最常用的检查手段之一,但传统的人工听诊高度依赖医生的临床经验和主观判断,不同医生对同一段听诊音的解读往往存在差异,且在基层医疗机构中,经验丰富的专科医生相对匮乏。随着数字听诊器的普及以及机器学习技术的发展,利用计算机对心肺听诊音进行自动分析与分类成为可能。基于此,本项目采用集成学习方法,构建了一套心肺听诊音自动分类系统,旨在为心肺疾病的计算机辅助诊断提供技术支持,从而辅助医生提高诊断效率与诊断结果的一致性。
作者信息
作者:Bob (张家梁)
项目编号:YD-3
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)