

摘要:本篇文章将介绍一种突破性的改进机制——Deformable Large Kernel Attention (DLKA),并深入探讨其如何与YOLOv11深度融合,进行二次创新改进,显著提升模型在复杂视觉任务中的检测性能。
项目信息
编号:PA-1
版本:8.3.203(Ultralytics YOLOv11框架)
作者:Bob(二次改进)
环境配置
开发工具:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
语言环境:Python == 3.12
依赖包:
– pip install numpy==2.0.2
– pip install opencv-python==4.12.0.88
– pip install pillow==11.3.0
– pip install PyQt5==5.15.11
– pip install PyYAML==6.0.2
– pip install torch==2.6.0
– pip install torchvision==0.21.0
– pip install matplotlib==3.9.4
– pip install pandas==2.2.3
– pip install requests==2.32.5
– pip install scipy==1.13.1
研究背景
Deformable-LKA结合了大卷积核的广阔感受野和可变形卷积的灵活性,能够有效地处理复杂的视觉信息。通过动态调整卷积核的形状和大小,这一机制能够自适应地捕捉不同图像特征,从而显著提升模型在多变场景下的表现,尤其是在面对小目标和不规则形状目标时。特别是在YOLOv11中,Deformable-LKA的引入显著提升了模型在复杂背景或不同光照条件下的鲁棒性,使其能够更加精准地检测各类目标。此外,Bob在此基础上进行了二次创新改进,提升了模型的平均精度(mAP),进一步推动了YOLOv11在目标检测任务中的应用表现。
