

摘要:随着人口老龄化加剧,独居老人的居家安全问题日益突出。其中,摔倒是导致独居老人意外伤亡的重要原因之一;由于其在摔倒后往往难以及时获得救助,构建实时、准确的摔倒识别系统具有重要现实意义。
项目简介
一个基于YOLO11人体检测、AlphaPose骨骼关键点提取和ST-GCN时序动作分类的实时独居老人摔倒识别系统,支持摄像头监控、自动报警与日志记录。
系统概述
随着人口老龄化加剧,独居老人的居家安全问题日益突出,摔倒是导致独居老人意外伤亡的主要原因之一。由于独居老人摔倒后往往无法及时获得救助,实时准确的摔倒识别系统对于保障其生命安全具有重要现实意义。
本文设计并实现了一套基于YOLO11-AlphaPose-STGCN的独居老人摔倒识别系统,构建了”人体检测—姿态估计—动作识别”三阶段级联处理框架。在人体检测阶段,采用YOLO11轻量化目标检测模型实现视频帧中的人体定位,并结合卡尔曼滤波与匈牙利算法进行多目标跟踪以维持身份一致性;在姿态估计阶段,利用AlphaPose(FastPose-ResNet50)提取每个目标的17个二维骨骼关键点坐标;在动作识别阶段,将连续30帧的骨骼序列输入双流时空图卷积网络(Two-StreamST-GCN),同时建模关节位置与关节运动速度特征,实现对站立、行走、坐下、躺下、起立、坐下及摔倒共7类动作的分类识别。系统基于PySide6设计了图形化操作界面,支持视频文件与实时摄像头输入,并实现了摔倒报警与日志记录功能。
在自建的室内场景数据集上进行实验,结果表明该系统在保持实时处理速度的同时,对摔倒动作具有较高的识别准确率和召回率,能够有效区分摔倒与躺下等相似动作,可为独居老人居家安全监护提供一套完整、实用的技术解决方案。
系统架构
