

摘要:本研究针对苹果产业园果实数量统计和产量预测中人工清点效率低、主观性强、难以满足规模化管理需求等问题,设计并实现了一套基于深度学习的苹果产量预测系统。系统以苹果图像为研究对象,融合目标检测、特征工程与回归分析方法,实现了图像检测、视频检测、实时检测及产量预测等功能。
数据集简介
本数据集为苹果目标检测数据集,共包含 1822 张图像,涵盖训练集、验证集和测试集,可用于苹果果实检测模型的训练与评估。数据集按照 70:20:10 的比例划分为训练集(1275张)、验证集(364张)和测试集(183张)
数据集概述
本数据集为苹果目标检测数据集,专门用于训练和评估基于深度学习的苹果果实检测模型。数据集共包含 1822 张高质量图像,涵盖不同光照条件、拍摄角度和果实密度的场景,确保模型具有良好的泛化能力。
数据集按照 70:20:10 的标准比例划分为三个子集:训练集(Train)包含 1275 张图像(70.0%),用于模型训练和参数学习;验证集(Validation)包含 364 张图像(20.0%),用于模型调优和超参数选择;测试集(Test)包含 183 张图像(10.0%),用于模型性能评估和泛化能力验证。
数据集中的图像均经过人工标注,每个苹果果实都标注了精确的边界框,标注格式符合 YOLO 系列模型的训练要求。数据集涵盖了果园实际场景中的多种情况,包括果实遮挡、重叠、不同成熟度等复杂情况,为构建鲁棒的苹果检 测模型提供了坚实的数据基础,可广泛应用于苹果产量预测、果园智能管理、农业自动化等领域的研究与开发。
数据集来源