Deformable-LKA注意力机制原理
Deformable Large Kernel Attention (DLKA) 是一种用于视觉任务的注意力机制,旨在提升模型在处理不同尺寸和形状对象时的灵活性和性能。DLKA 的设计灵感源自传统的注意力机制,但通过引入可变形核(deformable kernel)来增强对局部特征的适应能力。
1.Deformable-LKA机制的基本原理
Deformable Large Kernel Attention (D-LKA) 是一种结合大卷积核和可变形卷积的注意力机制,其基本原理旨在通过模仿自我关注机制的感受野,同时有效降低传统自我关注机制所需的高计算成本。具体而言,D-LKA通过大卷积核来捕捉图像的广泛上下文信息,并结合可变形卷积的灵活性,使得模型能够动态调整卷积核的形状和大小,从而更好地适应不同的数据模式和视觉任务。以下是D-LKA的主要特点:
(1)大卷积核:
D-LKA采用大卷积核来扩展感受野,以捕捉图像中的广泛上下文信息。这一策略有效模拟了自我关注机制中的感受野特性,允许模型在较少的参数和计算开销下,获得更丰富的上下文信息。
(2)可变形卷积:
D-LKA结合了可变形卷积技术,允许模型的采样网格根据图像特征进行灵活调整。这种动态适应能力使得卷积核能够自适应地聚焦于图像中更具挑战性的区域,尤其是在面对不同形状和尺度的目标时,能够提供更加精确的特征提取。
(3)2D与3D适应性:
D-LKA的2D和3D版本设计,使得该机制不仅能够处理传统的二维图像数据,还能够在三维数据中表现出色。通过这种适应性,D-LKA能够处理不同深度和维度的输入数据,在复杂场景下提升模型的鲁棒性与准确性。
