

摘要:随着智能手机在课堂环境中的普及,学生课堂手机使用行为对教学秩序和学习效果产生了一定影响,传统人工监管方式存在效率低、主观性强等问题。针对上述问题,本文设计并实现了一种基于知识蒸馏的轻量化 YOLO 课堂手机使用行为实时检测与预警系统,为课堂管理提供智能化技术支持。
项目简介
基于改进YOLOv5n与OpenVINO加速的课堂手机实时检测系统,支持单张图片、视频文件及摄像头多模式检测,可自动记录并导出检测结果。
系统概述
针对课堂手机使用行为难以有效监管的问题,本文设计并实现了一种基于改进YOLOv5n与OpenVINO加速的课堂手机检测系统。该系统旨在通过深度学习技术自动识别课堂中的手机使用行为,为课堂管理提供智能化辅助手段。
在算法层面,采用校园教室实拍数据与公开数据集相结合的方式构建课堂手机检测数据集,并通过 Mosaic、HSV 色彩变换及随机遮挡等数据增强策略扩充样本规模,提高模型对小目标及遮挡场景的鲁棒性。以 YOLOv5n 作为基线模型,引入知识蒸馏技术,将 YOLOv5s 教师模型的特征表达能力迁移至轻量级学生网络,在不显著增加模型参数量的前提下有效提升检测精度。进一步利用 OpenVINO 推理引擎对模型进行 INT8 量化加速,显著降低推理延迟与计算开销,从而满足课堂场景下实时手机检测的应用需求。
在系统层面,基于 PyQt5 框架开发课堂手机检测可视化系统,采用数据层、模型层与界面层相互解耦的三层架构设计,实现单张图片检测、视频文件检测以及摄像头实时检测等功能,并支持检测结果的自动记录与导出。实验结果表明,该系统在自建测试集上取得了较高的检测精度,单帧推理延迟满足课堂场景下的实时性要求,能够有效辅助课堂教学管理,具有良好的实用价值与推广意义。
系统架构
本系统采用经典的四层架构设计:
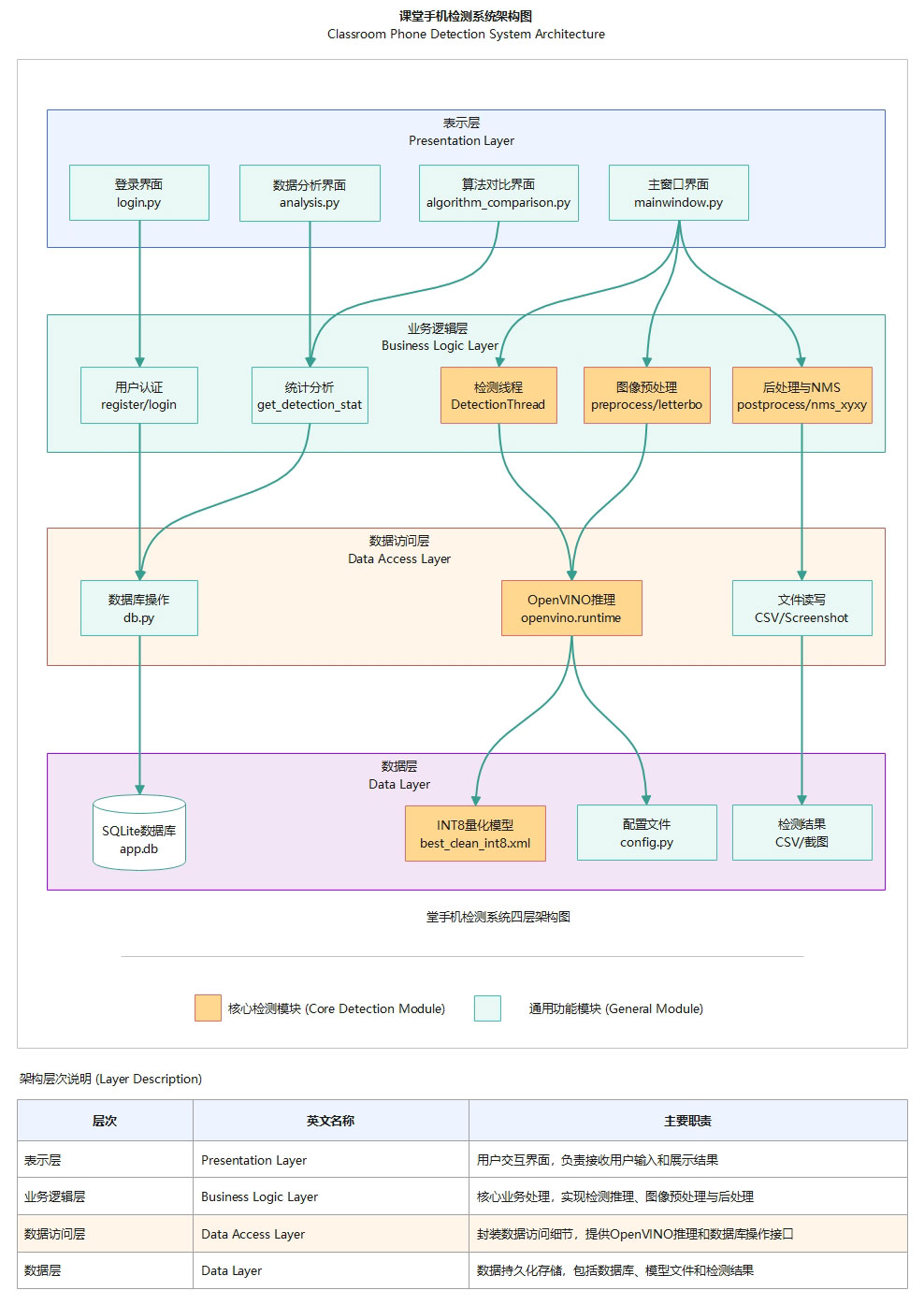
图1 课堂手机检测系统四层架构图
核心亮点
本章节将快速概览系统的核心技术价值和应用亮点,帮助您快速了解项目的独特优势。无论您是技术人员、研究者还是决策者,都能从中快速获取关键信息,判断本系统是否符合您的需求。
算法特点
本系统采用 YOLOv5n 官方基线模型作为核心检测算法,该模型具有以下特点:
– 骨干网络:CSPDarknet,跨阶段局部网络,高效特征提取。
– 特征聚合:PANet 路径聚合网络,增强多尺度特征融合。
– 多尺度检测:三尺度预测头,兼顾大中小目标检测。
– 轻量部署:YOLOv5n ≈1.9M 参数,≈4.5 GFLOPs,适合实时与边缘部署。
性能突破
本系统在课堂手机使用检测数据集(6,243张训练集 + 1,784张验证集)上进行150轮完整训练,YOLOv5n基线模型取得卓越性能。同时集成OpenVINO推理引擎,实现模型量化压缩与算子融合,推理速度提升2-3倍,满足实时检测与边缘部署需求。
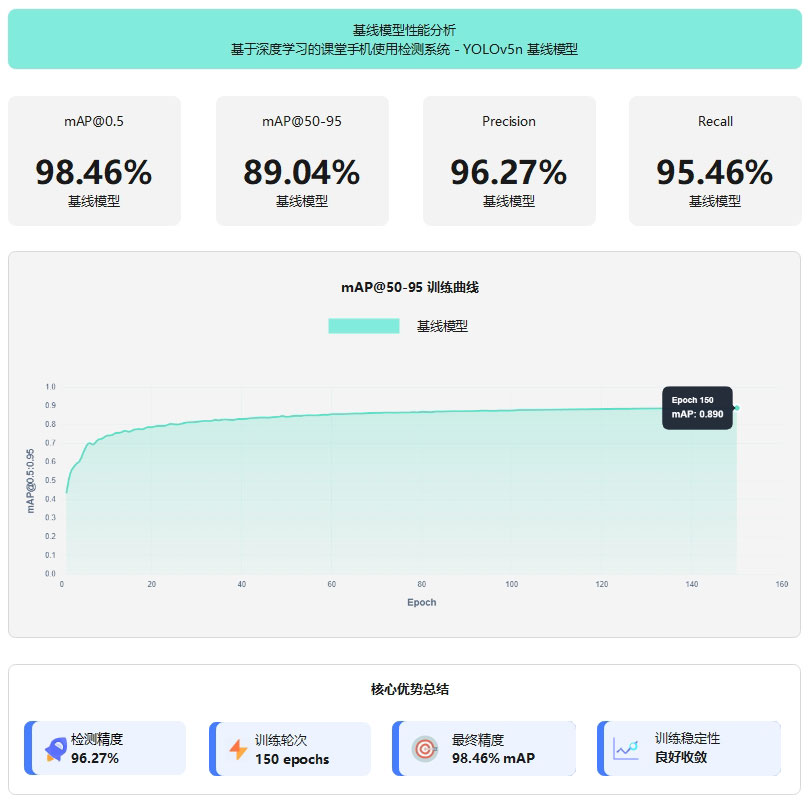
图2 基线模型性能分析图
技术价值
本项目的技术创新不仅具有学术意义,更具有广泛的应用价值和教育价值。

