
摘要:呼吸系统疾病是全球主要的健康威胁之一。肺部听诊作为临床诊断中的重要手段,其结果高度依赖医生的主观经验,难以实现标准化与自动化。因此,利用深度学习技术对肺部听诊声音进行智能分析,辅助临床医生快速、准确地识别呼吸系统疾病,具有重要的研究意义和实际应用价值。
项目简介
本系统基于PySide6开发桌面GUI,利用librosa提取肺部听诊音频的MFCC特征并重塑为46×46×3的特征图,通过自定义的两层卷积神经──络LungSoundCNN实现哮喘、支气管扩张、细支气管炎、COPD、健康、下呼吸道感染、肺炎、上呼吸道感染共8类呼吸疾病的分类诊断。
系统概述
呼吸系统疾病是全球主要的健康威胁之一。肺部听诊作为临床诊断中的重要手段,其结果高度依赖医生的主观经验,难以实现标准化与自动化。因此,利用深度学习技术对肺部听诊声音进行智能分析,辅助临床医生快速、准确地识别呼吸系统疾病,具有重要的研究意义和实际应用价值。
本文设计并实现了一种基于卷积神经网络(CNN)的呼吸疾病分类系统。系统以226例患者的肺部听诊音频为数据基础,涵盖哮喘、支气管扩张、细支气管炎、慢性阻塞性肺病、健康、下呼吸道感染、肺炎和上呼吸道感染共8个类别。首先利用 librosa 库提取音频的梅尔频率倒谱系数(MFCC)特征,并将其重塑为 46×46×3 的特征图作为网络输入;随后构建了一种轻量级 CNN 模型(LungSoundCNN),模型包含两层卷积层、两层最大池化层和两层全连接层,采用 Adam 优化器和交叉熵损失函数进行 50 轮迭代训练。
在系统实现方面,基于 PySide6 框架开发了桌面端图形用户界面,集成数据加载、特征提取、模型训练、训练过程可视化和实时诊断五个功能模块。实验结果表明,该模型能够有效区分上述 8 类呼吸系统疾病,用户仅需上传肺部声音音频文件,系统即可自动输出疾病分类结果及相应置信度。整体系统操作流程清晰、界面友好,具有一定的临床辅助诊断应用潜力。