通过这些设计,D-LKA有效提升了模型在多变环境中的表现,尤其在面对不同形态、尺度和复杂背景的目标时,展现出强大的自适应能力。
2.大卷积核在Deformable-LKA中的应用
大卷积核(Large Kernel)通过扩展感受野有效捕捉图像的广泛上下文信息,能够模拟自注意力机制中的全局感知能力,但在计算上优于传统自注意力机制,降低了计算复杂度和参数数量。为了高效构建大卷积核,本文采用深度可分离卷积(depth-wise convolution)和带扩张的深度可分离卷积(depth-wise dilated convolution)技术,显著减少计算量并提高效率,同时增强了对不同尺度特征的感知能力。结合可变形卷积(Deformable Convolution)后,Deformable-LKA机制通过动态调整采样位置,提升了对不规则形状和尺度变化目标的检测精度和鲁棒性。这种优化不仅提高了模型对复杂场景的适应性,还有效提升了检测性能和计算效率。
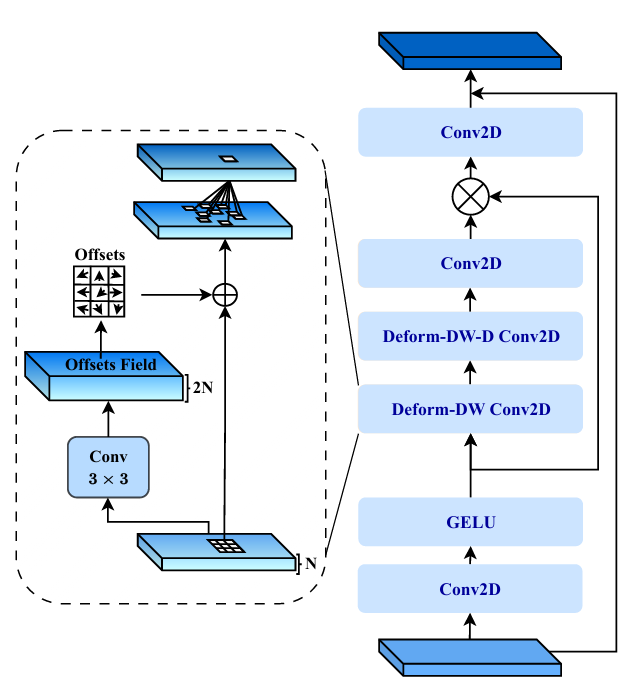
图1 可变形LKA模块的架构图
从图中可以看出,Deformable-LKA模块由多个关键的卷积层组成,每个层的设计都旨在增强网络对复杂视觉特征的适应能力。具体而言,模块包括以下几个主要组件:
(1)标准的2D卷积(Conv2D):
该层执行传统的卷积操作,用于提取输入图像的低层特征,并为后续的变形卷积层提供基础特征图。
(2)带有偏移量的变形卷积(Deformable Convolution, Deform-DW Conv2D):
该层结合了标准卷积和可变形卷积的优势,通过在卷积过程中引入偏移量,使得卷积核能够根据输入特征图自适应地调整其采样位置。这种机制使得网络可以更灵活地捕捉不同形状、尺度和局部特征,提高了模型在复杂模式下的表现。
(3)偏移场(Offsets Field)的计算:
偏移场是通过标准卷积层生成的,它为变形卷积提供了必要的信息,指示如何调整采样位置。通过计算偏移场,模型能够灵活地调整感受野的大小和形状,以更好地适应图像中的不规则区域,增强对图像细节和结构的理解。
(4)激活函数GELU:
激活函数GELU(Gaussian Error Linear Unit)用于引入非线性特性,提升模型的表达能力。GELU能够比ReLU等传统激活函数更好地捕捉复杂的输入特征,并有效避免梯度消失问题,从而加速模型的训练并提高其性能。
整体来看,该模块通过结合标准卷积、可变形卷积和偏移场计算,以及非线性激活函数,构建了一个具有高度灵活性的特征提取机制,极大地增强了Deformable-LKA对复杂视觉模式的适应能力和鲁棒性,尤其在处理具有多样形态和尺度变化的目标时表现尤为突出。
3.可变形卷积在Deformable-LKA中的作用
可变形卷积(Deformable Convolution)是一种增强模型对不规则形状和尺寸目标捕捉能力的技术,特别适用于医学图像等复杂结构的处理。通过引入偏移量,卷积核能够动态调整采样位置,灵活适应图像特征,聚焦于不规则区域,提升特征提取能力。偏移量由图像特征学习生成,使模型自适应调整感受野的形状和大小,捕捉不同形状和尺寸的目标。在医学图像分析中,尤其在器官分割任务中,可变形卷积提供更精确的边缘定义和区域分割,显著提高了检测和分割的准确性,广泛应用于医学和卫星图像等领域。
4.Deformable-LKA的2D与3D适应性
2D和3D适应性是Deformable Large Kernel Attention(D-LKA)在不同维度数据中的应用能力。2D D-LKA适用于二维图像数据,如X射线和MRI,利用大卷积核和可变形卷积提升图像特征提取能力。3D D-LKA则扩展到体积数据(如3D MRI、CT扫描),增强对空间上下文的理解,尤其在体积重建和三维结构识别中表现优异。两者均显著提高了医学图像处理的精度和鲁棒性。