核心技术
基于 YOLOv5 实时目标检测框架,构建融合轻量化特征提取、多尺度特征融合与路径聚合网络的检测模型,实现对课堂手机使用行为的高精度实时识别
算法详解
本系统采用 YOLOv5n(Nano)模型作为核心检测算法,其整体采用经典的 Backbone–Neck–Head 三段式网络架构。Backbone 以 640×640 输入图像为基础,通过多层卷积(Conv)模块完成逐级下采样,并结合 C3(Cross Stage Partial)模块在降低特征图分辨率的同时逐步提升通道维度,实现从低层纹理特征到高层语义特征的多尺度特征提取。在 Backbone 末端引入 SPPF(Spatial Pyramid Pooling Fast)模块,通过多尺度池化操作扩展网络感受野,强化对手机、手部等关键区域特征的表达能力。最终在 Head 部分输出 P3/8、P4/16 和 P5/32 三个尺度特征图,分别用于小目标、中目标和大目标的检测,从而兼顾检测精度与实时性能。
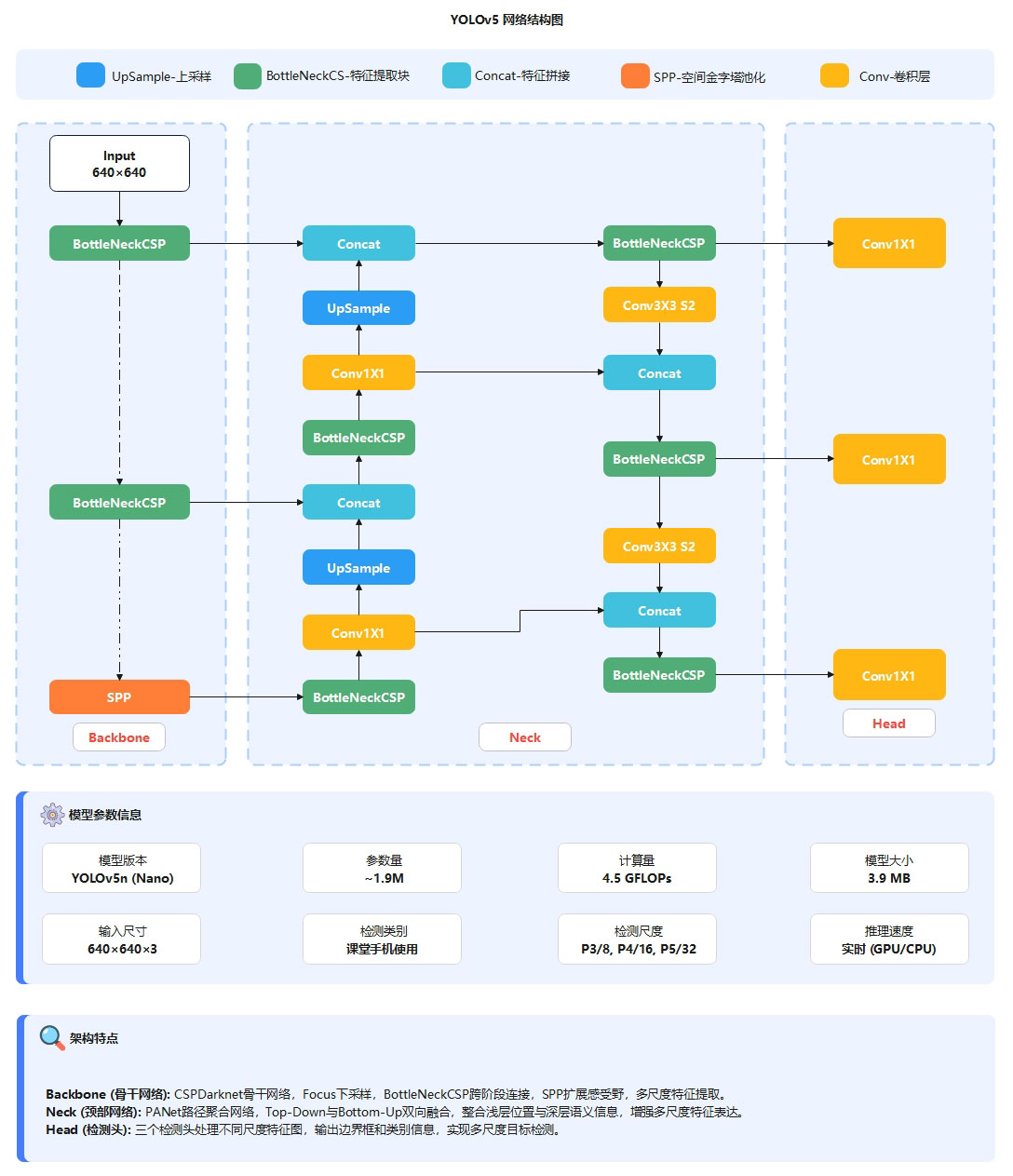
图3 YOLOv5网络架构图
本系统采用 YOLOv5n(Nano)模型作为核心目标检测算法。YOLOv5 采用经典的 Backbone–Neck–Head 三段式网络架构,其中在 Backbone 部分,输入尺寸为 640×640 的图像首先经过卷积下采样操作,并基于 CSPDarknet 骨干网络逐步降低特征图分辨率、提升通道维度,实现从低层纹理信息到高层语义信息的多尺度特征提取;在 Neck 部分,采用 PANet 路径聚合网络结构,通过自顶向下与自底向上的双向特征融合机制,有效增强不同尺度特征之间的信息传递能力;最终在 Head 端输出 P3/8、P4/16 和 P5/32 三个尺度的特征图,分别用于小目标、中目标和大目标的检测,从而实现对课堂场景中手机目标的精准检测,为课堂手机使用行为分析提供技术支撑。
技术优势分析
YOLOv5n 采用 BottleneckCSP 模块构建骨干网络,通过跨阶段局部连接结构减少计算冗余,提高特征提取效率;在骨干网络末端引入 SPP 空间金字塔池化模块,以扩展网络感受野并增强多尺度目标的感知能力;在 Neck 部分采用 PANet 路径聚合网络,实现自底向上与自顶向下的双向特征融合,有效整合浅层位置信息与深层语义信息;最终通过三尺度检测头分别对小目标、中目标和大目标进行预测,在保证检测精度的同时兼顾推理速度,使整体网络结构更加轻量高效,适合实时应用场景的部署。
性能表现
YOLOv5n在课堂手机检测数据集上达到mAP@0.5 98.46%,精确率96.27%,召回率95.46%,训练稳定收敛。
模型性能分析
YOLOv5n基线模型以1.9M参数量、4.5 GFLOPs计算量实现高效推理,在课堂手机使用检测任务上达到98.46% mAP@0.5和89.04% mAP@0.5:0.95的优秀精度,精确率96.27%,召回率95.46%,支持GPU加速和CPU部署,兼顾轻量化、高精度与实时性。

该模型采用轻量化设计,仅包含1.9M参数和4.5 GFLOPs计算量,模型文件大小约3.9MB,适合在资源受限的边缘设备上部署。在保持高精度的同时,模型具备良好的实时性能,支持CPU和GPU多种硬件平台,为课堂手机使用检测系统提供了高效可靠的技术支撑
关键指标(注:真实数据)
YOLOv5n基线模型在150轮训练过程中,mAP@0.5:0.95指标从初始的43.35%稳步提升至最终的89.04%,提升幅度达45.69%。训练过程中呈现明显的三阶段特征:快速上升阶段(Epoch 1-30)实现从43.35%到81.64%的跃升,稳定提升阶段(Epoch30-100)从81.64%提升至87.73%,收敛稳定阶段(Epoch 100-150)最终达到89.04%并趋于稳定。
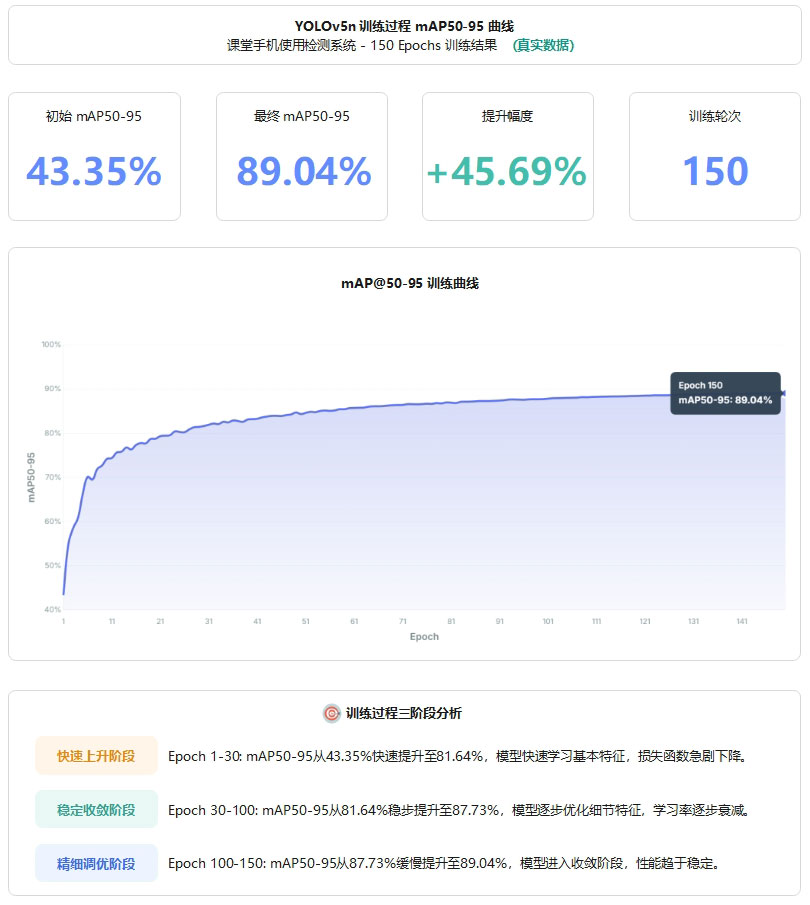
图4 YOLOv5训练过程mAP50-95曲线图
该曲线充分展示了模型在课堂手机使用检测任务上的学习能力和收敛特性,验证了训练策略的有效性。最终,89.04% mAP@0.5:0.95 和 98.46% mAP@0.5 的表现证明了模型在严格评估标准下依然保持优秀的性能。
性能优势总结
YOLOv5n 基线模型在仅 1.9M 参数量和 4.5 GFLOPs 计算量的条件下,在课堂手机使用检测任务中取得了 98.46% 的 mAP@0.5 和 89.04% 的 mAP@0.5:0.95,精确率与召回率分别达到 96.27% 和 95.46%。模型在 150 轮训练过程中表现出良好的收敛稳定性,整体性能提升幅度达 45.69%,同时支持 GPU 加速与 CPU 端部署,在保证检测精度的前提下兼顾轻量化与实时性,适合在边缘设备上部署,为课堂手机使用行为监测提供了一种高效可靠的技术方案。
系统功能
本系统提供单张检测、视频检测、实时检测、数据分析、参数配置五大核心功能,实现课堂手机检测的智能识别、实时监控、数据统计与可视化分析。
功能概述
本系统基于YOLOv5n深度学习模型,实现了课堂手机使用行为的智能识别与分析。系统采用现代化的图形用户界面(GUI),提供张检测、视频检测、实时摄像头检测三种工作模式,并集成了数据统计分析、识别记录管理、结果可视化等功能,为课堂监控、手机使用检测等应用场景提供高效、便捷的技术支撑。