本研究所使用的数据集为苹果目标检测数据集,图像数据来源于果园场景下苹果果实图像的采集、整理与筛选,并在预处理后形成适用 于目标检测任务的数据集。所有图像均采用 YOLO 格式进行边界框标注,目标类别定义为苹果(apple),共计标注了大量实例。整个 标注过程遵循统一规范,以保证数据标注的一致性和准确性,为后续 YOLOv8 模型训练、性能评估以及系统应用提供了可靠的数据支撑。
类别定义
标注规范
标注采用 YOLO 格式:每个目标一行,字段为 class x_center y_center width height, 坐标均为相对归一化(0~1)。
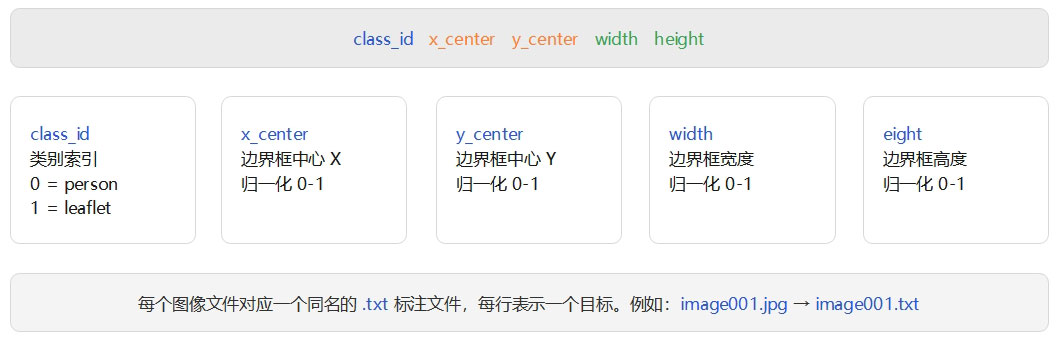
图1 标注规范图
数据规模与划分