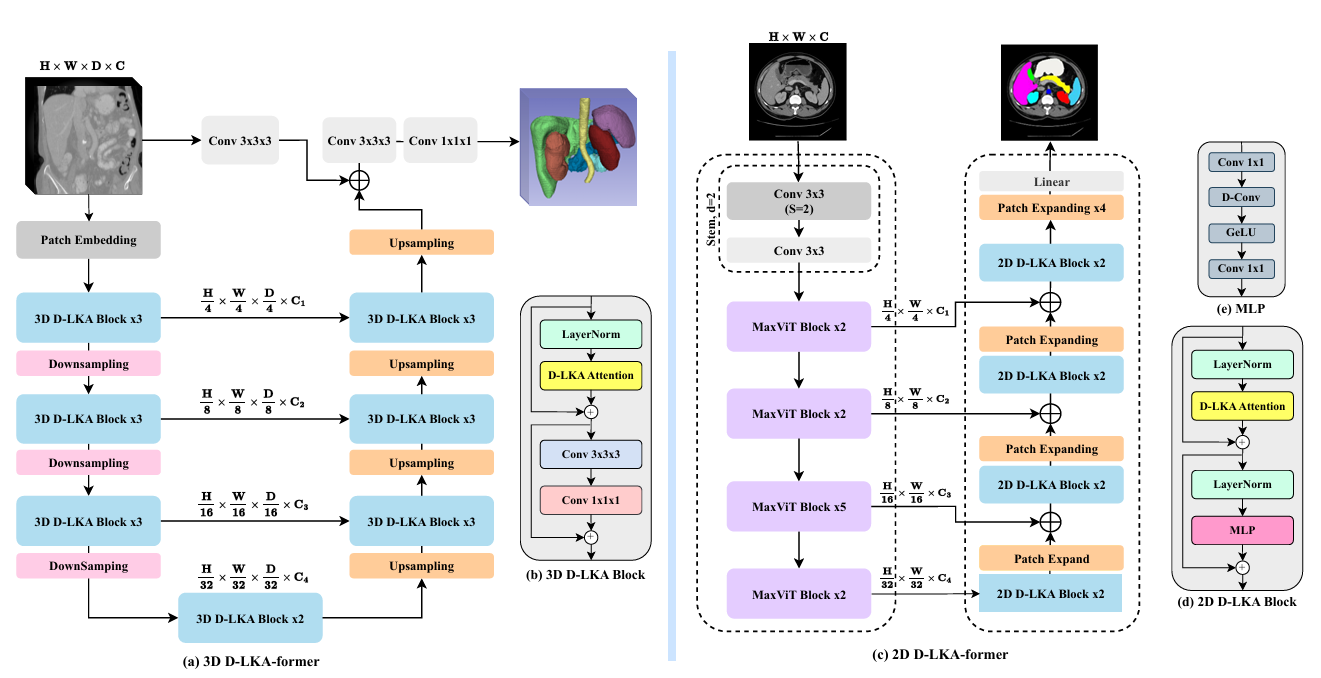
图2 左侧为3D D-LKA模型的提出网络架构,右侧为2D D-LKA模型的架构。
Deformable-LKA代码实现
第一步:
在 ultralytics/nn 文件夹下创建一个名为 ‘AddModules’ 的新目录(如果该目录已存在于现有的算法改进文件中,则无需重新创建)。在该目录内创建一个新的 Python 文件,并将核心代码复制并粘贴到该文件中。这样可以确保模块的组织结构清晰、便于维护,同时为后续代码扩展和调用提供便利。
第二步:
在 ‘AddModules’ 目录下创建一个新的 Python 文件,命名为 ‘_init.py_’(如果该目录已存在于现有的算法改进文件中,则无需重新创建)。在该文件内部导入所需的检测头模块,如下图所示。这一步骤是确保模块能够被正确加载和引用。
第三步:
在 ‘ultralytics/nn/tasks.py’ 文件中完成必要的导入和模块注册(如果该目录已存在于现有的算法改进文件中,则无需重新创建,可以跳过此步骤,直接进入第四步)。该步骤确保模块能够在系统中正确识别并顺利调用。
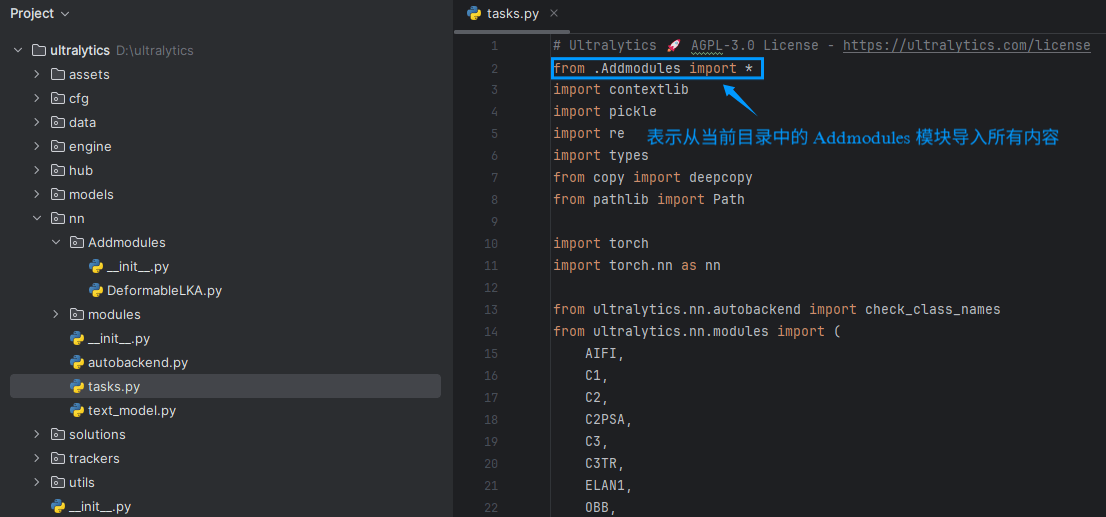
第四步:
根据前述步骤,在 parse_model 函数中进行必要的修改。这一步骤确保新模块能够正确集成到现有的模型架构中,并与其他模块顺利协作,确保模型整体的协调性与功能性。
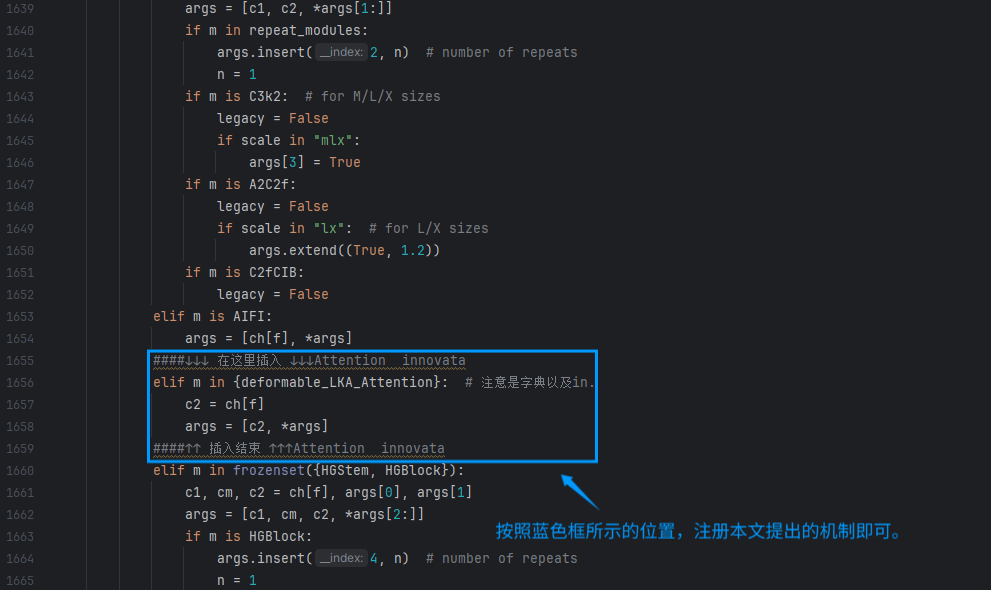
至此,所有修改已完成。大家可以复制下面的YAML文件名并运行train.py 。
Deformable-LKA的YAML文件
训练版本信息:yolo11-DLKA.yaml