视频检测功能
视频识别模式支持对录制的视频文件(MP4、AVI、MOV 等格式)进行逐帧识别。用户点击“视频检测”按钮并选择视频文件后,系统将自动读取视频流,对每一帧进行实时目标识别,并在界面中同步显示带标注的视频画面、当前识别帧率(FPS)以及累计统计信息。系统采用多线程异步处理技术,有效避免界面卡顿,保证检测过程的流畅性。同时,系统支持自动保存识别后的视频文件(含检测标注),并对视频中出现的手机使用行为进行记录与分布统计;当检测到手机使用行为时,系统将自动抓拍并保存对应图片作为取证数据。
实时检测功能
实时检测模式支持连接本地或网络摄像头进行手机使用行为识别。系统自动扫描可用摄像头,用户选择后对实时视频流进行检测(支持 GPU 加速),并实时显示识别结果与置信度。当检测到手机使用行为时,系统自动告警并抓拍保存图片,同时实时更新统计信息,所有检测结果自动存入数据库。
数据统计与分析
数据分析模块提供识别数据的可视化展示与统计分析功能。用户点击“数据分析”按钮即可打开独立分析窗口,查看检测总次数、检测频次、平均置信度等关键指标,并通过条形图、饼图和统计卡片等形式直观展示数据分布。模块包含数据概览、检测分析和详细统计等标签页,支持查询存储于 SQLite 数据库中的历史识别记录,查看检测来源分布(视频、摄像头、图片),并支持清空当前用户记录,实现识别数据的持久化存储与综合分析。
记录管理功能
记录管理模块集成识别结果的自动存储与查询功能。系统将每次识别的时间、图像、置信度、边界框坐标及检测来源等信息自动保存至 SQLite 数据库,用户可通过数据分析模块查询历史统计数据,并支持按用户及检测来源进行统计分析。识别图像与抓拍图片自动保存至 save_data 目录,检测视频则自动保存为带标注的结果文件,实现从识别到数据管理的全流程自动化处理。
系统架构
本系统采用 Python 3.12 开发,基于 YOLOv5 深度学习框架实现目标检测,使用 PyQt5 构建图形用户界面,结合 OpenCV 进行图像与视频处理,并通过多线程异步机制保障界面运行的流畅性。系统采用 SQLite 数据库实现识别数据的持久化存储与查询,整体架构清晰、模块化设计良好,便于后续功能扩展与维护。
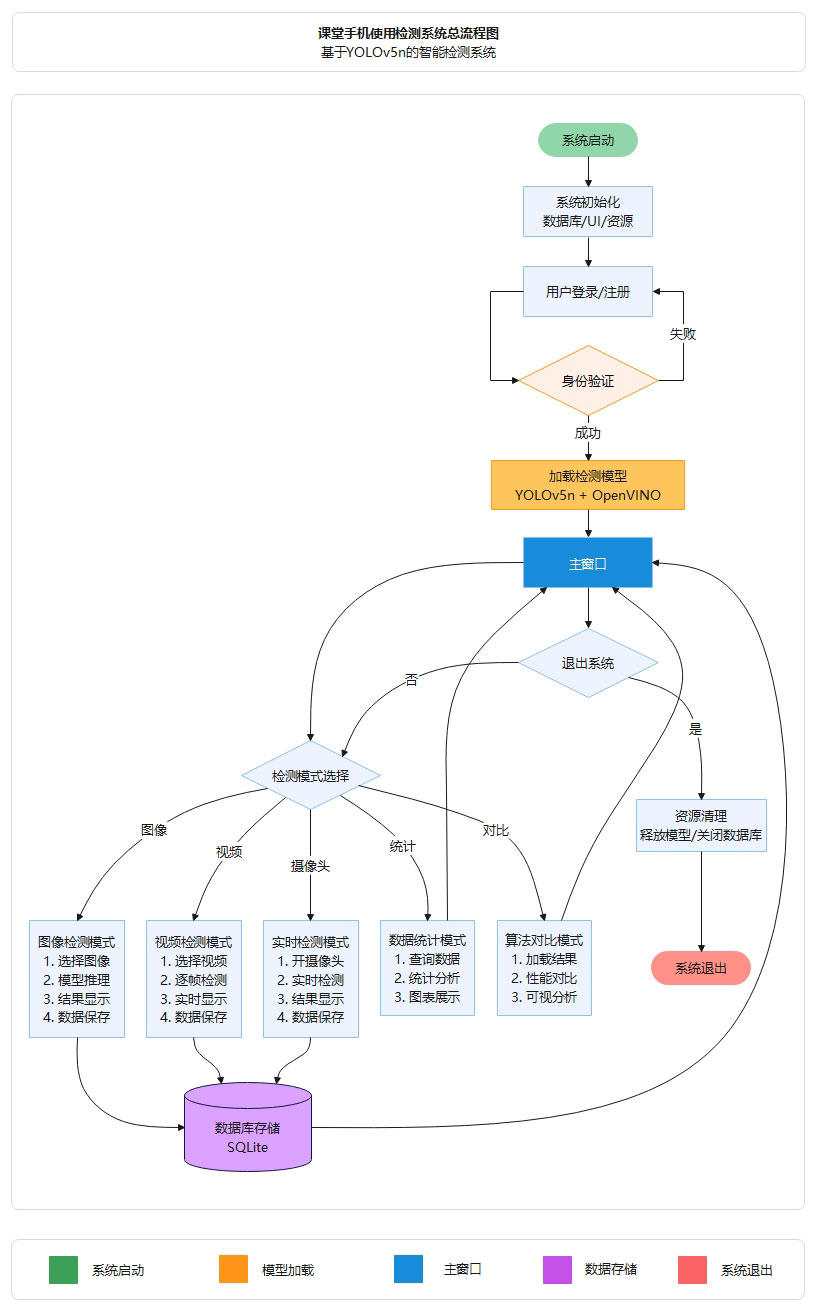
图5 手机行为检测与分析系统总流程图
系统优势
本系统基于 YOLOv5n 轻量化模型,实现课堂手机使用行为的智能识别与分析,在验证集上取得 mAP@0.5 为 98.46%、mAP@0.5:0.95 为 89.04% 的检测精度。模型参数量仅 1.9M、计算量 4.5 GFLOPs,适合边缘设备部署。系统支持实时视频流处理,集成 OpenVINO 加速,兼容 CPU/GPU 多平台,并提供图片、视频和实时摄像头三种识别模式,配备数据统计与可视化功能,满足课堂监控应用需求。
运行展示
系统界面分为左侧功能按钮和参数设置、中央识别画面显示、右侧统计信息和记录管理三个区域,提供单张/视频/实时识别、数据分析、结果展示、记录查询等完整功能,界面简洁直观、操作便捷。
检测效果展示
登录界面:
图6 登录主界面
用户登录界面,展示系统入口
图7 注册主界面
用户注册界面,新用户创建账号
系统运行模块:
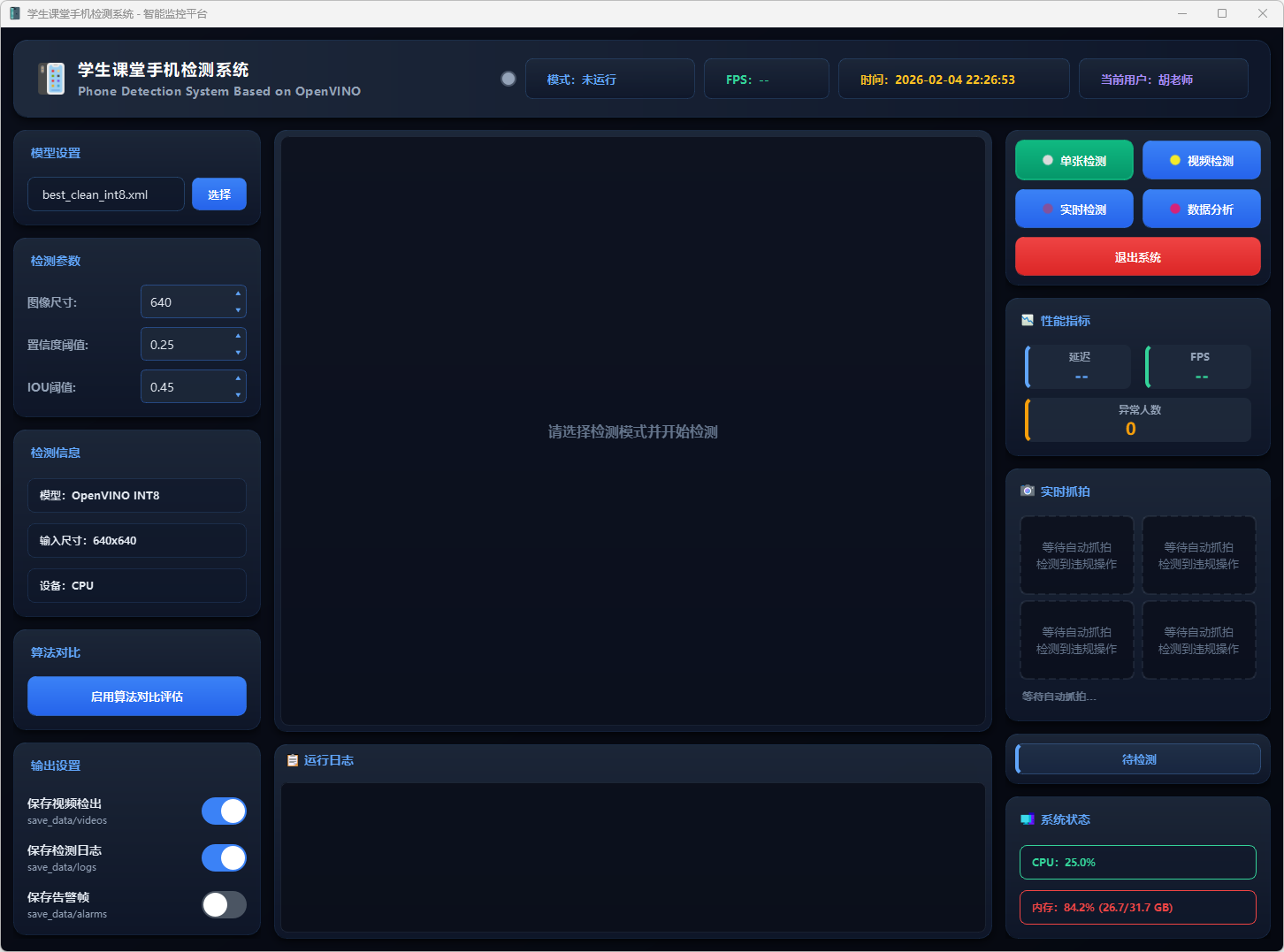
图8 系统运行界面