系统架构
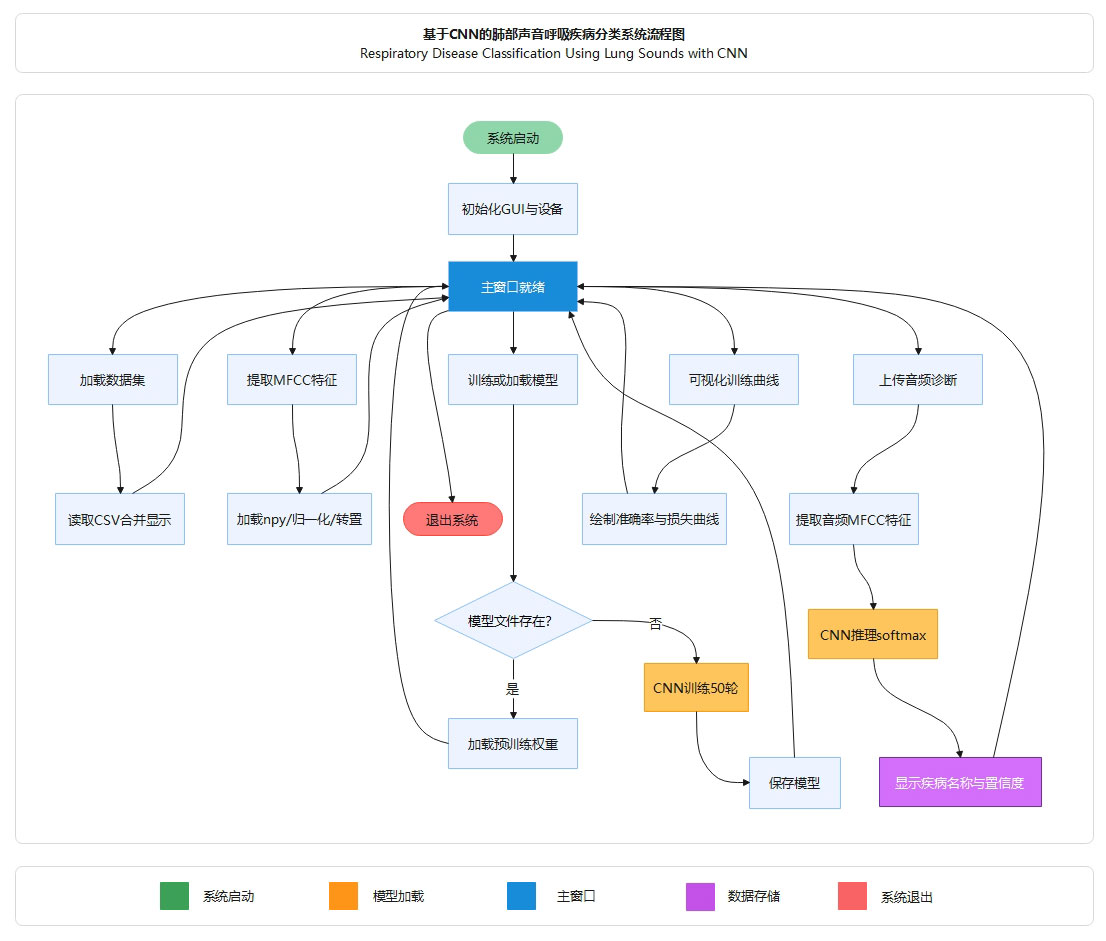
系统启动并初始化GUI后,用户依次执行加载CSV数据集、提取MFCC特征、训练或加载CNN模型、可视化训练曲线、上传WAV音频进行疾──诊断五个步骤,每步完成后返回主窗口等待下一步操作,最终退出系统。
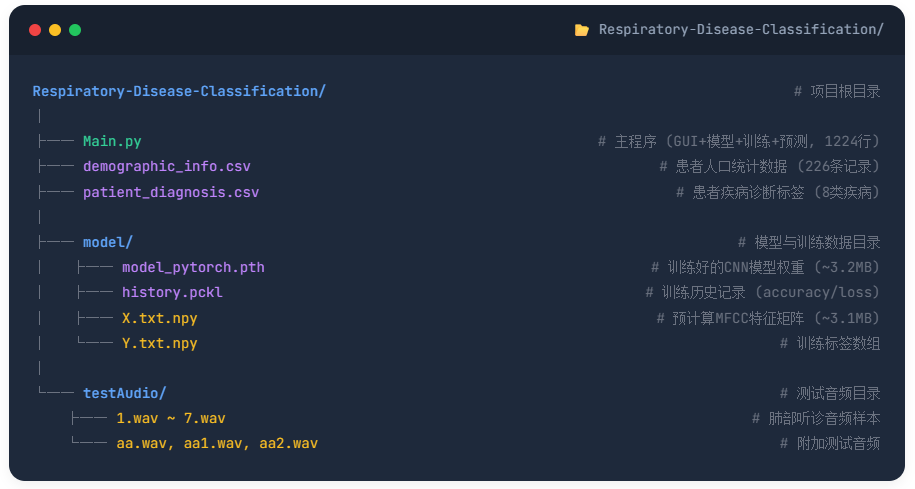
项目结构
系统启动并初始化GUI后,用户依次执行加载项目采用单文件架构,核心代码全部集中在Main.py,包含LungSoundCNN模型类、TrainThread训练线程类和MainWindow主──口类,配合model目录存放预训练权重及特征数据、testAudio目录存放测试音频、以及两个CSV患者数据文件。CSV数据集、提取MFCC特征、训练或加载CNN模型、可视化训练曲线、上传WAV音频进行疾──诊断五个步骤,每步完成后返回主窗口等待下一步操作,最终退出系统。
