

摘要:本研究针对香梨产业园果实数量统计和产量预测中人工清点效率低、主观性强、难以满足规模化管理需求等问题,设计并实现了一套基于深度学习的香梨产量预测系统。系统以香梨图像为研究对象,融合目标检测、特征工程与回归分析方法,实现了图像检测、视频检测、实时检测及产量预测等功能。
数据集简介
本数据集为香梨目标检测数据集,共包含 2788 张图像和 33296 个标注框,涵盖训练集、验证集和测试集,可用于香梨果实检测模型的训练与评估。
数据集概述
本研究围绕香梨产业园果实数量统计与产量预测需求,设计并实现了一套基于深度学习的香梨产量预测系统。传统人工清点和经验估产方式存在效率低、主观性强、难以适应大规模果园管理等问题,因此有必要引入计算机视觉与机器学习方法,提高果实识别与产量估算的自动化和智能化水平。本文以香梨图像为研究对象,结合目标检测、特征工程和回归分析,构建了一个集图像检测、视频检测、实时检测和产量预测于一体的可视化系统。
在方法上,系统采用 YOLO12 目标检测模型对香梨果实进行识别与计数,并提取果实数量、检测置信度、检测框面积、果实密度、重叠率、空间分布均匀度和估算总重量等特征 。在此基础上,构建线性回归、随机森林回归和梯度提升回归等产量预测模型,通过性能对比选取最优模型用于产量估算。同时,引入基于规则的估算方法作为补充,以提高系 统在不同场景下的适用性。系统基于 Python 开发,并结合 PyQt 实现图形化界面。