训练代码
训练过程
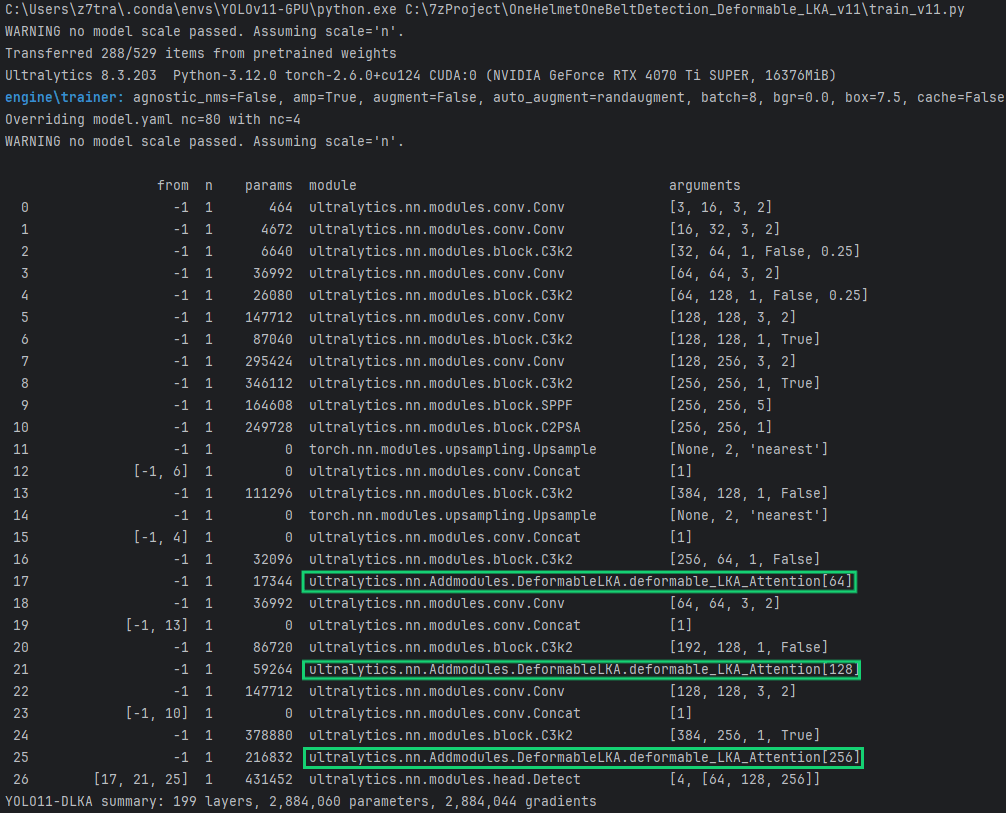
对比实验
为验证所提出的 YOLO11-DLKA 改进模型在目标检测任务中的有效性,本文设计了与原始 YOLOv11n 模型的对比实验,进一步评估其在检测精度和召回能力方面的性能表现。实验在完全一致的硬件环境和参数配置下进行,所用数据集为统一的 汽车安全带 和 电动车头盔 图像数据集。分别采用 YOLOv11n 原始模型与改进后的 YOLO11-DLKA 模型进行训练与推理测试,并依据常用的目标检测评价指标:包括 Precision、Recall、mAP@50 以及 mAP@50-95 对两类模型的检测性能进行量化对比,相关结果如表所示。
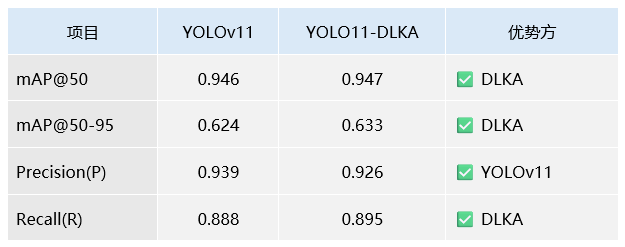
从实验结果分析可见,YOLO11-DLKA 模型在召回率(Recall)方面表现优于 YOLOv11,提升幅度为 0.007,有效降低了模型在复杂场景下的漏检率。同时,在 mAP@50 与 mAP@50-95 两项指标上也略有提升,分别为 0.001 和 0.009,反映出改进模型在多阈值下的稳定性与鲁棒性更强。尽管在 精度(Precision) 指标上略有下降,降幅为 0.013,但这种轻微的精度-召回权衡在实际检测任务中是可以接受的,尤其是在对小目标或边缘目标更为敏感的应用场景下,提升的召回率更具实用价值。
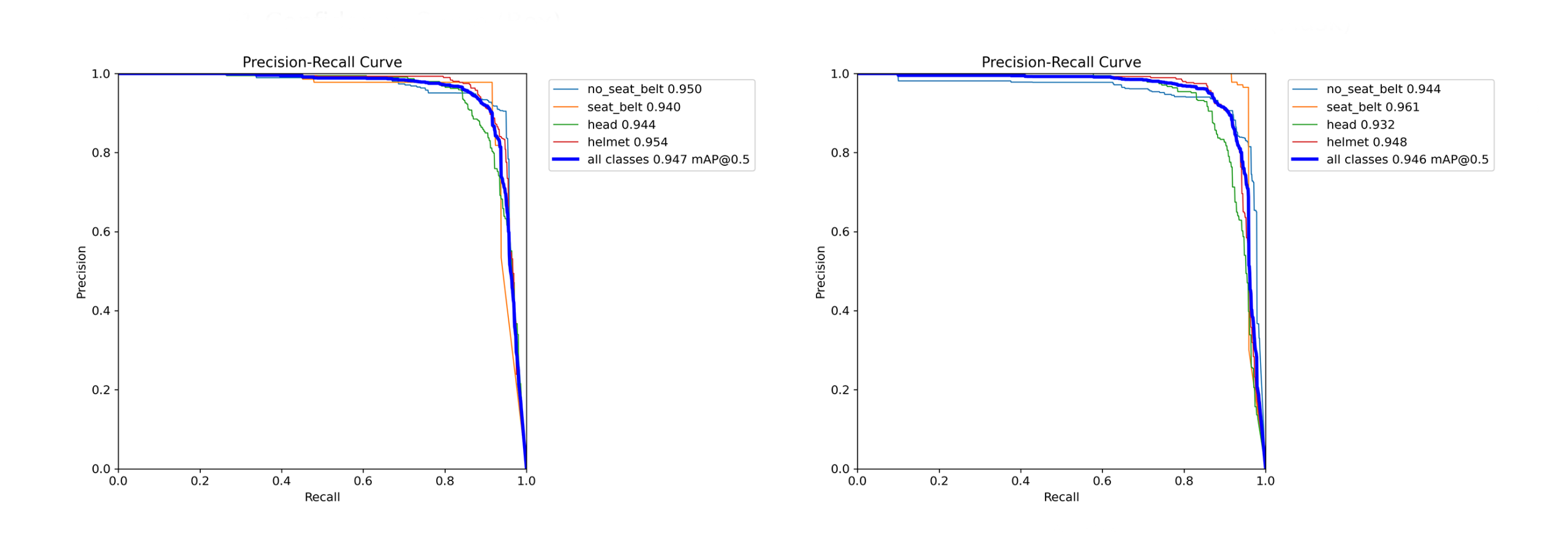
图中展示了 YOLOv11 与改进后的 YOLO11-DLKA 模型在汽车安全带与电动车头盔各类别上的 Precision-Recall 曲线对比。整体来看,两种模型在大多数类别上均取得了较高的检测性能,尤其在 “no_seat_belt” 与 “helmet” 等目标特征明显的类别中,Precision 与 Recall 均接近饱和,曲线整体分布在右上方区域,表明检测精度与召回率均较优。