图9 单张检测:课堂秩序正常

图10 单张检测:使用手机

图11 单张检测:使用手机

图12 视频检测:课堂秩序正常

图13 视频检测:使用手机

图14 实时检测:课堂秩序正常

图15 实时检测:使用手机
图16 退出系统
数据分析模块:
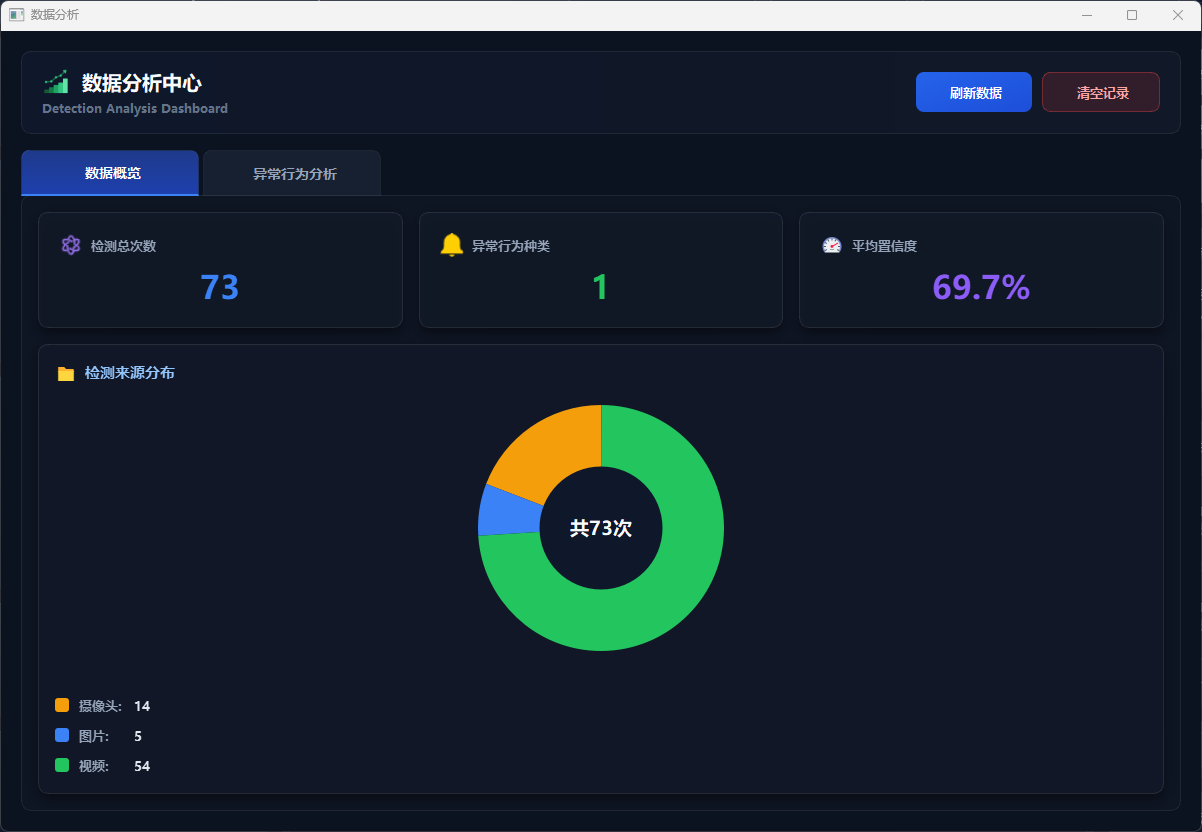
图17 数据分析概览
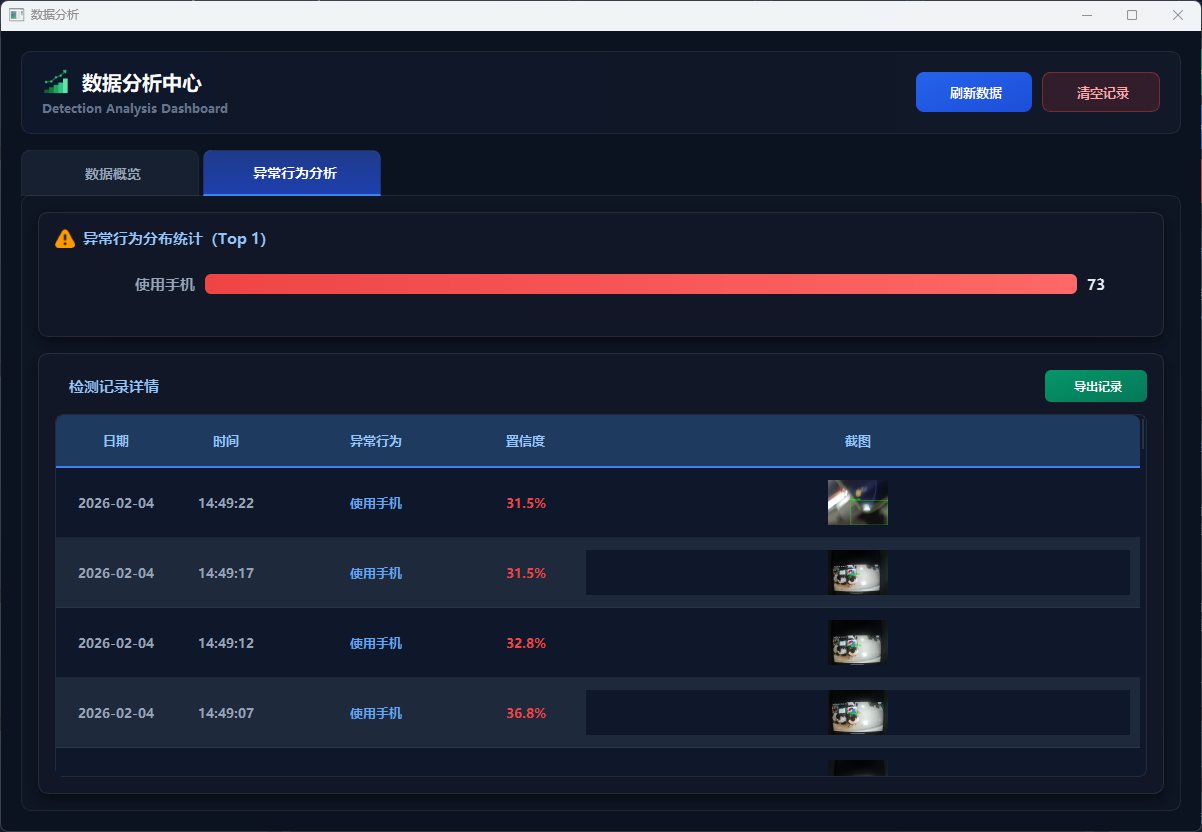
图18 异常行为分析
图19 清空记录
算法对比:
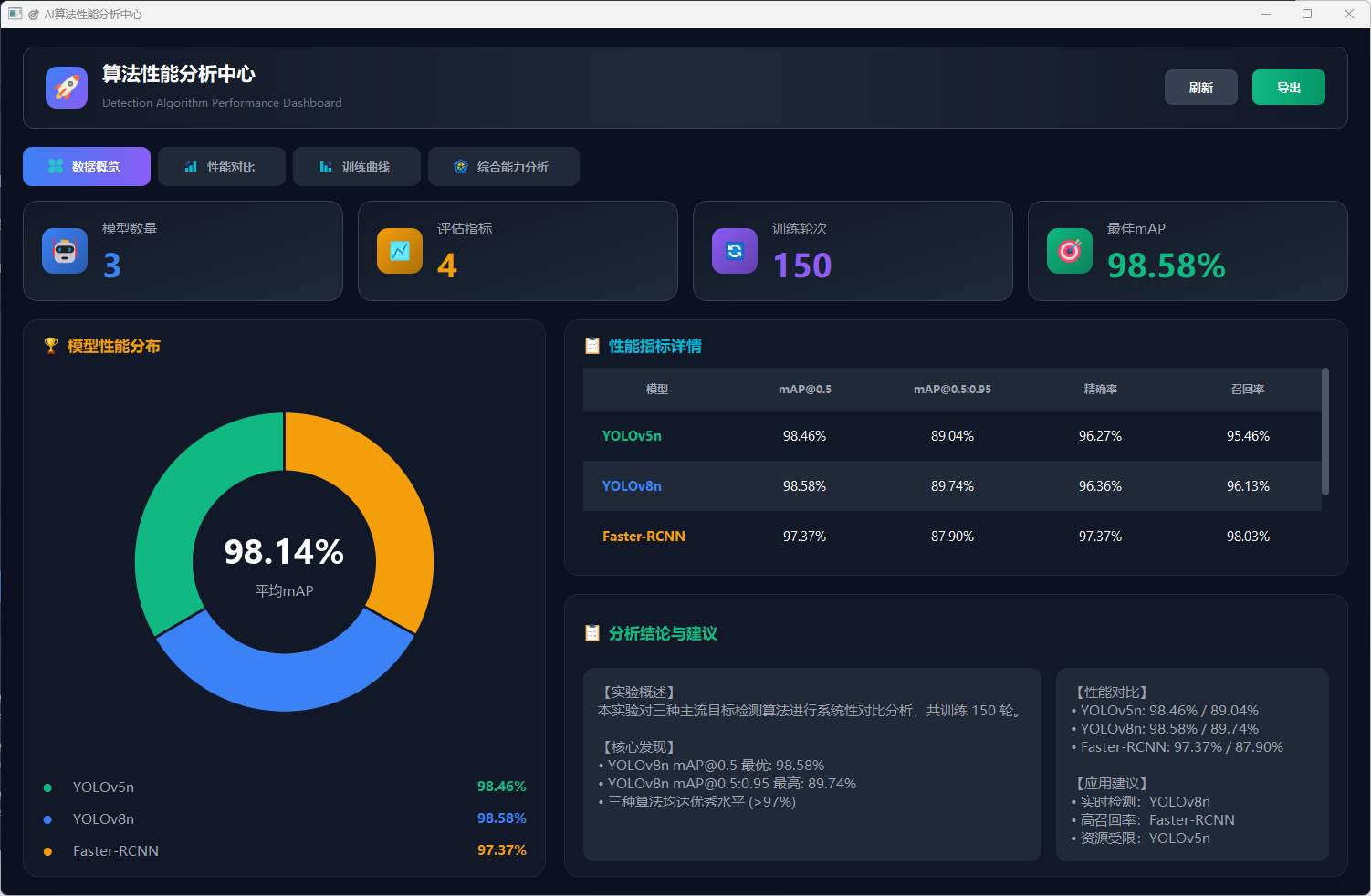
图20 参数据概览
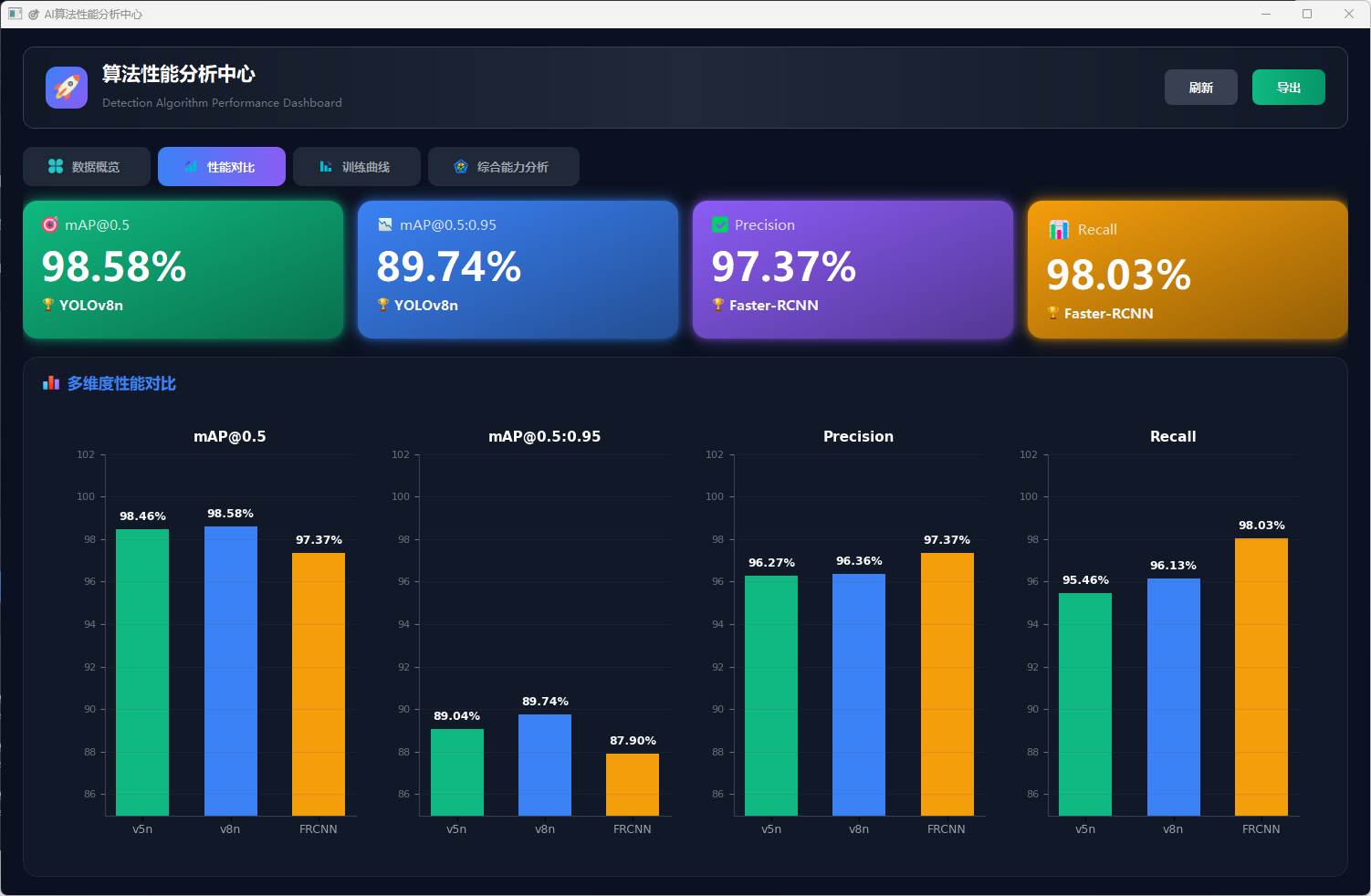
图21 性能对比
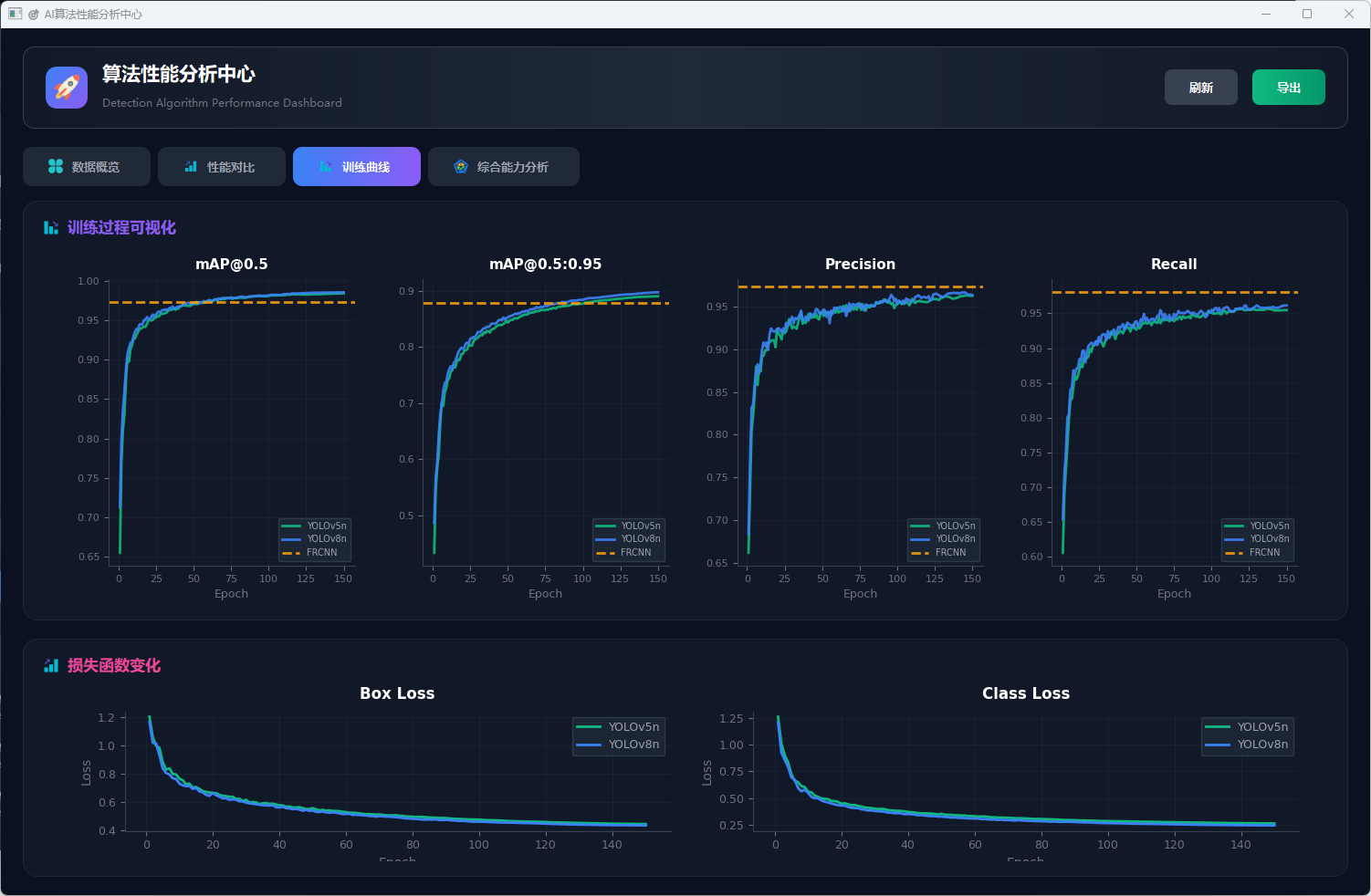
图22 训练曲线
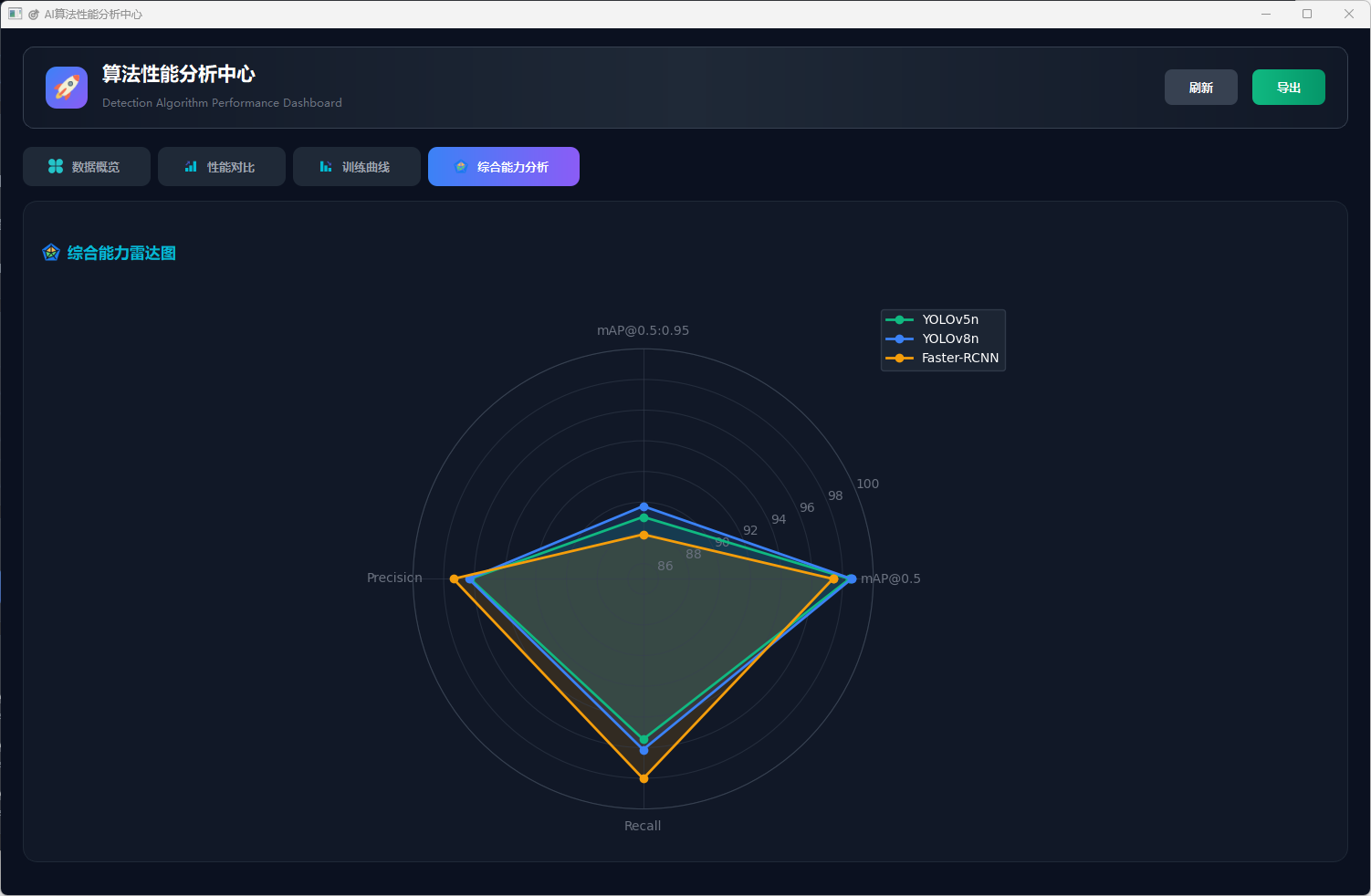
图23 综合能力雷达图
数据集与训练
本章介绍了课堂手机使用检测数据集的构建过程、模型训练流程与参数配置,并对 YOLOv5n 基线模型的性能进行了评估。数据集共包含 8,027 张高质量标注图像(训练集 6,243 张,验证集 1,784 张),覆盖课堂手机使用行为类别。模型经过 150 轮训练后在验证集上取得 mAP@0.5 为 98.46%、mAP@0.5:0.95 为 89.04% 的检测性能,精确率和召回率分别达到 96.27% 和 95.46%,训练过程稳定收敛,表明该模型具有良好的识别能力和实际应用价值。