实验结果表明,该系统能够较为准确地完成香梨目标检测、数量统计和产量预测任务,实现从图像输入到结果输出的完整流程。相比传统人工估产方法,本文方法在自动化程度、处理效率和结果一致性方面具有一定优势。研究结果表明,深度学习与机器学习技术在果园智能管理和农业信息化应用中具有较好的应用价值,可为香梨产量预测及相关果树智能监测提供参考。
数据集来源
本研究所使用的数据集为香梨目标检测数据集,图像数据来源于果园场景下香梨果实图像的采集、整理与筛选,并在预处理后形成 适用于目标检测任务的数据集。所有图像均采用 YOLO 格式进行边界框标注,目标类别定义为香梨(pear),共计标注 33296 个实例。整个标注过程遵循统一规范,以保证数据标注的一致性和准确性,为后续 YOLO12 模型训练、性能评估以及系统应用提供了可靠的数据支撑。
类别定义
标注规范
标注采用 YOLO 格式:每个目标一行,字段为 class x_center y_center width height, 坐标均为相对归一化(0~1)。
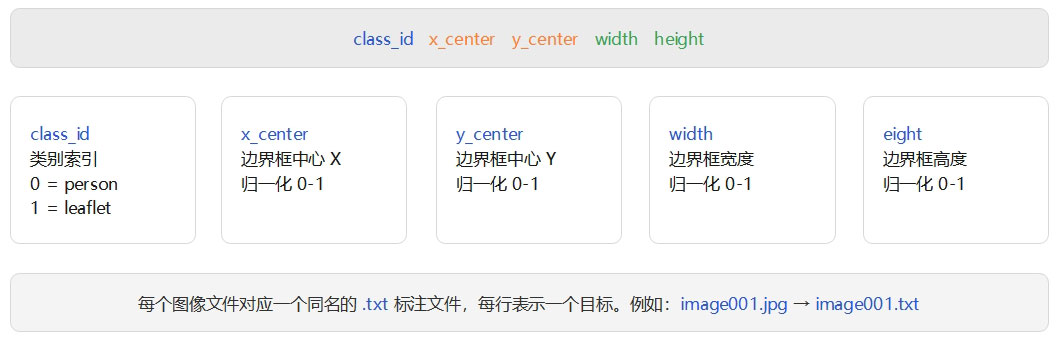
图1 标注规范图
数据规模与划分
- 总图像数:2,788张;总标注框数:33,296个
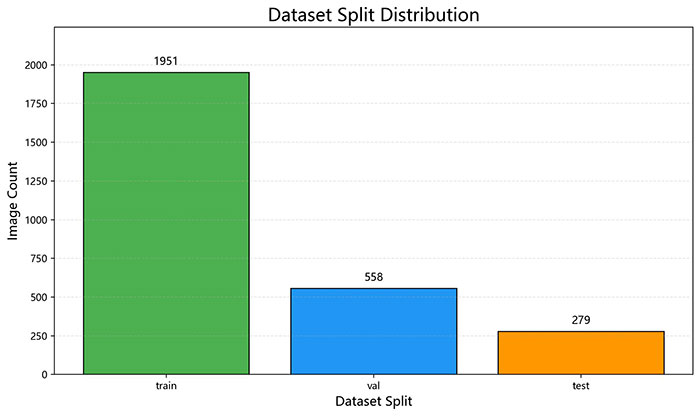
图2 数据集在训练、验证和测试集上的分布
数据集按照约 70:20:10 的比例划分为训练集、验证集和测试集:
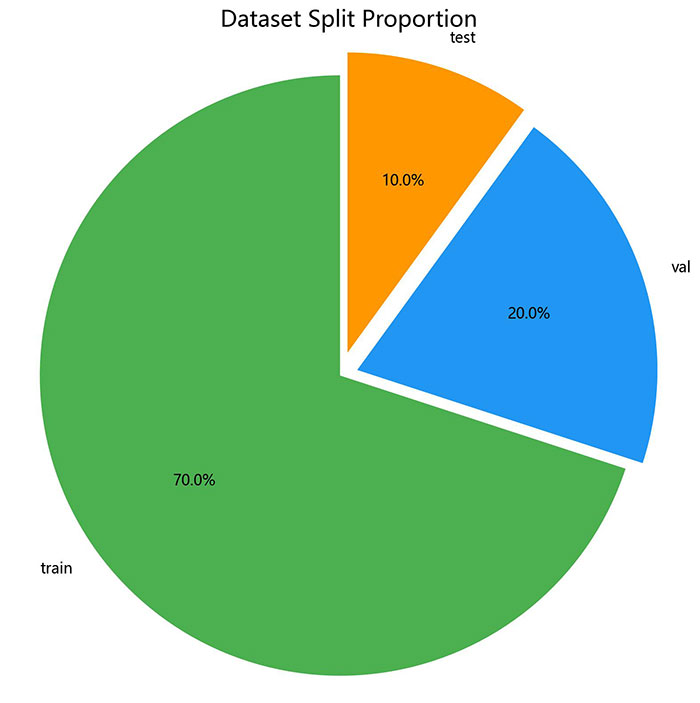
图3 数据集划分及用途说明
质量控制
标注采用双阶段质量控制流程:首先进行规范化标注与自检, 确保目标框贴合实例外接矩形且类别一致;随后进行抽样复核, 针对漏标、错标与框位置偏差进行纠正。对争议样本进行二次确认, 以提高跨标注者一致性与总体标注可靠性。
数据格式与使用
数据集采用标准 YOLO 格式组织,通过 data.yaml 配置文件即可快速集成到训练流程中。
目录结构

数据集采用标准 YOLO 格式组织,图像和标注文件分别存放在 images/ 和 labels/ 目录下,并按训练集、验证集、测试集划分。
性能评测