- 总图像数:1,822张;总标注框数:8,325个
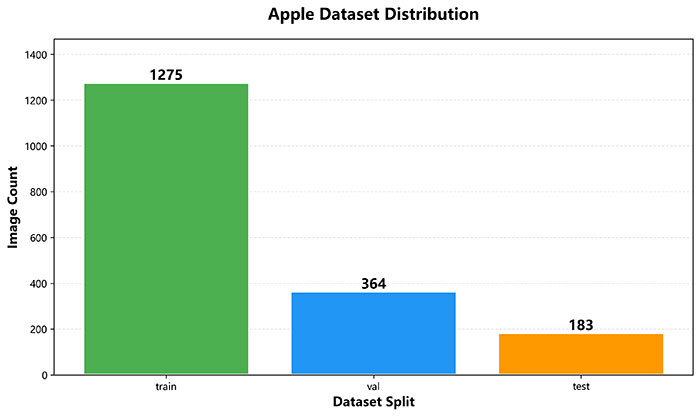
图2 数据集在训练、验证和测试集上的分布
数据集按照约 70:20:10 的比例划分为训练集、验证集和测试集:
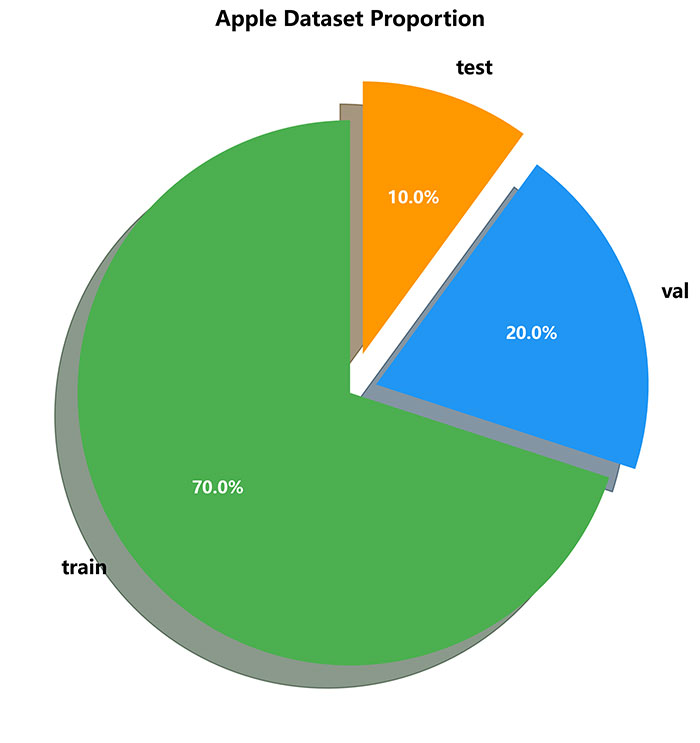
图3 数据集划分及用途说明
质量控制
标注采用双阶段质量控制流程:首先进行规范化标注与自检, 确保目标框贴合实例外接矩形且类别一致;随后进行抽样复核, 针对漏标、错标与框位置偏差进行纠正。对争议样本进行二次确认, 以提高跨标注者一致性与总体标注可靠性。
数据格式与使用
数据集采用标准 YOLO 格式组织,通过 data.yaml 配置文件即可快速集成到训练流程中。