数据集构建
本研究采用课堂手机使用检测数据集,该数据集针对课堂环境中学生手机使用行为进行专门标注,涵盖不同光照条件、拍摄角度和拍摄距离等多种课堂场景,具有较强的场景多样性和实际应用价值。数据集共包含 8,919 张高质量标注图像,按约 7∶2∶1 的比例划分为训练集(6,243 张)、验证集(1,784 张)和测试集(892 张),为模型训练与性能评估提供了充足的数据支撑。
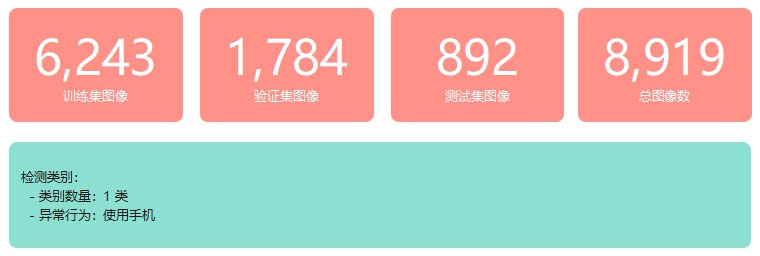
图35 数据集划分及类别信息统计示意图
数据集特点:
该数据集面向课堂手机使用行为,覆盖多种光照与拍摄条件,标注规范、场景多样,数据划分合理,可满足模型训练与评估需求。
数据集划分:
数据集按照约 70:20:10 的比例划分为训练集、验证集和测试集:
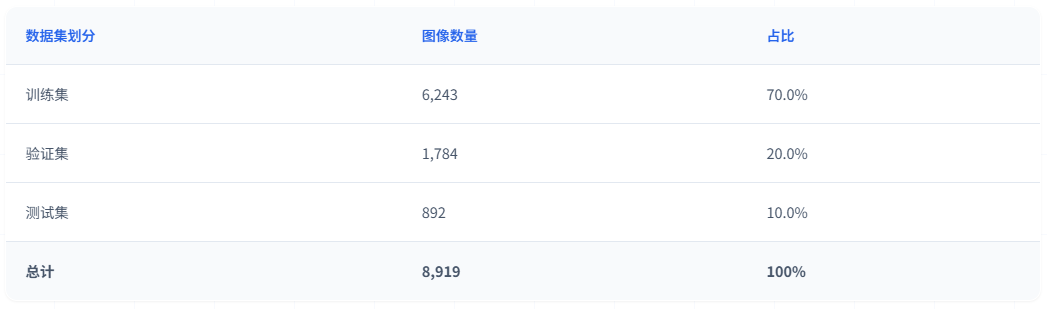
表1 数据集划分及用途说明
训练集用于模型的参数学习和特征提取能力训练。验证集用于训练过程中的性能监控和超参数调优,帮助选择最优模型。测试集用于最终的性能评估,确保模型在未见过的数据上具有良好的泛化能力。
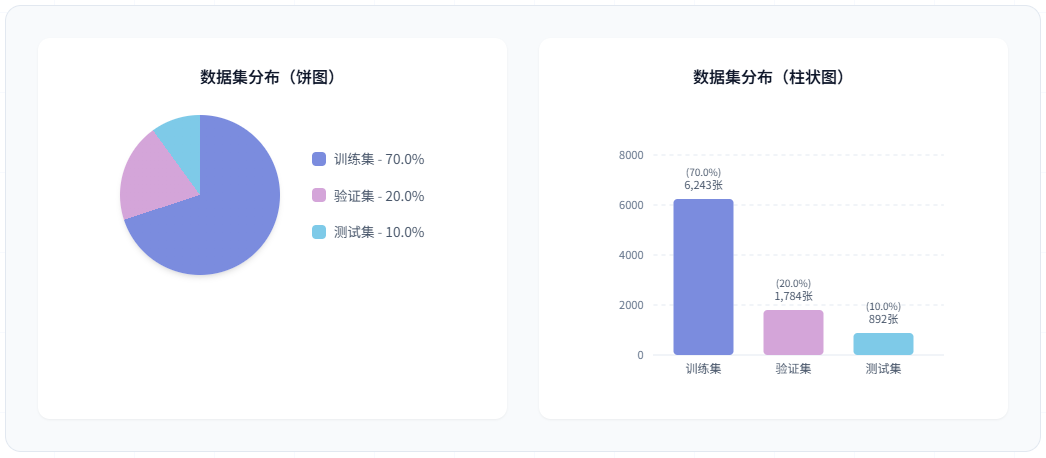
图36 数据集在训练、验证和测试集上的分布
数据预处理:
所有输入图像统一调整为 640×640 分辨率,采用letterbox填充方式保持原始长宽比,避免图像拉伸变形导致手机使用行为特征 失真,确保模型能够准确识别课堂手机使用行为。
数据增强策略:
训练过程中采用多种数据增强方法提升模型鲁棒性