基于 YOLOv8 模型在本数据集上进行训练和评测,使用mAP@0.5与mAP@0.5:0.95等标准指标对模型检测效果进行评估。评测结果如下:
训练过程综合指标曲线图
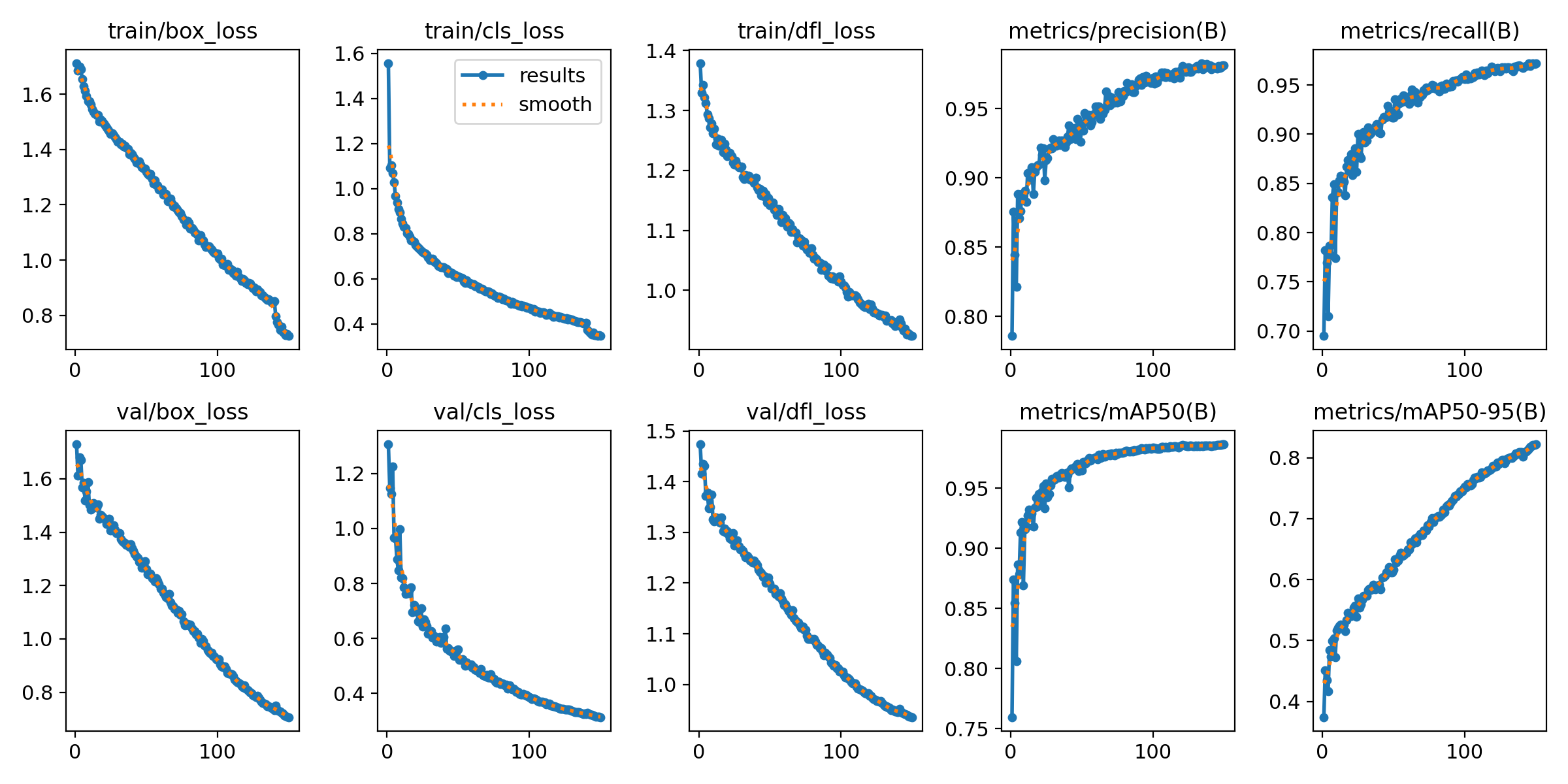
图3 训练与验证指标随Epoch变化趋势图
精确率-召回率(PR)曲线图
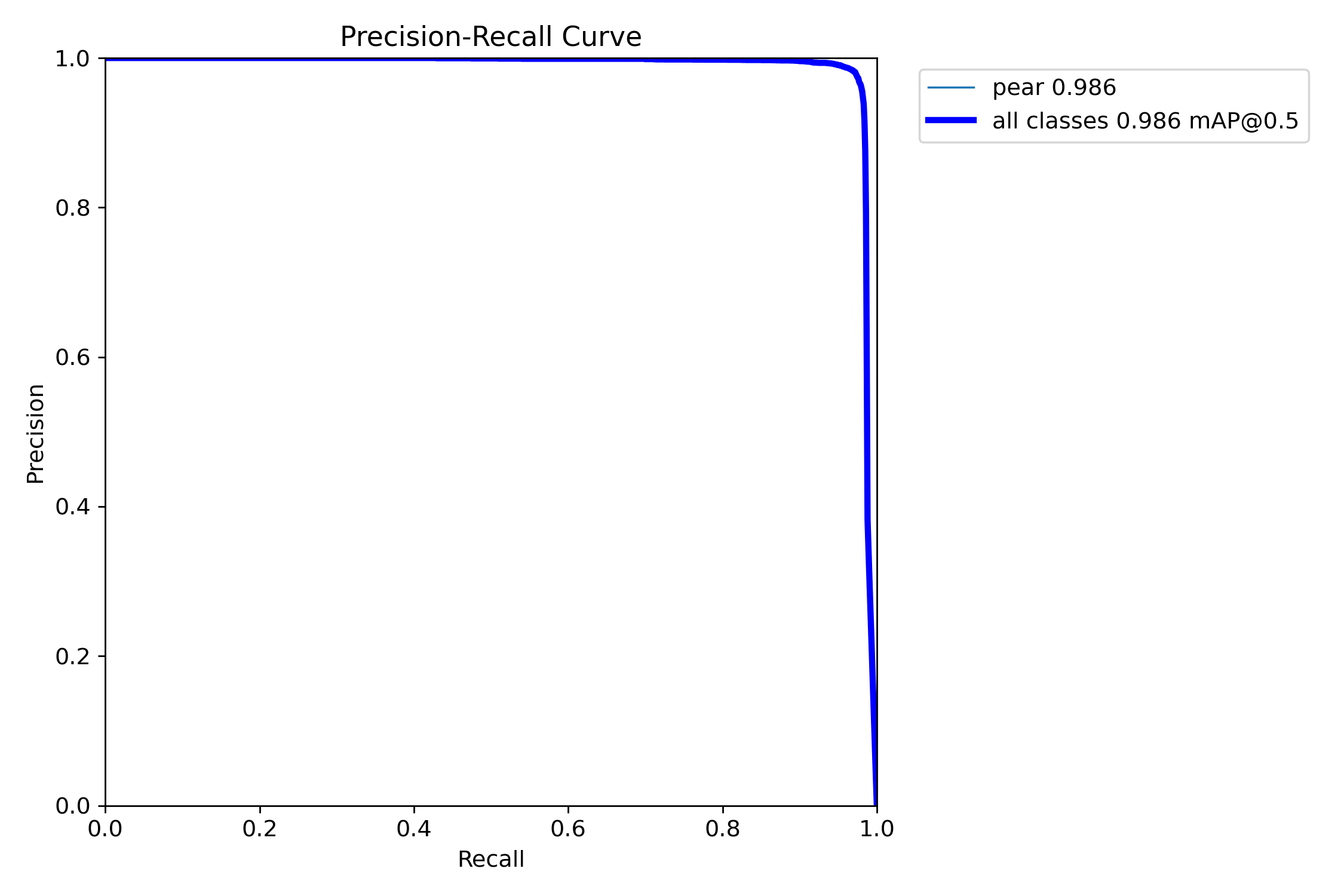
图4 目标检测PR曲线(Precision-Recall)
F1分数-置信度阈值曲线图
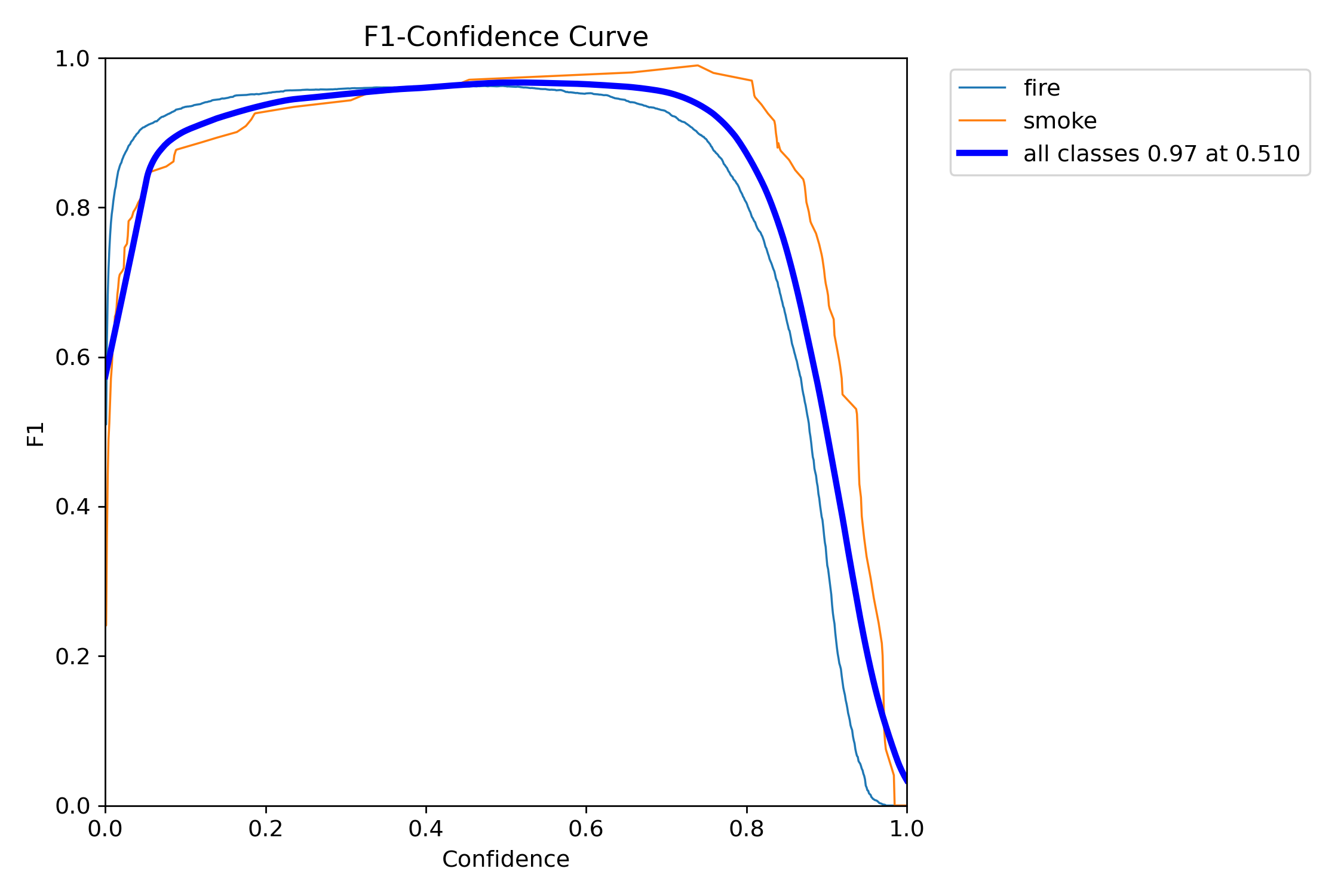
图5 不同置信度阈值下的F1曲线
归一化混淆矩阵图(分类误判分析)