目录结构
核心模块
本系统包含六个核心模块:数据加载模块通过pandas读取两个CSV文件并按PATIENT_ID合并展示226条患者记录;特征提取模块加载预──算的MFCC特征矩阵(X.txt.npy),经归一化、打乱和转置处理为(N,3,46,46)格式;模型构建模块定义LungSoundCNN网络,包含两层Conv2d+ReLU+MaxPool2d卷积层和Linear(3200→256→8)全连接层;训练模块基于QThread异步执行,采用Adam优化器和CrossEntropyLoss训练50轮;可视化模块通过matplotlib绘制准确率和损失曲线;预测模块使用librosa提取音频MFCC特征,经reshape为46×46×3特征图后送入模型,通过softmax输出8类疾病的分类结果与置信度。
快速开始
安装Python 3.8+环境后,在命令行执行python Main.py启动系统,依次点击左侧控制面板的”加载数据集”(选择项目根目录)→”提取声学特征”→”训练/加载模型”→”可视化训练曲线”→”上传音频诊断”(选择testAudio目录下的WAV文件)即可完成从数据加载到疾病诊断的完整流程。
环境要求
本系统需 Python 3.8+ 环境,核心依赖包括 PySide6(GUI)、PyTorch(模型构建与训练)、librosa(音频与 MFCC 特征)、NumPy(数组与数据处理)、Pandas(CSV 数据处理)、matplotlib(训练曲线可视化),支持 CPU 运行,若有 NVIDIA GPU 可自动启用 CUDA 加速训练与推理。
运行实验
启动系统后,依次点击“加载数据集”选择项目根目录,系统读取并合并 CSV 文件显示 226 条患者记录;点击“提取声学特征”加载并预处理 MFCC 矩阵;点击“训练/加载模型”,若已有 model_pytorch.pth 则加载权重,否则异步训练 50 