值得注意的是,YOLO11-DLKA 模型在 “seat_belt” 和 “head” 两个相对难检测或边界模糊的类别上表现更为稳定。其 Precision-Recall 曲线更贴近图像右上角,说明改进模型在保持较高 Precision 的同时,有效提升了 Recall,体现出 Deformable-LKA 注意力机制 对局部特征与全局信息的联合建模能力,从而降低了漏检率。
此外,从图中 mAP@50 综合值 可见,YOLO11-DLKA 模型在各类别上的检测结果更加均衡,整体 mAP@50 提升至 0.947(较 YOLOv11 的 0.946 略有提高),表现出更好的鲁棒性与泛化能力。该结果验证了在 YOLOv11 框架中引入 Deformable-LKA 模块 对提升模型整体检测性能的有效性与可行性。
训练结果
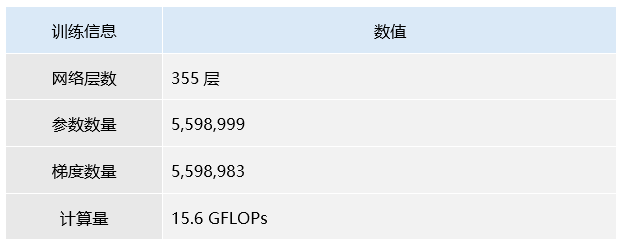
本研究使用 汽车安全带与电动车头盔图像数据集 对改进后的 YOLO11-DLKA 模型进行了训练,并完成了 150 个 epoch 的训练过程,耗时约 1.254 小时。最终训练模型在验证集上的整体性能如下:Precision 为 0.926,Recall 达到 0.895,mAP@50 为 0.947,mAP@50-95 为 0.633,表现出良好的检测精度与稳定性。
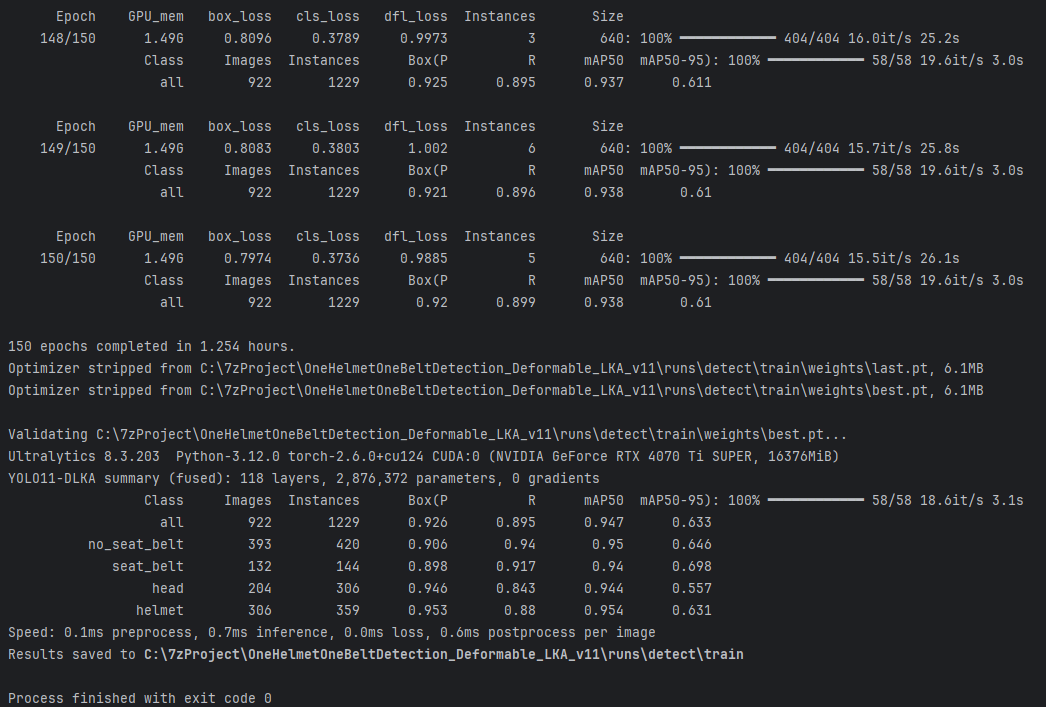