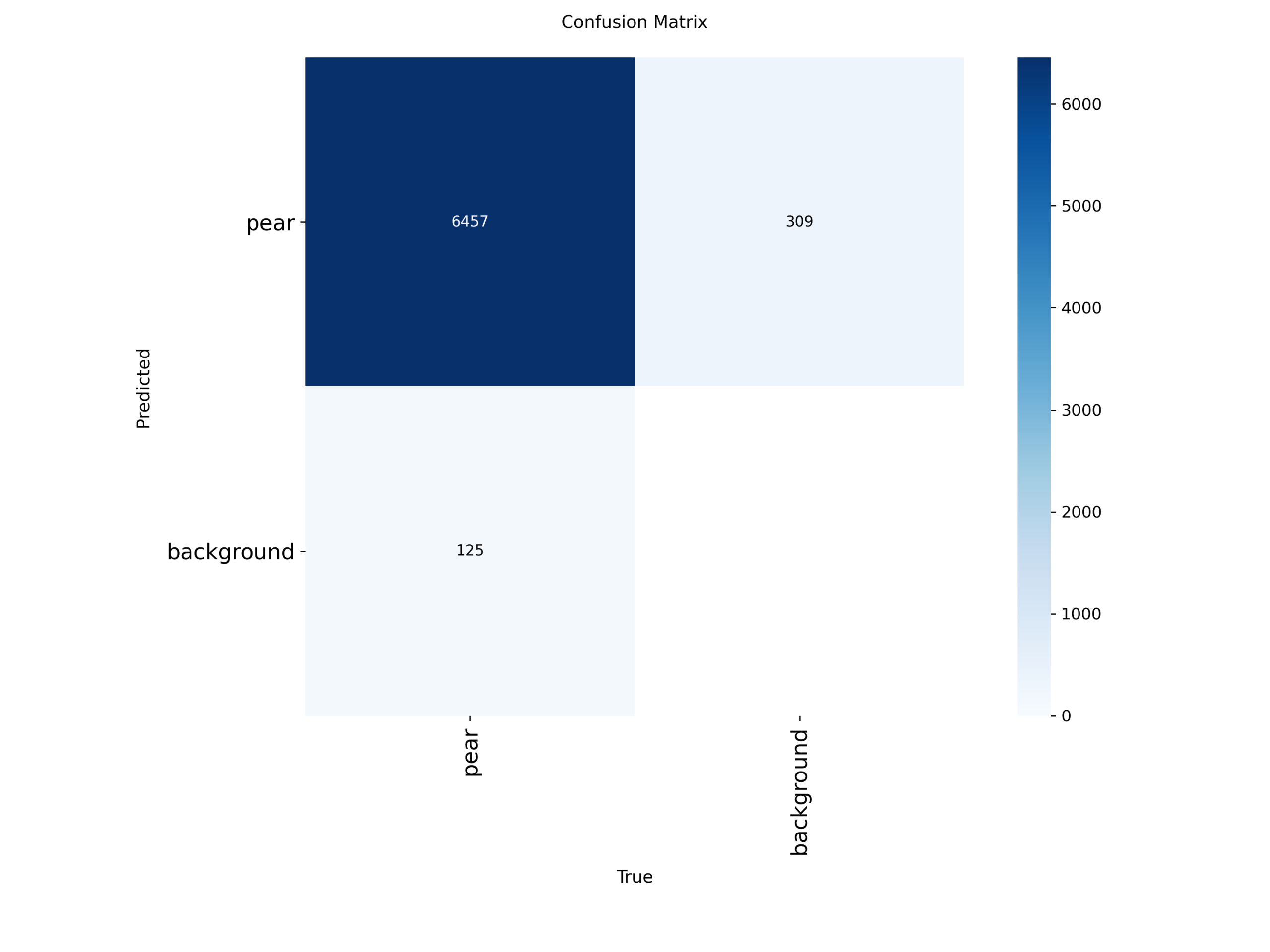
图6 归一化混淆矩阵(person / leaflet)
应用案例
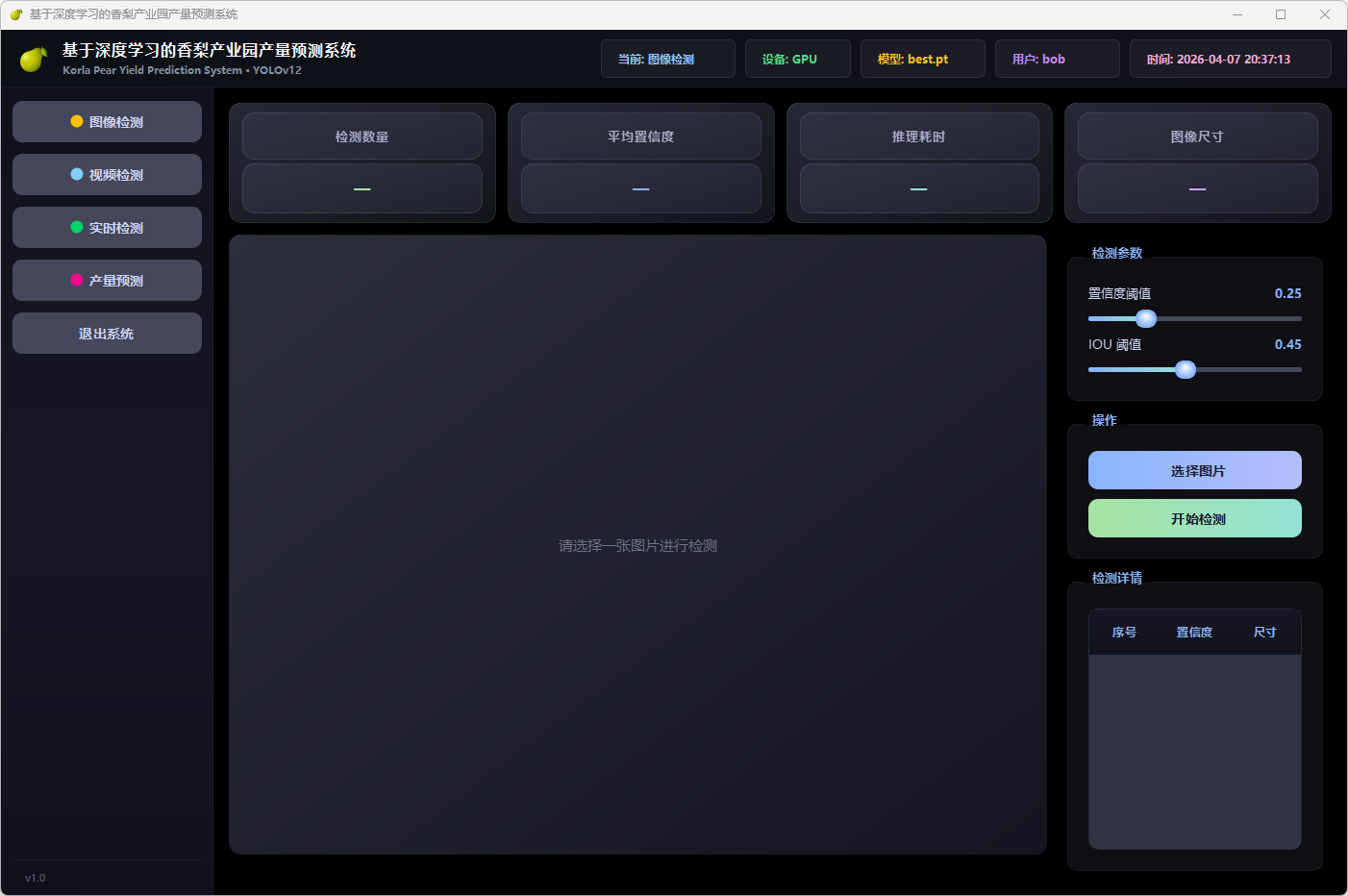
图7 应用案例:基于深度学习的香梨产量预测系统
免责声明与引用
数据仅用于科研与教学用途。若用于商业场景,请自行核验数据许可。 如需引用,请在论文或报告中注明数据集名称与版本号。
作者信息
作者:Bob (张家梁)
项目编号:Datasets-17
数据大小:461M
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)