轮并保存模型;点击“可视化训练曲线”查看准确率与损失变化;最后点击“上传音频诊断”选择 WAV 文件,系统提取 MFCC 特征并经 CNN 推理输出病分类、置信度及 Top5 类别概率分布。
查看结果
模型训练或加载完成后,点击“可视化训练曲线”查看 50 轮训练的准确率与损失变化;点击“上传音频诊断”选择 WAV 文件后,系统在日志区显示音频采样率和时长,并输出诊断结果卡片(疾病名称及置信度)及 Top5 类概率柱状图,其中健康结果以绿色、疾病结果以黄色标识。
实验结果
实验结果表明,LungSoundCNN 经 50 轮训练后可有效区分哮喘、支气管扩张、细支气管炎、COPD、健康、下呼吸道感染、肺炎及呼吸道感染 8 类疾病,系统能对用户上传的肺部听诊音频实时输出分类结果及置信度。
识别效果
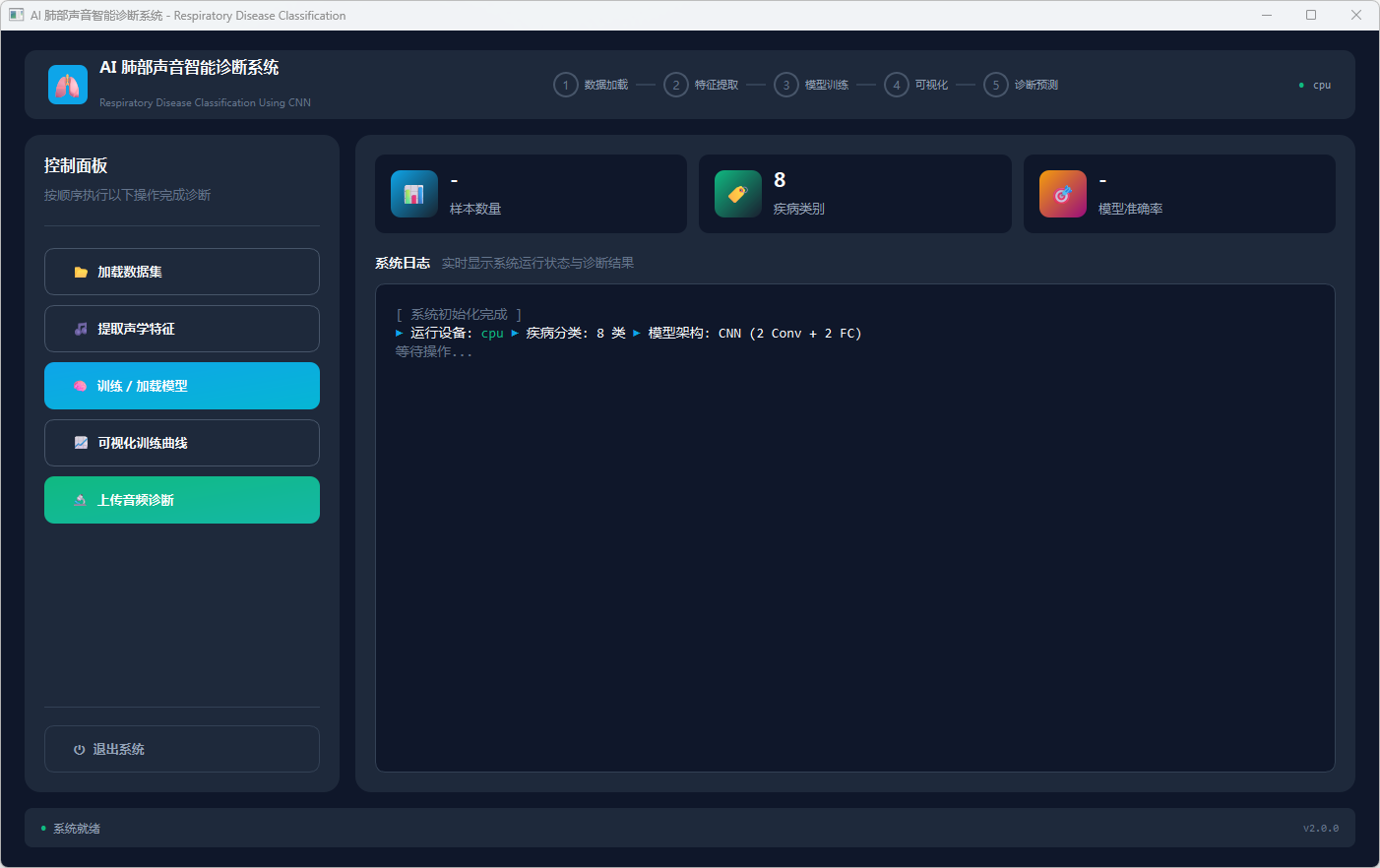
图1 系统界面