目录结构

数据集采用标准 YOLO 格式组织,图像和标注文件分别存放在 images/ 和 labels/ 目录下,并按训练集、验证集、测试集划分。
性能评测
基于 YOLOv8 模型在本数据集上进行训练和评测,使用mAP@0.5与mAP@0.5:0.95等标准指标对模型检测效果进行评估。评测结果如下:
训练过程综合指标曲线图
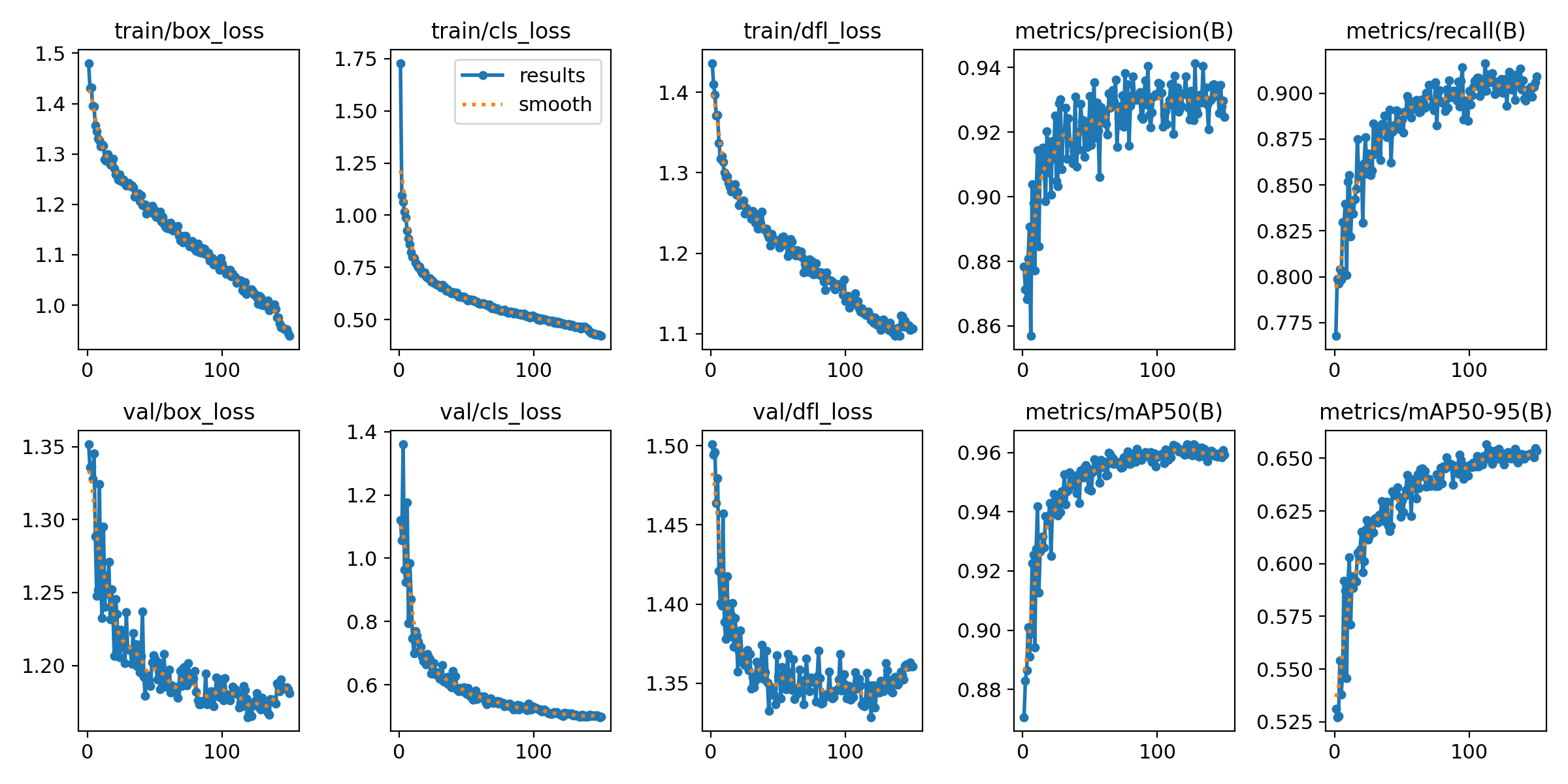
图3 训练与验证指标随Epoch变化趋势图
精确率-召回率(PR)曲线图
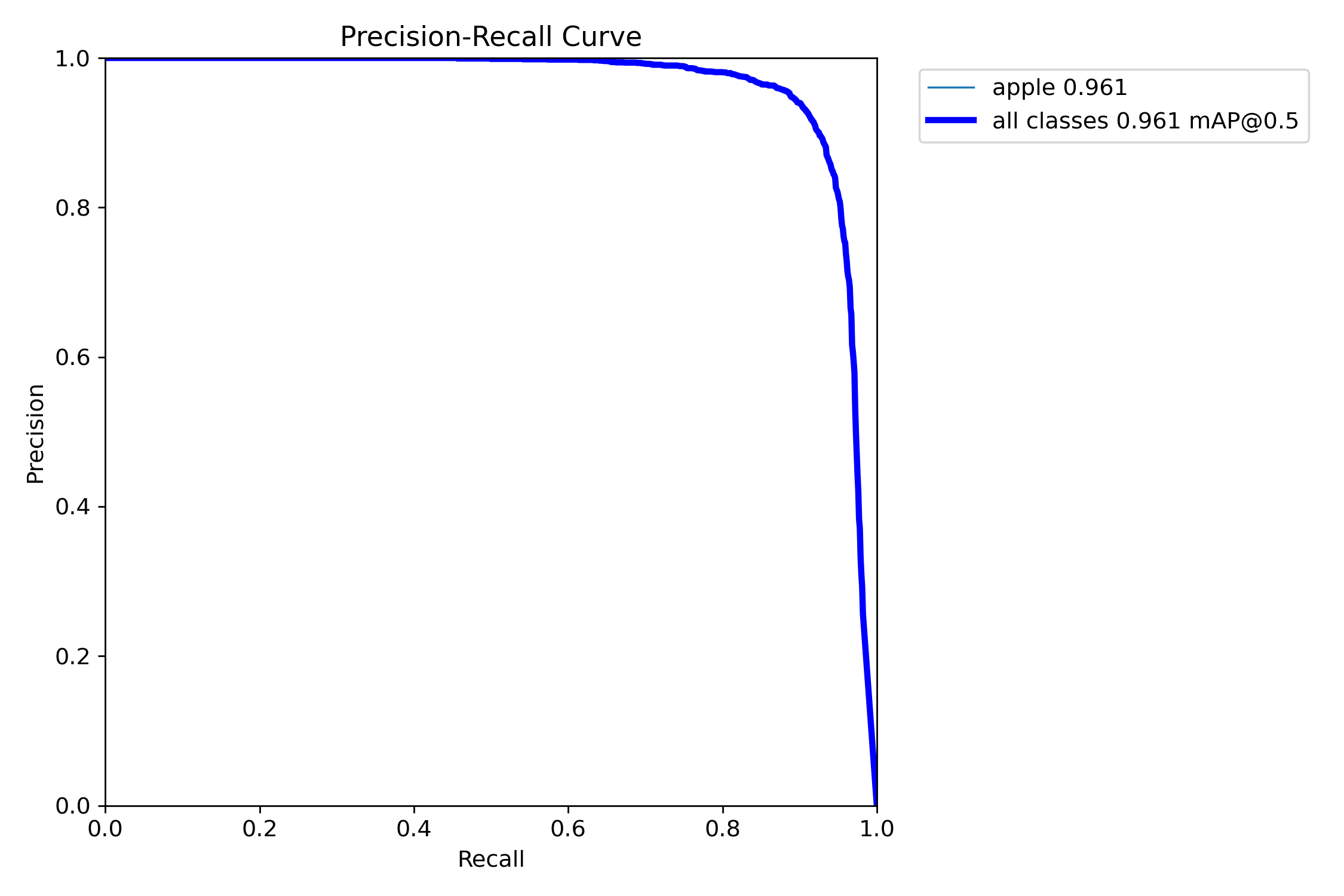
图4 目标检测PR曲线(Precision-Recall)
F1分数-置信度阈值曲线图
