

摘要:本研究使用的字体图像数据集共包含 3840 张有效图像,其中训练集 2880 张、验证集 480 张、测试集 480 张,数据类别包括宋体、黑体、楷体、隶书、仿宋、微软雅黑、等线、华文楷体、华文隶书、华文行楷、方正舒体和方正姚体共 12 类。该数据集为系统模型训练、字体分类识别及实验结果分析提供了可靠的数据基础
数据集简介
本项目数据集为中文字体图像数据集,共包含 3840 张图像,划分为训练集、验证集和测试集,涵盖宋体、黑体、楷体、隶书、仿 宋、微软雅黑、等线、华文楷体、华文隶书、华文行楷、方正舒体和方正姚体共 12 个类别。
数据集概述
本研究所使用的数据集为中文字体图像数据集,共包含 3840 张有效图像。该数据集围绕常见中文字体分类任务进行构建与标注, 能够为字体图像的自动识别、分类判断及实验分析提供较为可靠的数据支撑。
按照模型训练与验证需求,本文将数据集划分为训练集、验证集和测试集,其中训练集包含 2880 张图像,验证集包含 480 张图像,测试集包含 480 张图像。该数据划分方式能够为模型参数学习、性能评估以及后续实验分析提供基础支持。
在类别设置方面,数据集共包含宋体(Songti)、黑体(Heiti)、楷体(Kaiti)、隶书(Lishu)、仿宋(Fangsong)、微软雅 黑(Yahei)、等线(Dengxian)、华文楷体(STKaiti)、华文隶书(STLiti)、华文行楷(STXingkai)、方正舒体(FZShuti) 和方正姚体(FZYaoti)12 个类别。所有图像均按照统一的目录结构进行整理,并结合字号变化、倾斜角度变化、图像预处理及样 本增强等操作,为后续深度学习模型训练、字体分类识别和结果分析提供了可靠的数据基础。
数据集来源
本研究所使用的数据集为自主整理构建的中文字体图像数据集,经筛选、生成与预处理后共获得 3840 张有效图像,其中训练集 2880 张、验证集 480 张、测试集 480 张。所有图像均依据字体类别进行统一整理与标注,定义了宋体(Songti)、黑体(Heiti )、楷体(Kaiti)、隶书(Lishu)、仿宋(Fangsong)、微软雅黑(Yahei)、等线(Dengxian)、华文楷体(STKaiti)、华文 隶书(STLiti)、华文行楷(STXingkai)、方正舒体(FZShuti)和方正姚体(FZYaoti)共 12 个类别,并按照统一的数据目录结构和类别映射规则完成数据组织,从而保证了数据标注、分类管理和模型训练过程的一致性。
类别定义
标注规范

图1 标注规范图