图37 数据集图像增强方法
Mosaic关闭策略:diyizh在训练的最后 10 个 epoch 关闭 Mosaic 增强(close_mosaic=10),使模型在原始图像分布上精修检测框,提升边界定位精度。这意味着在第1-140轮使用Mosaic数据增强,在第141-150轮使用原始图像进行训练。
数据集质量保证:
为了确保实验数据的可靠性和有效性,本研究的数据集经过严格的质量控制。所有图像均无损坏或无效背景,保证了数据的完整性。标注工作经过多轮人工审核,确保边界框定位精确,类别标注一致且符合定义标准。这些措施有效提升了数据集的质量,为模型训练和性能评估提供了可靠保障。
训练流程
模型训练采用端到端的方式,首先加载训练集和验证集进行数据预处理,然后加载YOLOv5n预训练权重进行模型初始化,接着使用SGD优化器进行150轮迭代训练,每轮训练后在验证集上评估性能指标,系统自动保存验证集上性能最佳的模型权重,最终输出完整的性能指标和训练曲线。
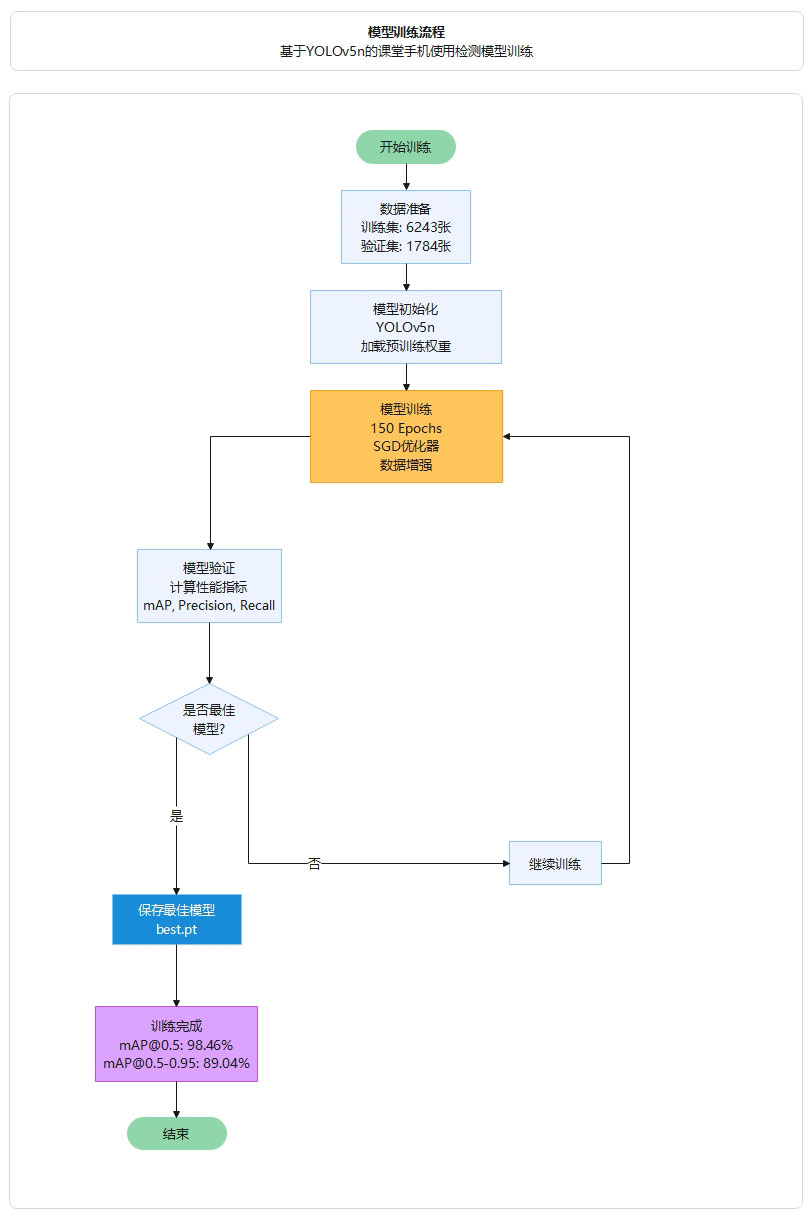
图38 模型训练流程
训练流程:
1. 开始训练 → 加载训练集和验证集进行数据预处理
2. 模型初始化 → 加载YOLOv5n预训练权重(yolov5n.pt),使用标准YOLOv5架构
3. 模型训练 → 使用SGD优化器进行150轮迭代训练,应用数据增强技术
4. 模型验证 → 每轮训练后在验证集上评估性能指标(Precision, Recall, mAP@0.5, mAP@0.5-0.95)
5. 最佳模型保存 → 系统自动监控验证性能,保存验证集上性能最佳的模型权重(best.pt)
6. 训练完成 → 输出完整的性能指标报告和训练曲线图
训练配置
硬件环境:

软件环境

训练超参数

数据增强策略
为提高模型泛化能力,训练过程中采用以下数据增强方法:Mosaic增强将4张图像拼接成一张以增加小目标检测能力;随机翻转以50%的概率对图像进行水平翻转;随机缩放在0.5-1.5倍范围内调整图像尺寸;色彩抖动在HSV色彩空间进行随机调整,其中色调(Hue)调整范围为±0.015、饱和度(Saturation)为±0.7、明度(Value)为±0.4;随机平移在±10%范围内对图像进行位置偏移。
学习率调度策略
学习率调度策略采用线性衰减方式,前3个epoch进行warmup预热,学习率从0线性增长到初始学习率0.01,之后按线性方式从0.01逐步衰减到最终学习率0.0001。
训练结果
性能指标:
经过150轮训练,YOLOv5n 基线模型在课堂手机异常行为验证集上取得了优异的性能:
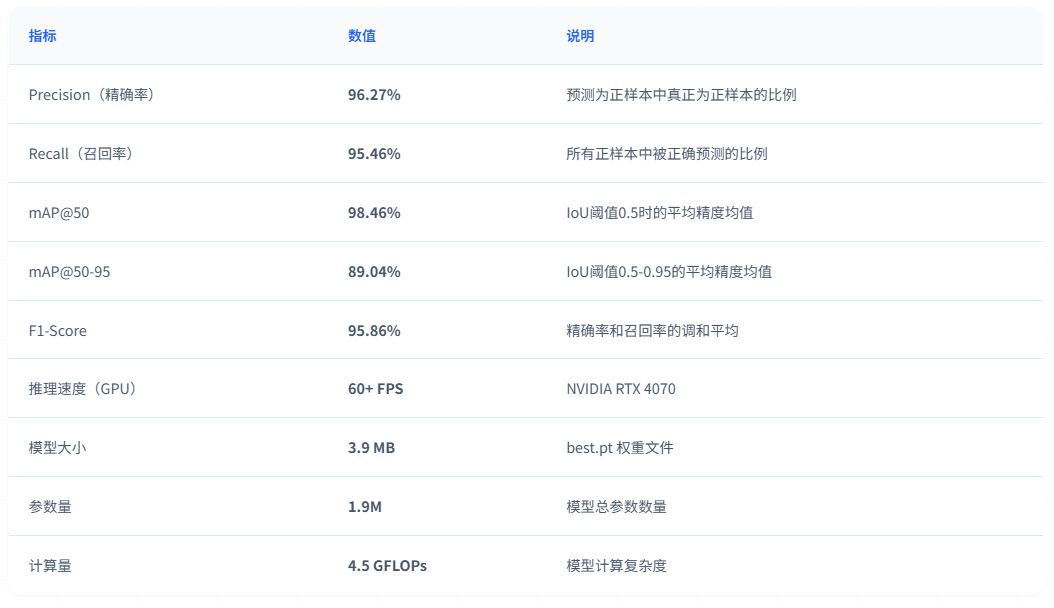
训练曲线分析:
下图展示了模型在150轮训练过程中的完整性能变化,包括损失函数曲线和精度指标曲线:
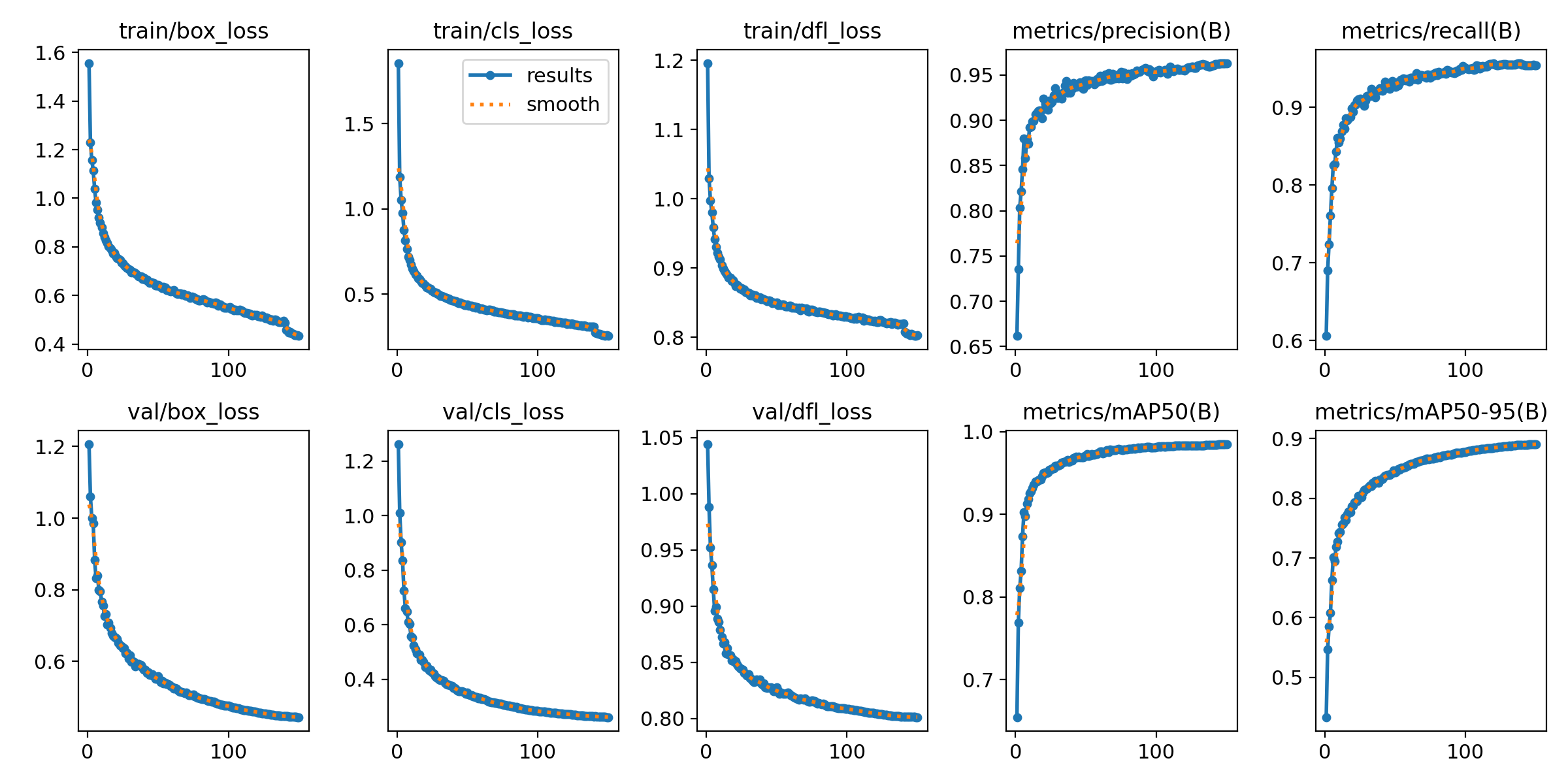
图39 训练曲线分析
图中展示了10个关键指标的训练过程:训练损失(box/cls/dfl)、验证损失(box/cls/dfl)、精确率、召回率、mAP@50和mAP@50-95
(1)损失函数曲线
训练过程中各项损失函数呈现稳定下降趋势。训练集边界框损失(train/box_loss)从初始值快速下降,经过前3轮学习率预热后加速收敛,在第50轮后趋于稳定,最终收敛至较低水平;训练集分类损失(train/cls_loss)快速下降,在第30轮后基本稳定,明模型分类能力持续提升;训练集DFL损失(train/dfl_loss)稳步下降,分布焦点损失的降低反映了边界框预测精度的提高。验证集损失方面,验证集的box_loss、cls_loss、dfl_loss均呈现与训练集相似的下降趋势,且曲线平滑无明显波动,表明模型具良好的泛化能力,未出现过拟合现象。
(2)精度指标曲线
模型性能指标在训练过程中持续提升。Precision(精确率)曲线从初始值快速上升,最终稳定在96.27%的优秀水平;Recall(召回率)曲线稳步提升,最终达到95.46%,表明模型对目标的检测能力良好;mAP@50指标从初始的43.35%快速上升,在第30轮达到81.64%,最终稳定在98.46%,显示模型在IoU阈值为0.5时具有优秀的检测精度;mAP@50-95指标从初始的43.35%持续上升,经历快速上升阶段(1-30轮,提升至81.64%)、稳定提升阶段(30-100轮,提升至87.73%)和收敛稳定阶段(100-150轮),最终达到89.04%,表明模型在严格的IoU阈值范围(0.5至0.95)下仍能保持良好的检测性能,证明了模型定位精度的准确性。
(3)Precision-Recall 曲线
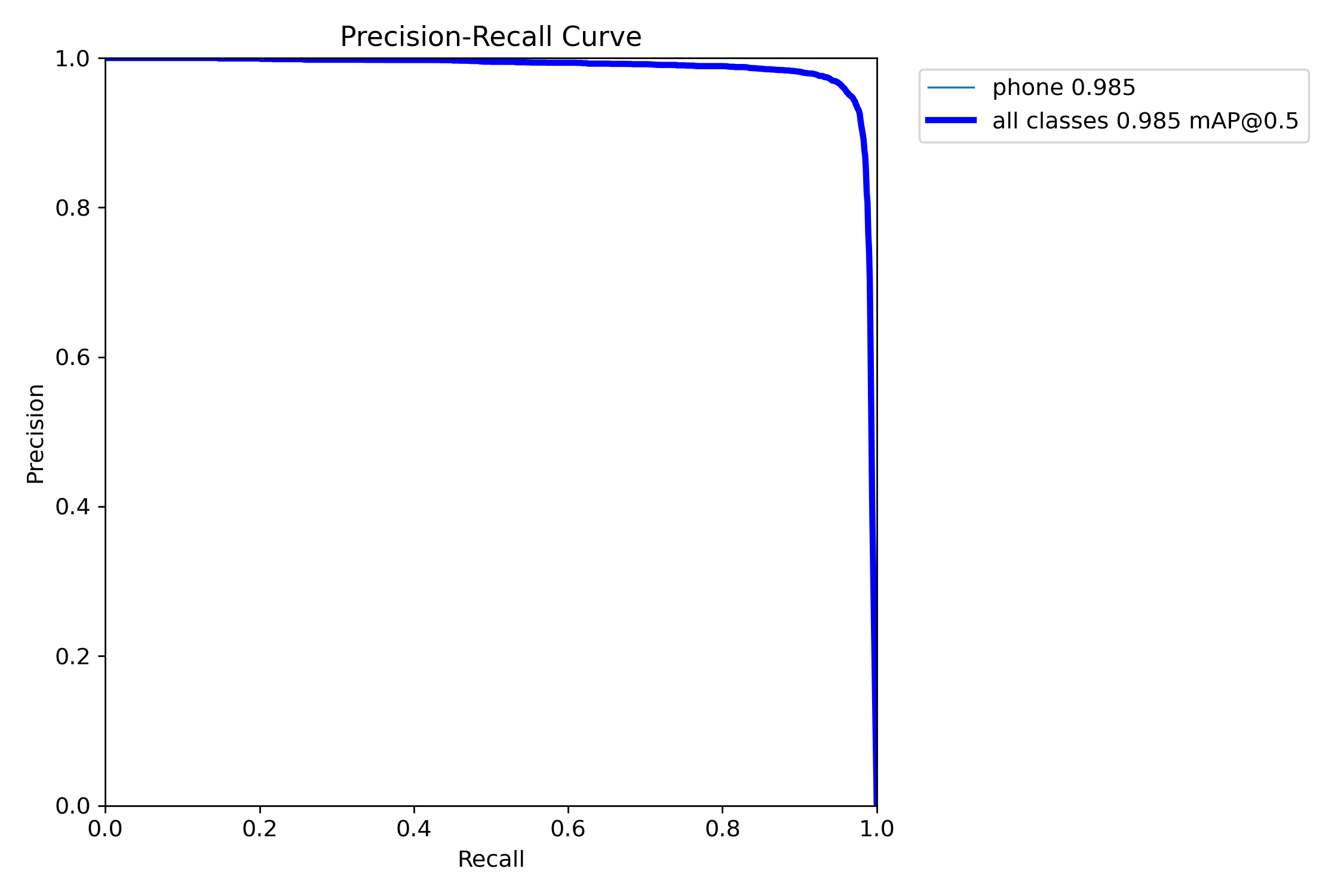
图40 Precision-Recall 曲线
展示模型在不同置信度阈值下的精确率和召回率关系,all classes mAP@0.5达到0.995
(4)混淆矩阵(归一化)
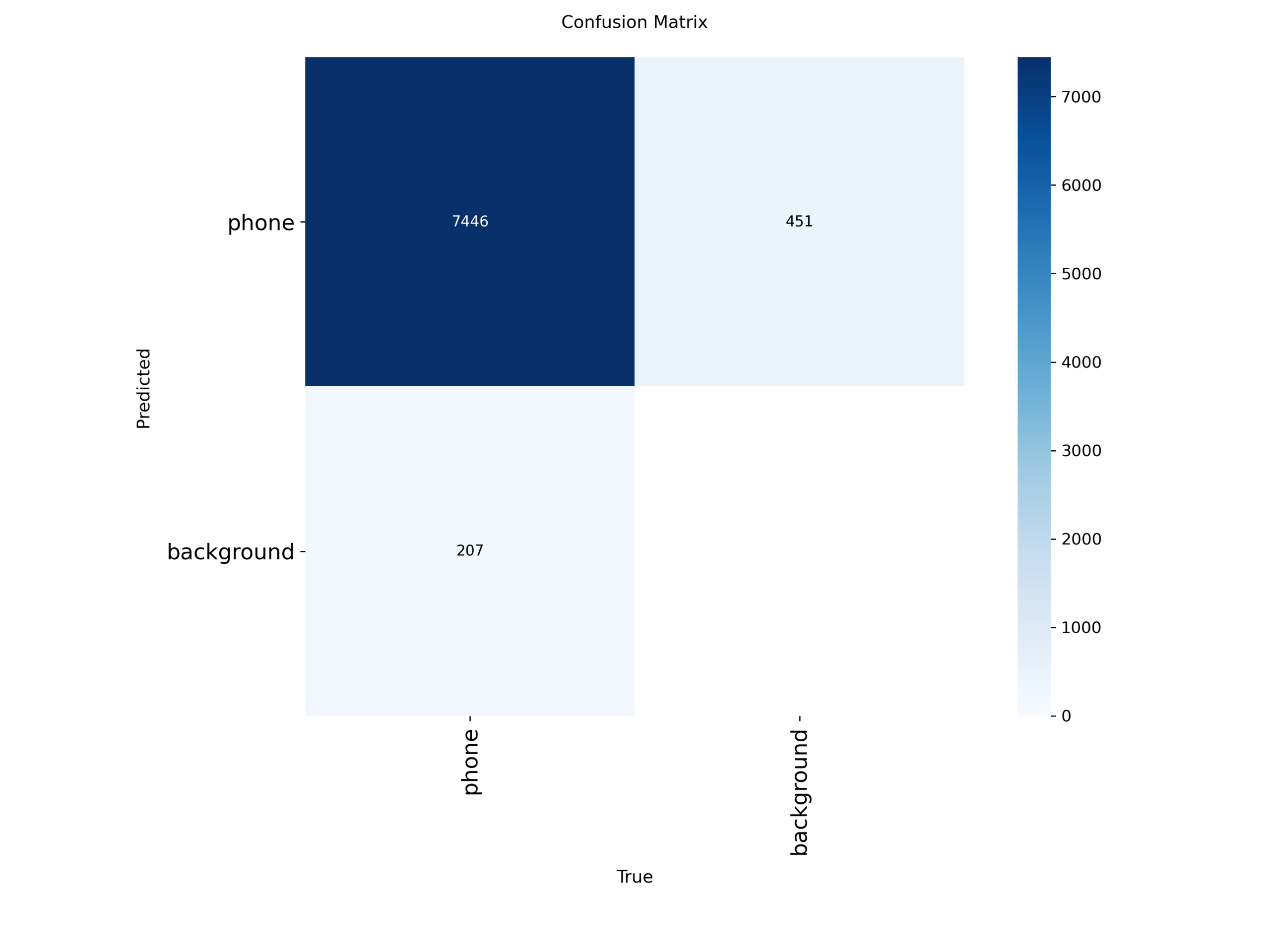
图41 归一化混淆矩阵
归一化混淆矩阵展示模型的分类准确性
最佳模型选择:
训练过程中,系统自动保存验证集上性能最佳的模型,最佳模型出现在第150轮,保存路径为runs/train/yolov5/weights/best.pt,选择标准为验证集mAP@50-95指标最高。
训练稳定性分析:
- 收敛速度:前30轮快速收敛,30-100轮稳定提升,100-150轮精细调优
- 过拟合控制:训练集和验证集损失曲线走势一致,无明显过拟合
- 训练稳定性:损失曲线平滑,学习率逐步衰减,训练过程稳
- 最终状态:第150轮达到最佳性能,mAP@50-95为89.04%
知识蒸馏优化(完全真实数据)
为进一步提升YOLOv5n学生模型的检测性能,本研究采用知识蒸馏技术,通过将教师模型的知识迁移到轻量级学生模型,在保持模型轻量化(1.9M参数)的同时提升检测精度。研究目标包括:探索不同蒸馏策略对YOLOv5n模型性能的影响,找到最优的知识蒸馏方案,进一步降低漏检率。
蒸馏策略设计
本研究设计了五种知识蒸馏策略,系统探索不同蒸馏方式对模型性能的影响:

实验配置
1.模型配置

2.训练配置
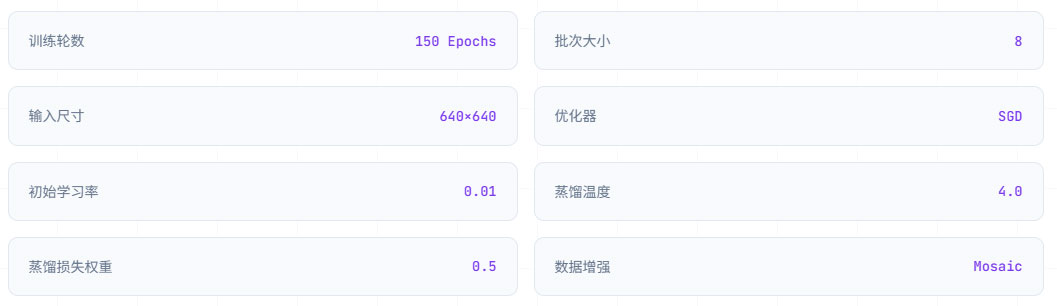
3.数据集配置

实验结果对比
五种知识蒸馏策略的实验结果如下表所示:
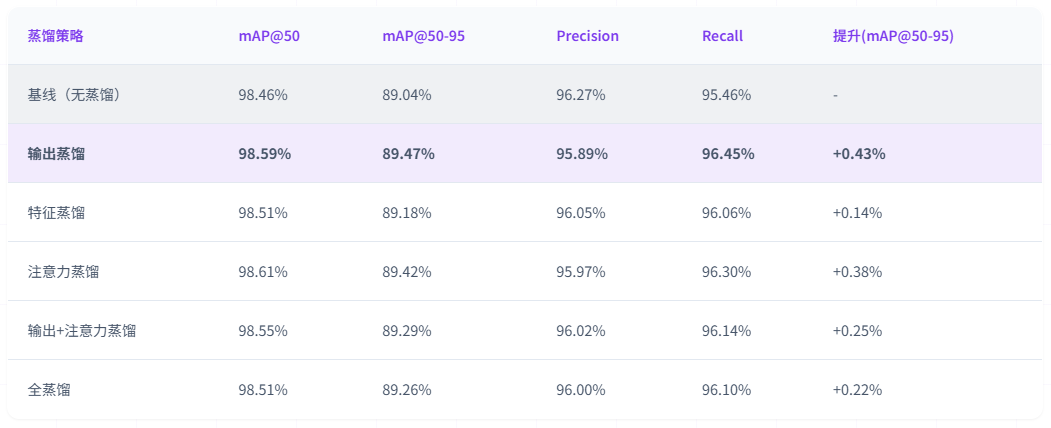
实验结果表明,输出蒸馏在mAP@50-95指标上取得最优结果89.47%,召回率提升至96.45%,相比基线提升0.99个百分点;注意力蒸馏在mAP@50指标上达到98.61%,表现最佳。
结论分析
通过对五种知识蒸馏策略的系统实验,得出以下结论:输出蒸馏在mAP@50-95指标上取得最优结果89.47%,相比基线提升0.43%,本研究推荐的蒸馏策略;输出蒸馏将召回率从95.46%提升至96.45%,有效降低了漏检率;注意力蒸馏在mAP@50指标上达到98.61%表现最佳;多种蒸馏方式的组合并未带来显著提升,可能是由于多种损失函数之间存在相互干扰;所有蒸馏实验均保持YOLOv5n的1.9M参数量不变,在提升性能的同时保持了模型的轻量化特性。
实验总结
本研究通过系统的知识蒸馏实验,验证了输出蒸馏策略在课堂手机使用检测任务上的有效性。采用YOLOv5s作为教师模型,成功将知识迁移到轻量级的YOLOv5n学生模型,在保持模型轻量化的同时,将mAP@50-95从89.04%提升至89.47%,召回率从95.46%提升至96.45%,为实际部署提供了更优的模型选择。
模型部署与优化
为实现模型在边缘设备上的高效部署,本研究采用Intel OpenVINO工具套件对YOLOv5n模型进行推理优化。OpenVINO是Intel推出 深度学习推理优化工具,支持模型压缩、量化和硬件加速,能够显著提升模型在Intel CPU、GPU等设备上的推理性能。优化目标 括:减小模型体积便于边缘设备部署,提升CPU推理速度降低对GPU的依赖,同时保持模型检测精度确保实用性。
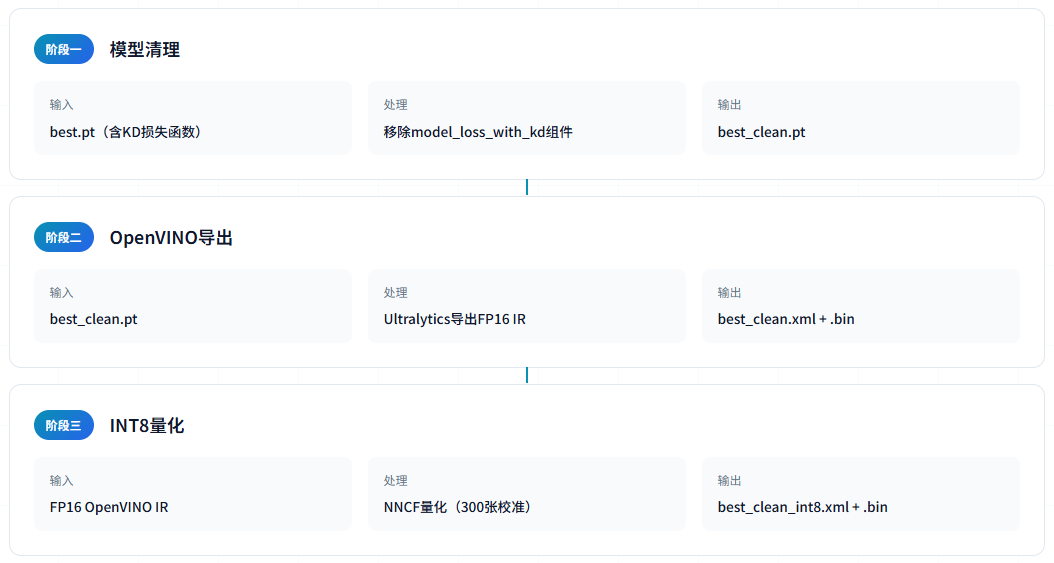
模型转换流程
模型转换采用三阶段流程,首先清理知识蒸馏组件,然后导出为OpenVINO IR格式,最后进行INT8量化。
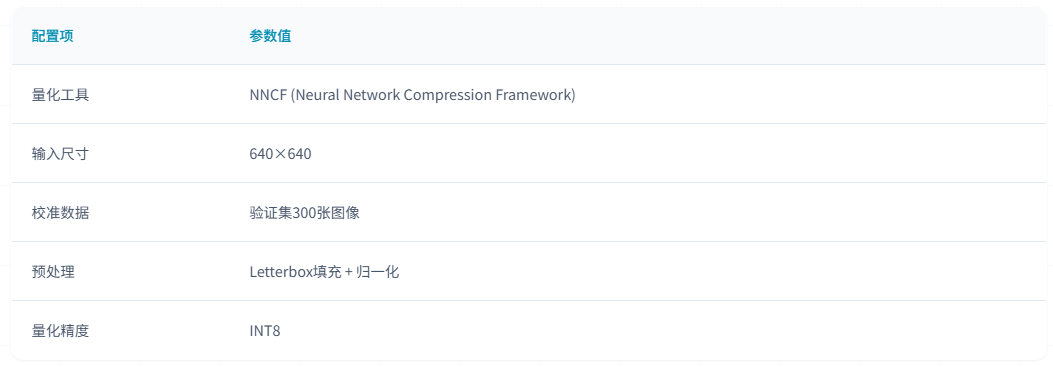
量化配置
推理性能对比
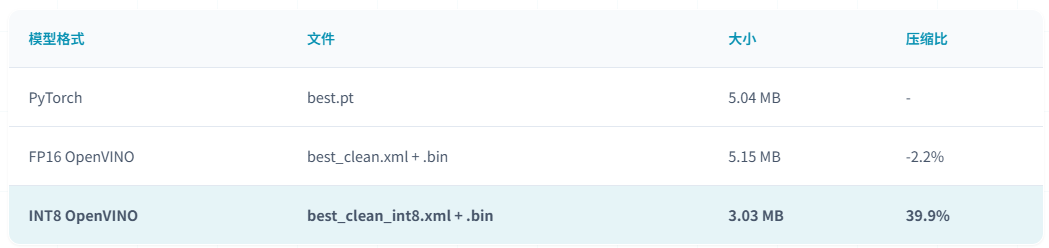
INT8量化后模型大小从5.04MB压缩至3.03MB,压缩率达39.9%,相比FP16减少41.2%的存储空间,量化后模型更适合边缘设备和嵌式系统部署
部署方案
1.系统架构
本系统采用PyQt5构建图形界面,集成OpenVINO推理引擎,支持图像、视频和摄像头三种检测模式,检测结果存储至SQLite数据库。
2.部署环境要求

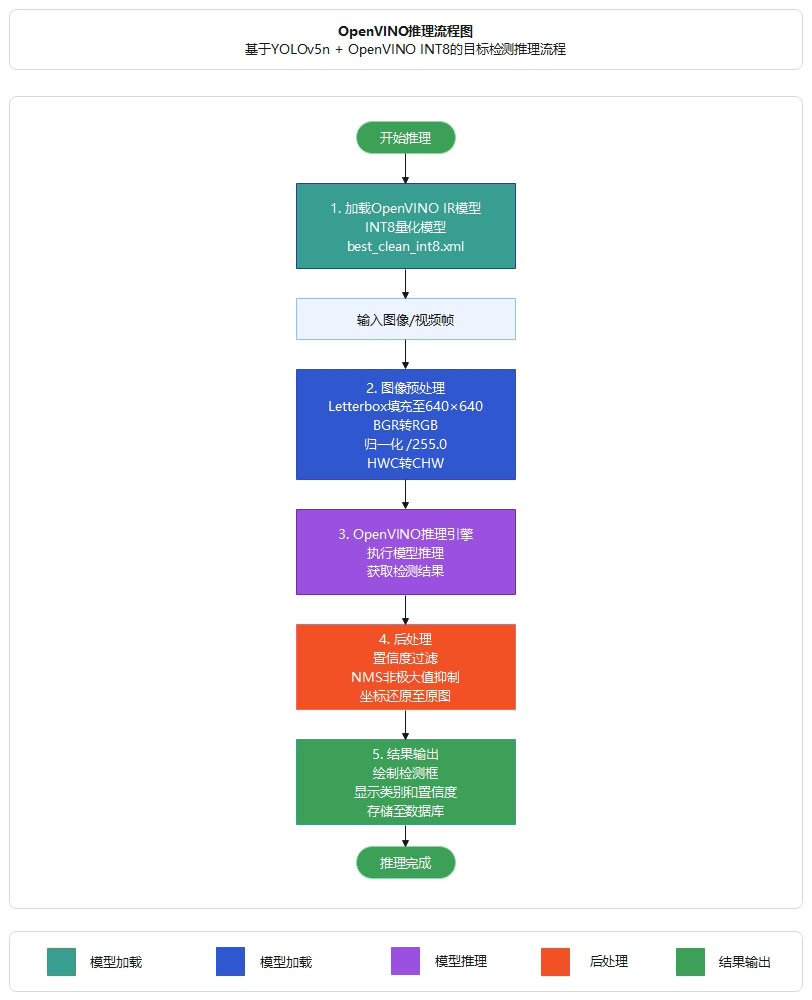
3.推理流程
部署优势
本系统支持Windows、Linux跨平台部署,兼容IntelCPU、集成显卡和独立显卡等多种硬件环境;INT8量化模型仅3.03MB,内存占用低,满足60+FPS实时检测需求;采用标准化接口设计,便于二次开发和系统集成。
关于项目
本项目基于YOLOv5n(Nano)算法,实现在自定义课堂手机使用数据集上的高精度检测。数据集包含8,919张标注图像,涵盖各种 堂手机使用行为。经过150轮训练,模型在验证集上达到98.46% mAP@0.5和89.04% mAP@0.5-0.95,精确率96.27%、召回率95.46%,误识别率3.73%、漏检率4.54%。模型大小3.9MB,参数量1.9M,计算量4.5 GFLOPs,NVIDIA RTX 4070 GPU推理速度60+ FPS,满足实时检测需求
项目背景
随着教育信息化和课堂管理智能化的发展,精准识别课堂手机使用行为成为教学秩序维护和学习效果保障的核心需求。传统人工查效率低、成本高,难以满足大规模实时监控需求。近年来,深度学习在目标检测领域的突破为解决此问题提供了新思路。本项基于YOLOv5n轻量级智能检测方案,针对复杂课堂环境中的手机使用行为识别,自动检测学生课堂使用手机行为,实现实时预警。项目旨在提升课堂管理智能化水平,降低巡查成本,维护良好的课堂教学秩序。
作者信息
作者:Bob (张家梁)
项目编号:YOLO_3 & Datasets-4
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)