系统采用表示层(PySide6界面)、算法层(YOLO11n检测→卡尔曼跟踪→AlphaPose姿态估计→双流ST-GCN动作识别)、报警层(多帧确认+语音/邮件/红框三重联动)、数据层(SQLite+JSONL日志)四层架构。
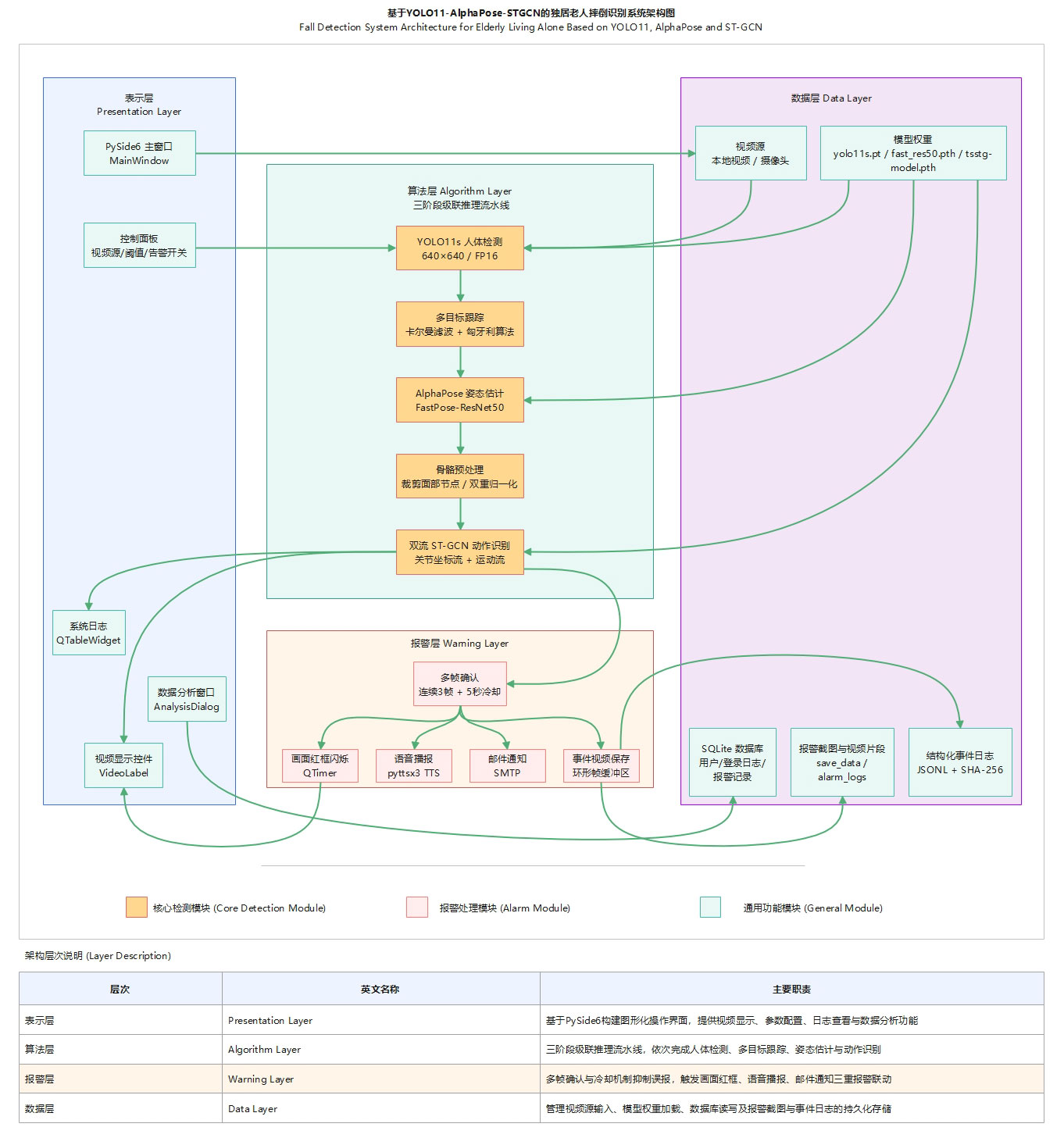
图1 基于YOLO11-AlphaPose-STGCN的独居老人摔倒识别系统架构图
核心亮点
双流ST-GCN同时建模关节位置与运动速度特征,结合多帧确认与冷却机制,有效区分摔倒与躺下等相似动作,降低误报率。
算法特点
系统在算法层面采用空间配置分区策略将邻居节点按与重心的拓扑距离划分为三个子集分别卷积,每层引入可学习边重要性权重自适应调节骨骼连接贡献度;骨架拓扑裁剪眼耳4个面部节点保留14个躯干四肢节点并构造虚拟颈部节点以降低噪声;输入序列经图像尺寸归一化与姿态尺度归一化消除位置偏移与尺度变化影响;网络由10层图卷积模块沿64→128→256渐进升维,配合残差连接与时间步长下采样逐层提取高层次时空特征。
性能特点
系统采用 YOLO11n 以 FP16 半精度进行 640×640 人体检测降低前端计算开销,骨架图裁剪至 15 节点减少图卷积复杂度,双流 ST-GCN 并行提取坐标与运动特征拼接为 512 维向量完成 7 类分类,以 30 帧滑动窗口覆盖约 1 秒动作片段兼顾时效与时序信息,三模型全程部署于同一 GPU 端到端推理,配合 3 帧确认与 5 秒冷却机制有效抑制误报,实现实时摔倒识别。
技术价值
系统采用骨骼关键点而非原始图像进行动作识别,降低计算量的同时规避隐私问题;工程上将 YOLO11、AlphaPose、ST-GCN 三模型整合为 GPU 实时流水线,配合卡尔曼滤波跨帧跟踪保证多人场景连续性;应用上集成语音、邮件、画面三重报警与冷却防误报机制,结合日志 记录与数据分析形成检测到追溯的完整闭环,可为独居老人居家监护及智慧养老场景提供低成本、可扩展的技术支撑。