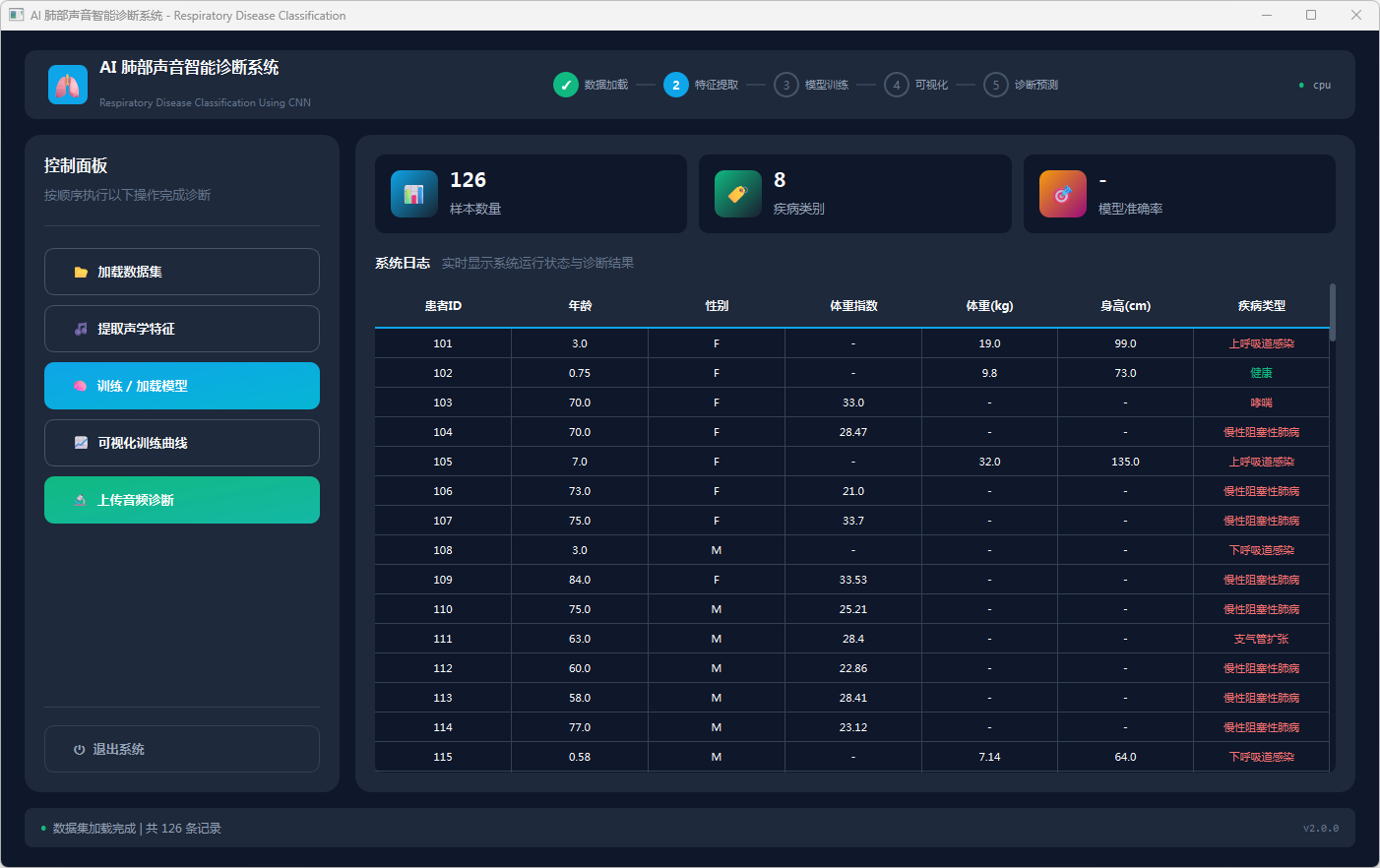
图2 加载数据集
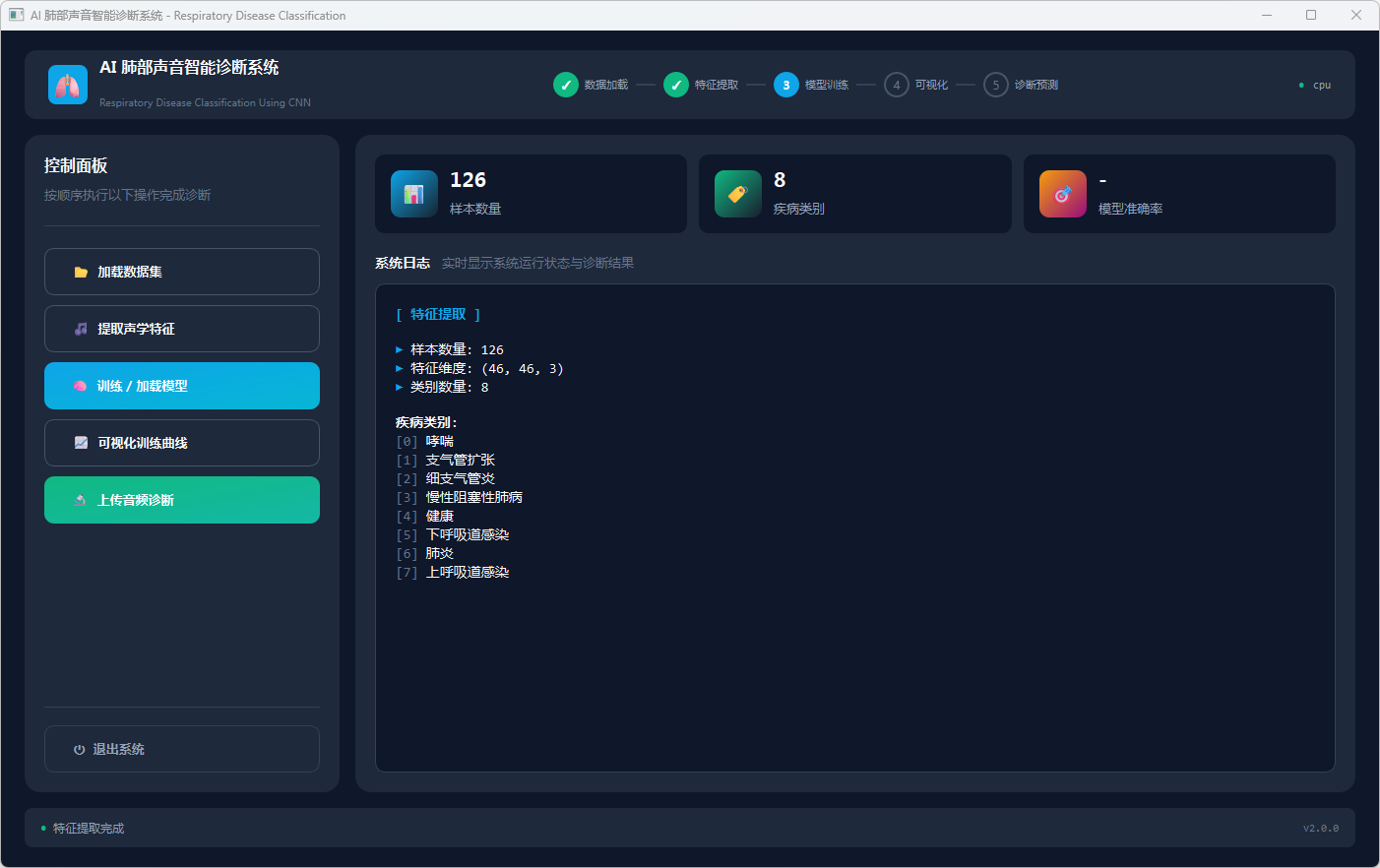
图3 提取声学特征
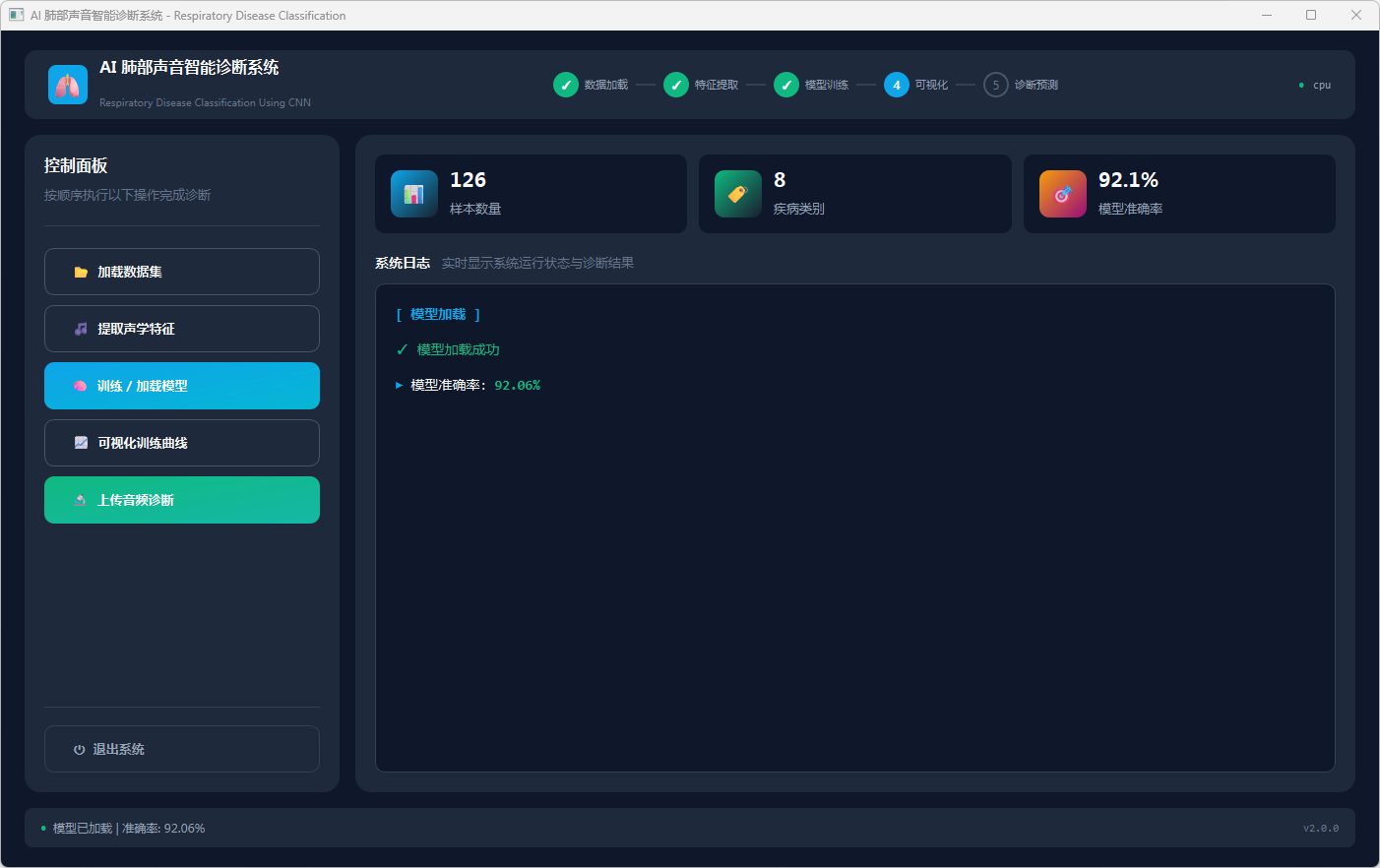
图4 训练和加载模型
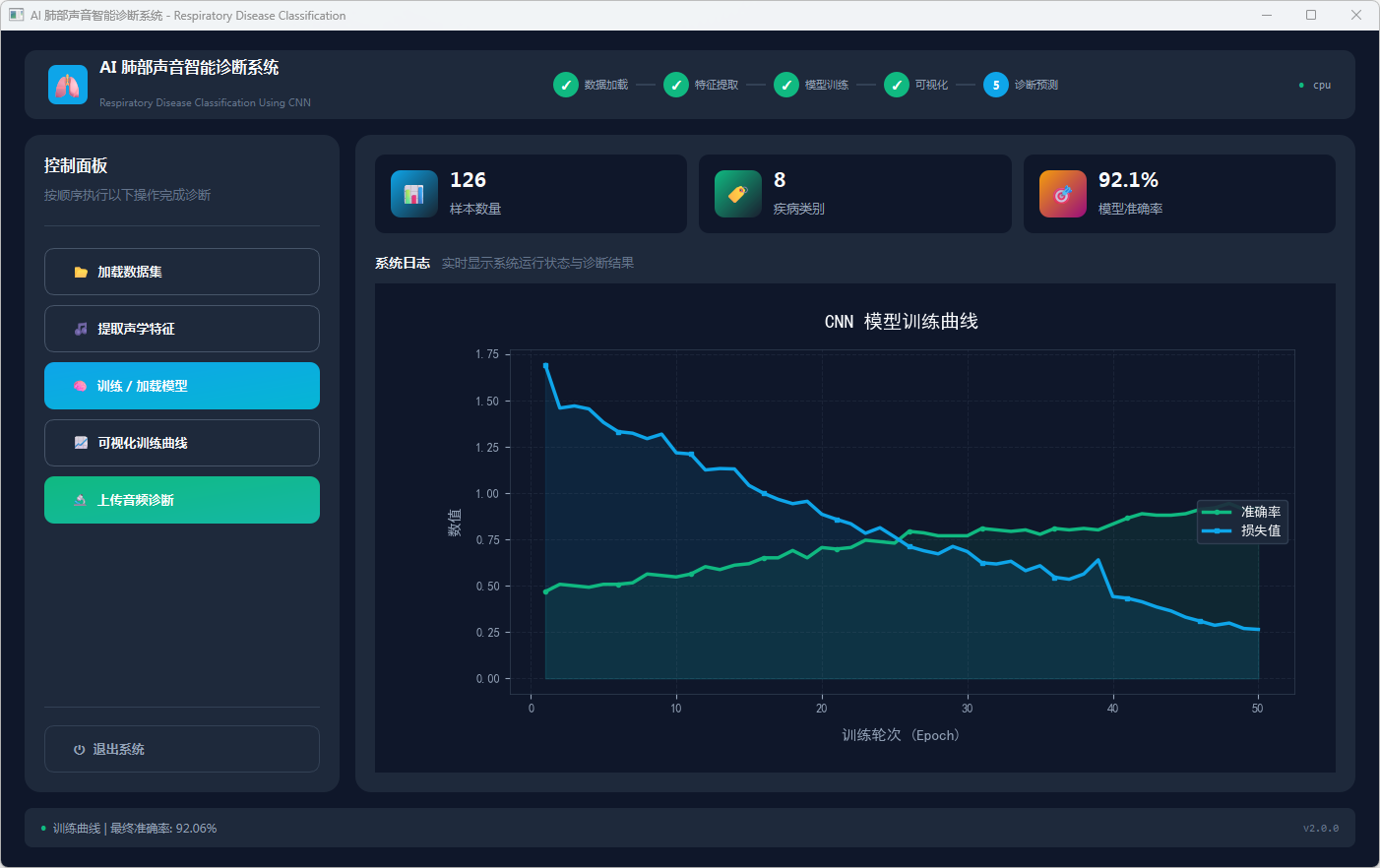
图5 可视化训练曲线
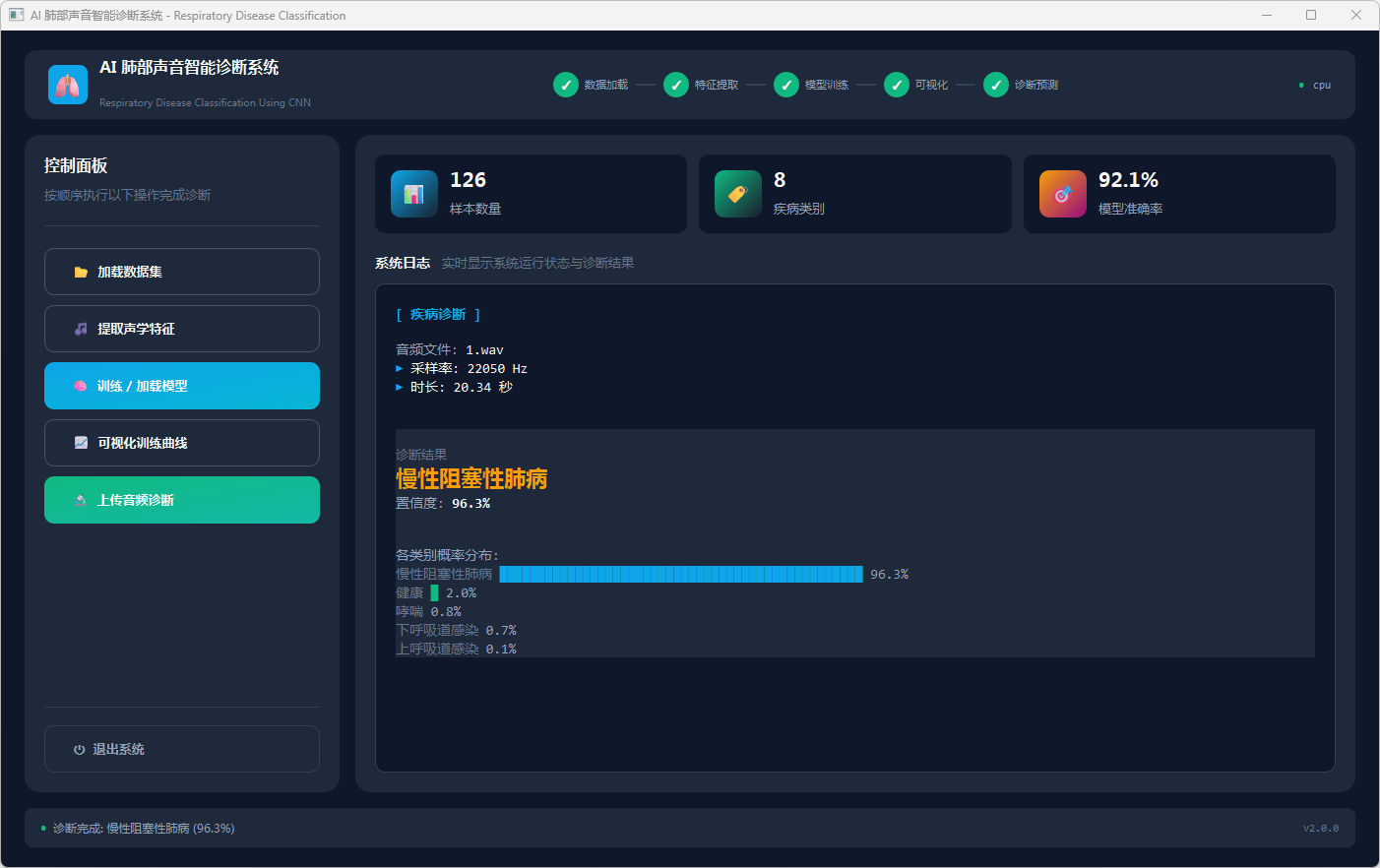
图6 慢性阻塞性肺病
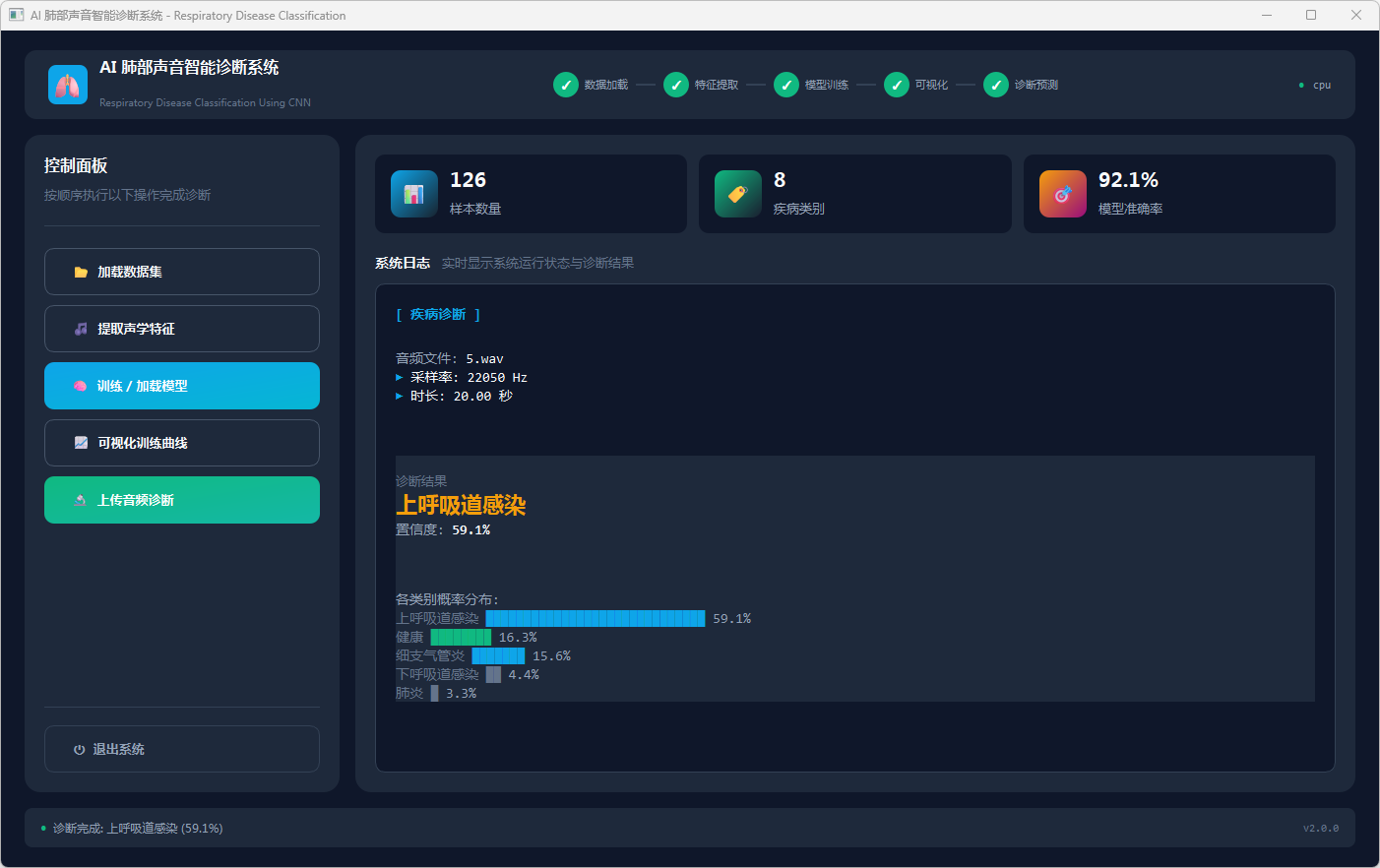
图7 听音:上呼吸道感染
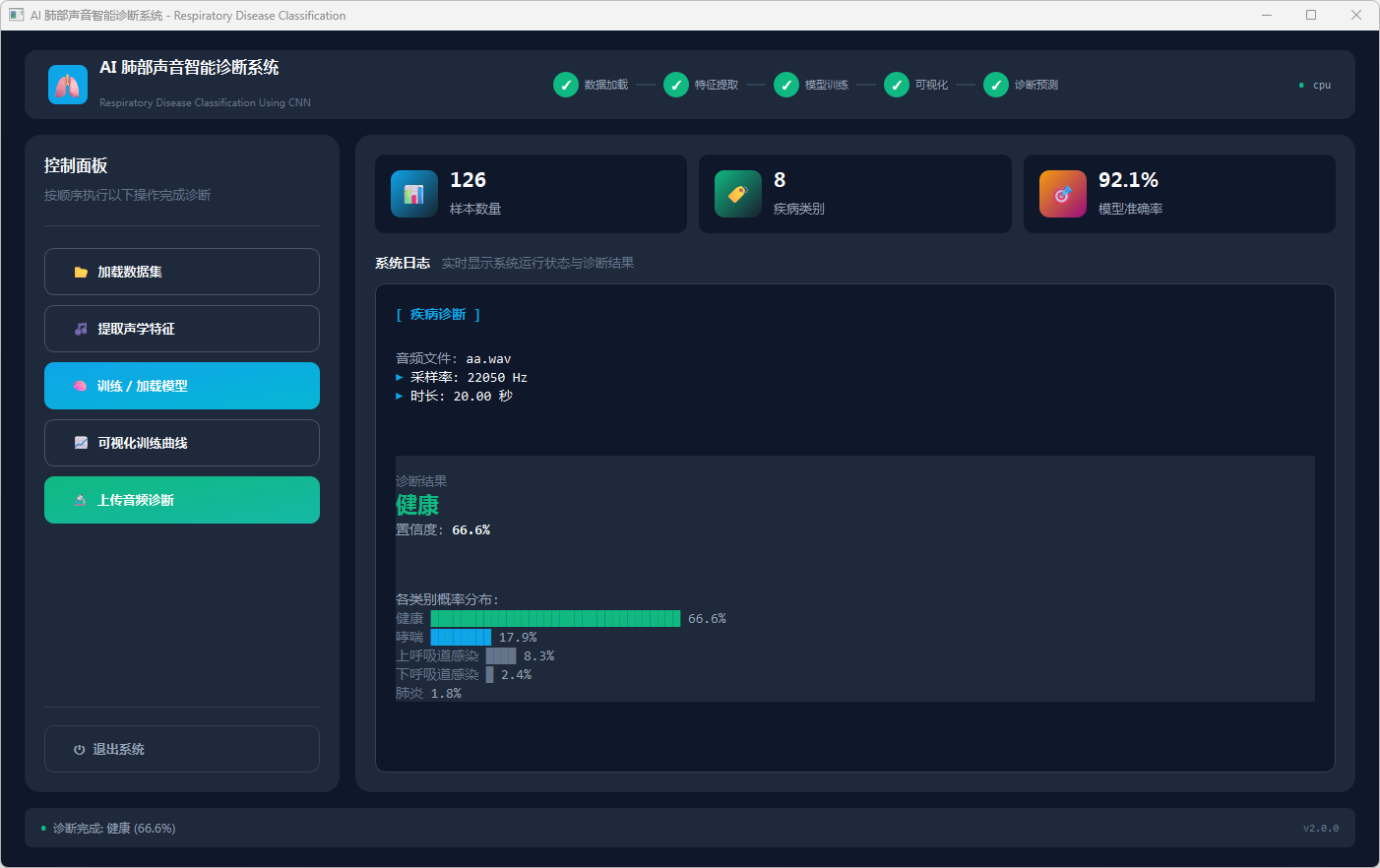
图8 听音:健康
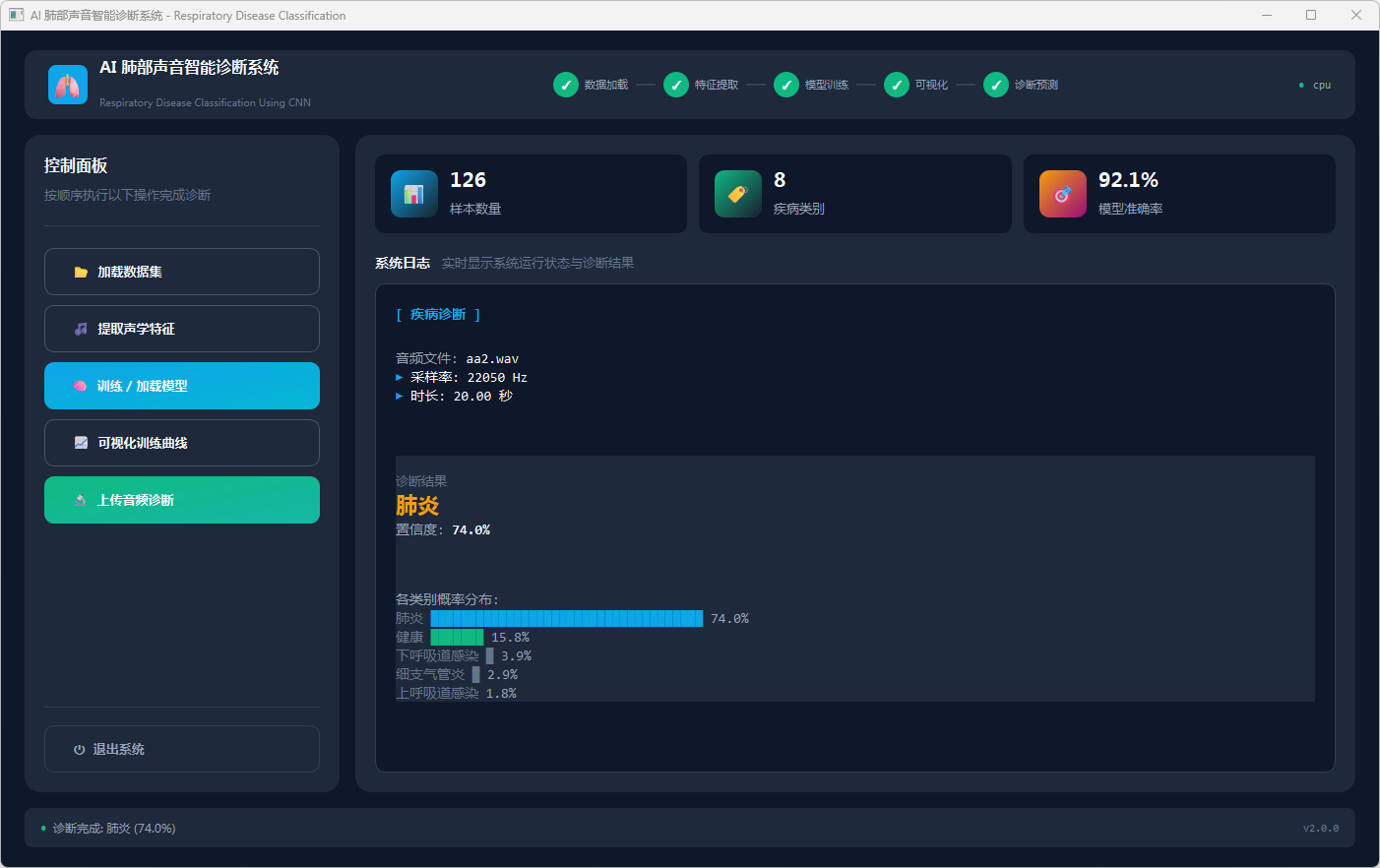
图9 听音:肺炎
结果点评
本系统采用轻量级两层卷积的 LungSoundCNN,结构简洁、训练速度快,适合作为呼吸疾病辅助筛查工具;但未使用 Dropout 或数据增强,仅依赖预计算 MFCC 特征,在样本量有限(226 例)情况下可能过拟合,且缺少训练/测试划分评估,无法量化泛化能力。后续可引入交叉验证、混淆矩阵分析及更深层网络以提升分类性能和临床可靠性。
项目资源
包括完整的项目源代码、演示视频、运行截图,开箱即用。

关于项目
本项目基于卷积神经网络,通过分析肺部听诊音频的 MFCC 特征自动识别 8 类呼吸疾病,可辅助临床医生进行快速初步筛查与诊断。
项目背景
呼吸系统疾病是全球主要健康威胁,传统肺部听诊依赖医生经验且难以标准化,本项目通过卷积神经网络自动学习肺部声音 MFCC 特征,实现呼吸疾病的计算机辅助诊断。
作者信息
作者:Bob (张家梁)
项目编号:YP-2
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)