性能评测
在 480 张验证集字体图像上,ResNet50 模型取得了较好的分类效果,其 Accuracy 达到 0.91,Weighted F1 达到 0.91,表现出较优的综合性能。结合混淆矩阵与分类结果分析可以看出,系统对宋体、仿宋、等线、华文行楷、方正舒体和方正姚 体等类别具有较高的识别能力,整体分类性能较为稳定。
训练集与验证集准确率、损失变化曲线
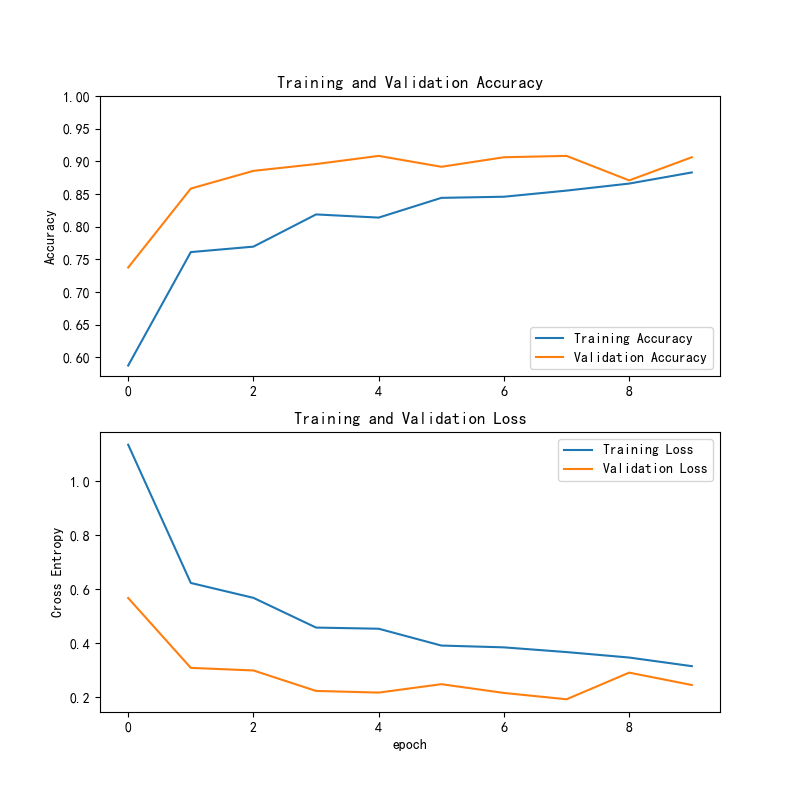
图2 训练集与验证集准确率、损失变化曲线
模型分类结果热力图
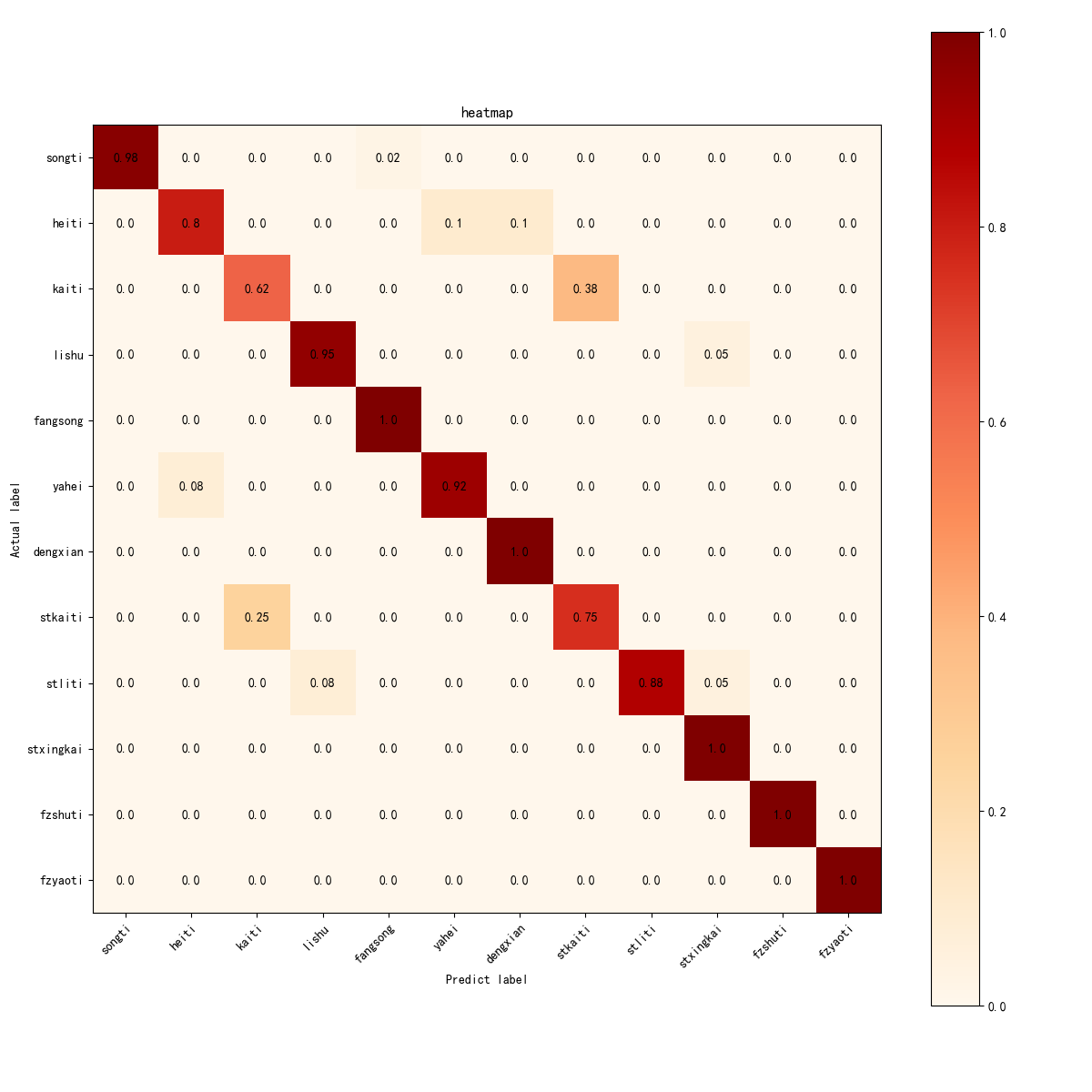
图3 模型分类结果热力图
应用案例
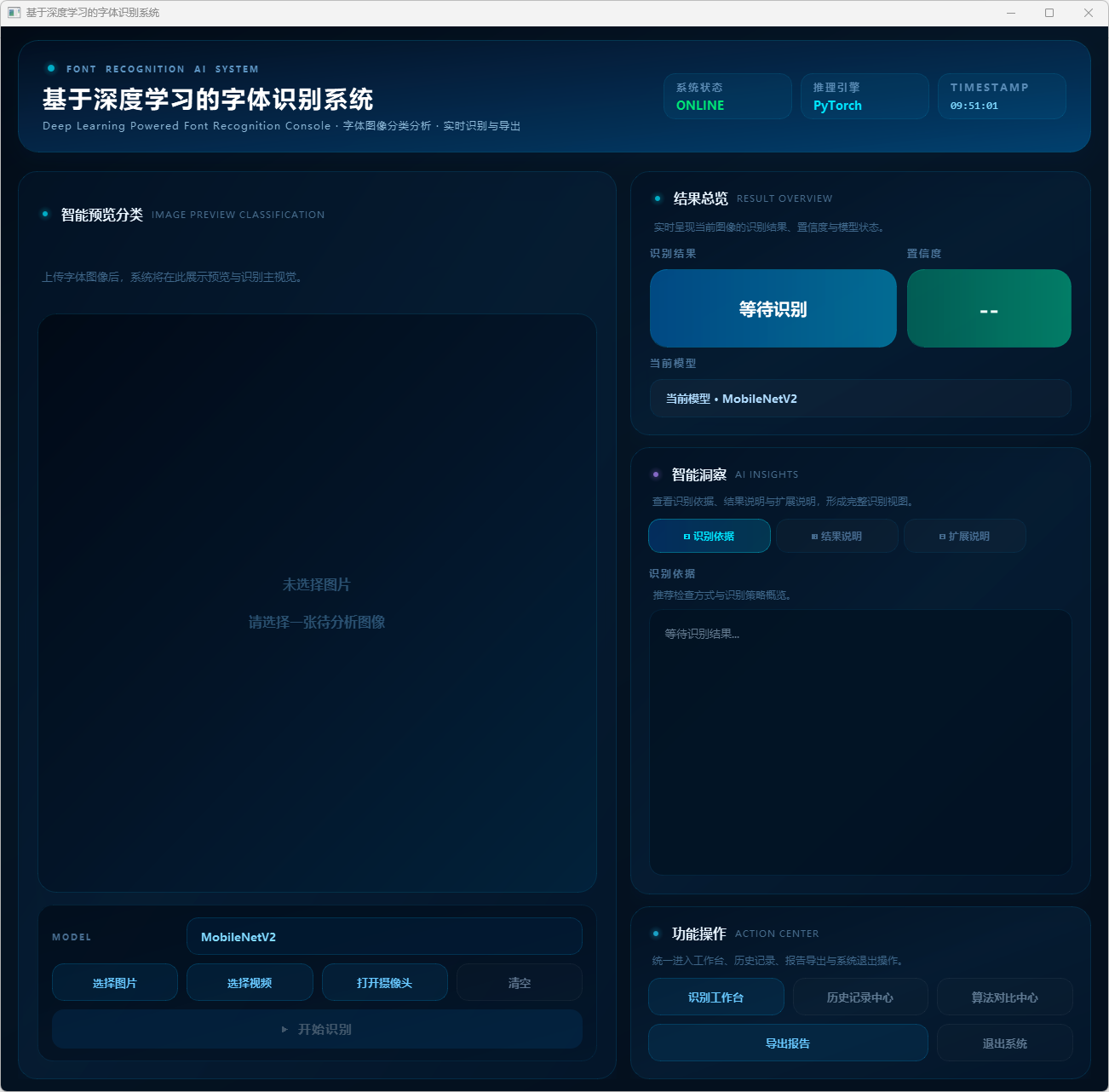
图7 应用案例:基于深度学习的字体识别系统设计与实
免责声明与引用
数据仅用于科研与教学用途。若用于商业场景,请自行核验数据许可。 如需引用,请在论文或报告中注明数据集名称与版本号。
作者信息
作者:Bob (张家梁)
项目编号:Datasets-21
数据大小:7M
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)