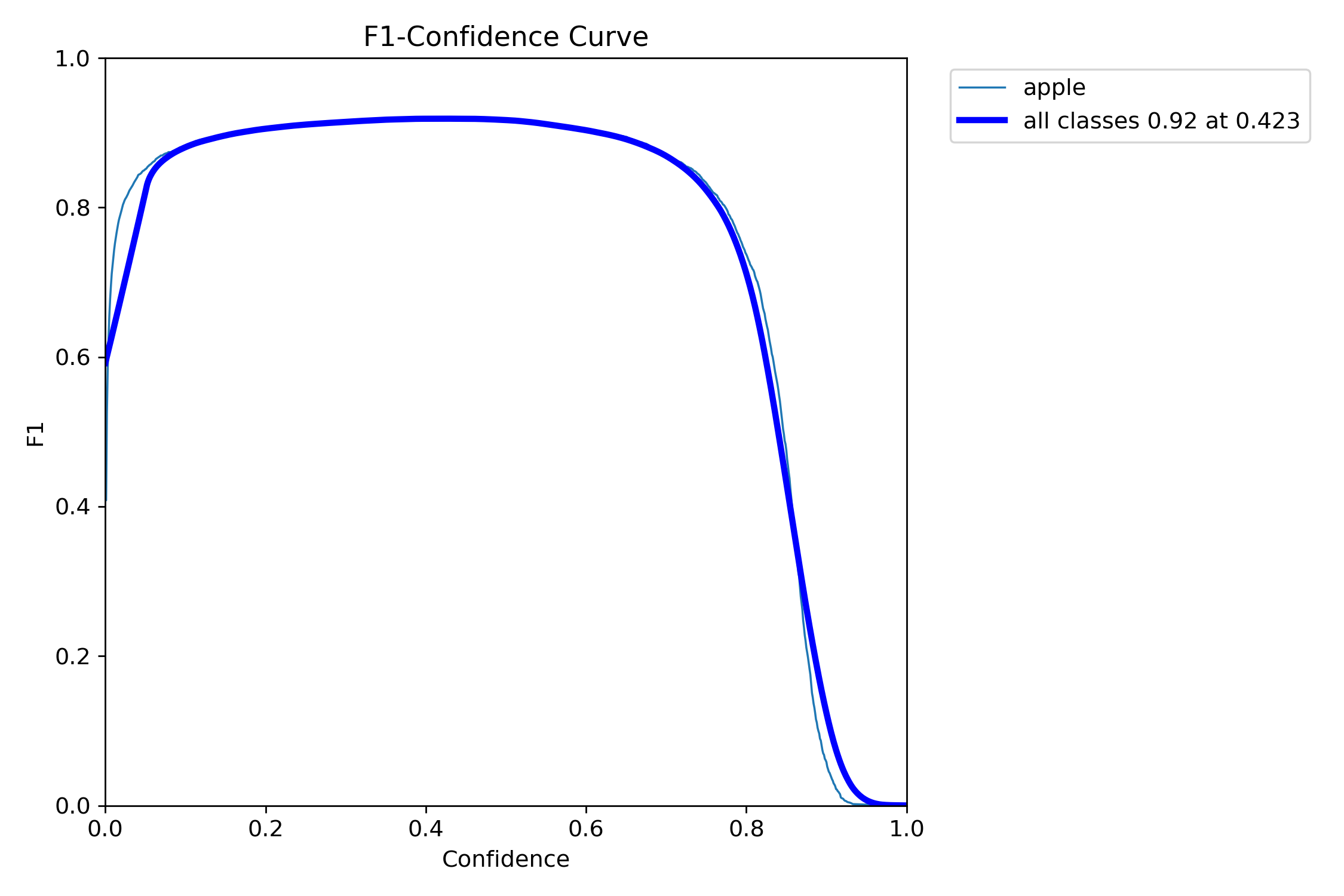
图5 不同置信度阈值下的F1曲线
归一化混淆矩阵图(分类误判分析)
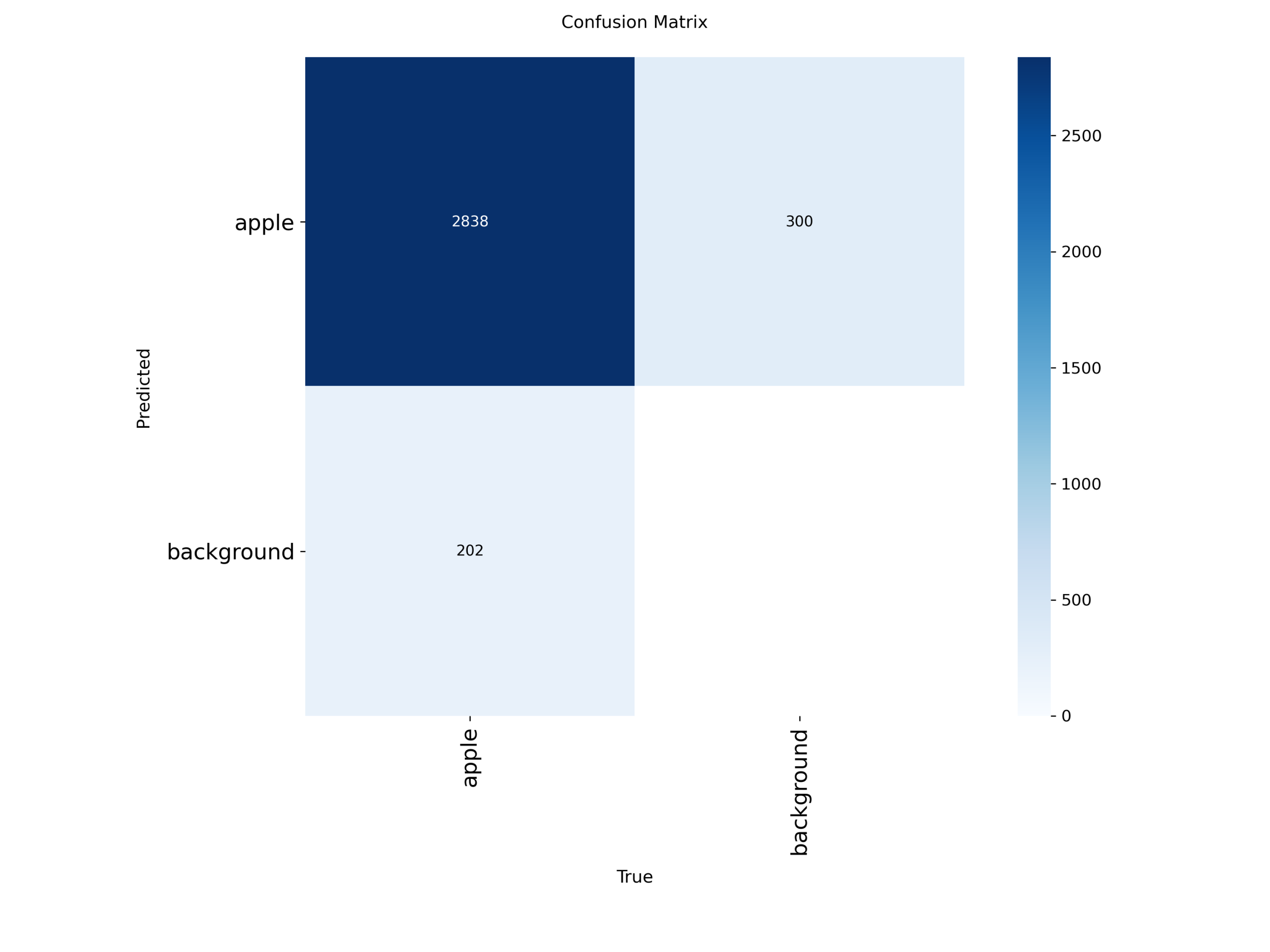
图6 归一化混淆矩阵(person / leaflet)
应用案例
图7 应用案例:基于深度学习的苹果产量预测系统
免责声明与引用
数据仅用于科研与教学用途。若用于商业场景,请自行核验数据许可。 如需引用,请在论文或报告中注明数据集名称与版本号。
作者信息
作者:Bob (张家梁)
项目编号:Datasets-18
数据大小:159M
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)