从各类别表现来看,模型在 “no_seat_belt” 和 “helmet” 类别上达到最高的检测性能(mAP@50 分别为 0.950 和 0.954),说明模型在这类目标样本上具有较强的辨识能力。对于 “seat_belt” 和 “head” 类别,模型的 mAP@50 分别为 0.940 和 0.944,尽管 “seat_belt” 类别的 Recall 有所提升,但 Precision 稍有下降,表现出一定的权衡。
此外,模型推理效率良好,单张图像的前处理时间为 0.1ms,推理时间为 0.7ms,后处理时间为 0.6ms,说明该结构具备较好的部署能力,能够在实时应用中保持高效性能。
该分析验证了 YOLO11-DLKA 模型在 汽车安全带 和 电动车头盔 检测任务中的有效性,特别是在高精度和高召回率的平衡上表现出色,特别是在 “no_seat_belt” 和 “helmet” 类别中有突出的表现。
服务项目
联系我们

官方声明
(1)实验环境真实性与合规性声明:
本研究所使用的硬件与软件环境均为真实可复现的配置,未采用虚构实验平台或虚拟模拟环境。实验平台为作者自主购买的惠普(HP)暗影精灵 10 台式整机,具体硬件参数详见表。软件环境涵盖操作系统、开发工具、深度学习框架等,具体配置详见表,所有软件组件均来源于官方渠道或开源社区,并按照其许可协议合法安装与使用。
研究过程中严格遵循学术诚信和实验可复现性要求,确保所有实验数据、训练过程与结果均可在相同环境下被重复验证,符合科研规范与工程实践标准。
(2)版权声明:
本算法改进中涉及的文字、图片、表格、程序代码及实验数据,除特别注明外,均由2zcode.Bob独立完成。未经2zcode官方书面许可,任何单位或个人不得擅自复制、传播、修改、转发或用于商业用途。如需引用本研究内容,请遵循学术规范,注明出处,并不得歪曲或误用相关结论。
本研究所使用的第三方开源工具、框架及数据资源均已在文中明确标注,并严格遵守其相应的开源许可协议。使用过程中无违反知识产权相关法规,且全部用于非商业性学术研究用途。
评论(0)