核心技术
系统围绕”检测—跟踪—姿态估计—动作识别”四环节展开:YOLO11n 以 FP16 半精度实时检测行人,卡尔曼滤波结合匈牙利算法维持跨帧身份一致性,AlphaPose-ResNet50 提取关键点并构建 14 节点精简骨架,双流 ST-GCN 对 30 帧骨骼序列分别提取坐标特征与运动特征后融合输出 7 类动作概率,整条流水线在 GPU 上端到端实时运行。
YOLO11目标检测算法
本系统采用YOLO11n作为人体检测的前端模型。YOLO(You Only Look Once)是一种单阶段目标检测算法,将目标定位与分类统一 为一次前向传播完成,具有速度快、精度高的特点。系统中将YOLO11n的检测类别限定为单类别(person,class=0),输入分辨率 设置为640×640,置信度阈值为0.25,IoU阈值为0.45,在GPU设备上开启FP16半精度推理以降低计算延迟。每一帧图像经YOLO11n处 理后,输出所有检测到的人体边界框坐标(xyxy格式)、置信度分数及类别标签,为后续的姿态估计提供精确的人体裁剪区域。
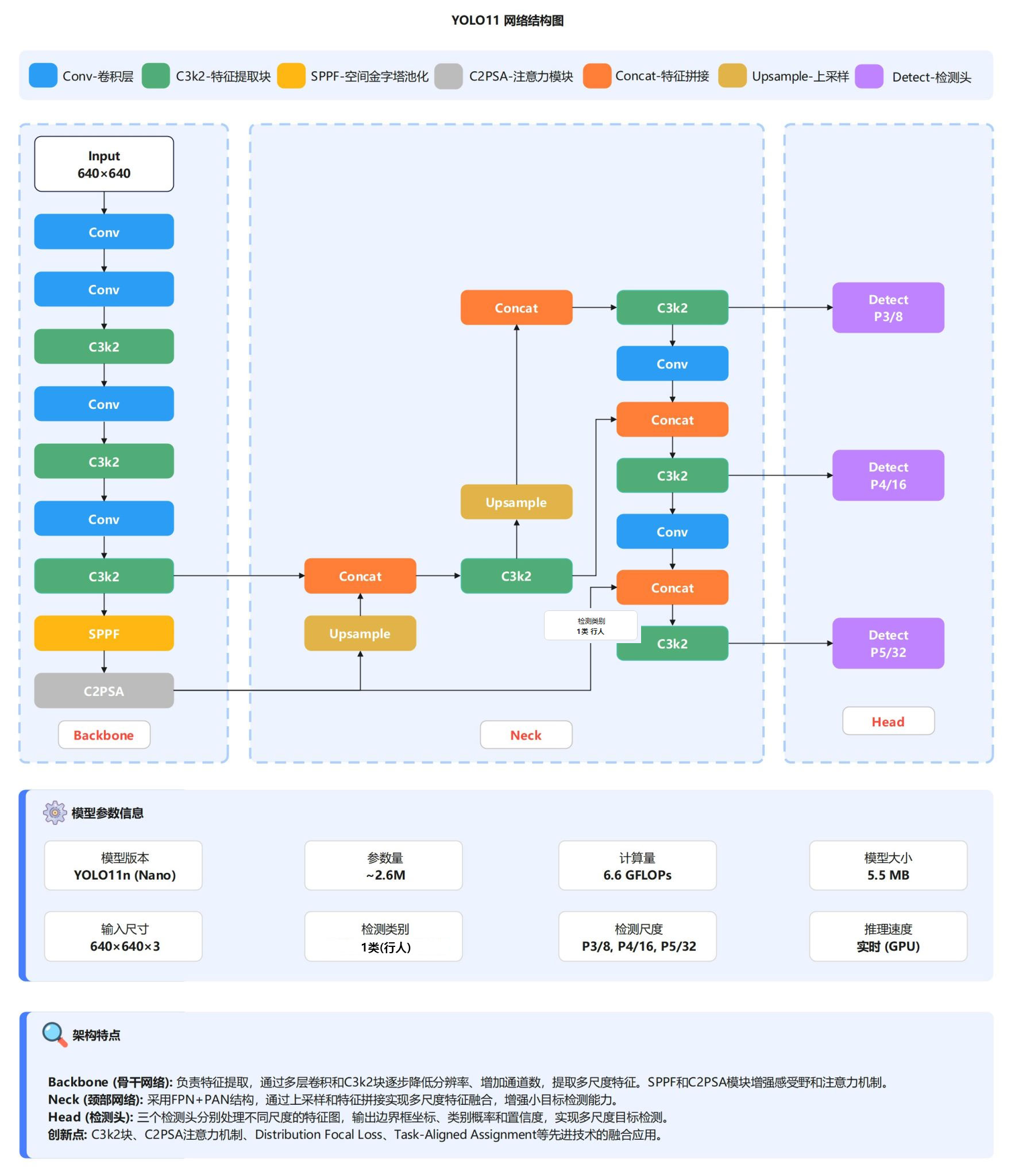
图2 YOLO11网络架构图
卡尔曼滤波与匈牙利算法(多目标跟踪)
为保证同一行人在连续帧间的身份一致性,系统采用卡尔曼滤波与匈牙利算法相结合的多目标跟踪方案。卡尔曼滤波器维护一个8维状态空间(中心坐标x、y,宽高比a,高度h及其对应速度vx、vy、va、vh),基于匀速运动模型对每个跟踪目标的下一帧位置进行预测,并在获得新的检测观测后通过测量更新步骤修正状态估计,其中过程噪声和观测噪声的标准差均与目标高度成正比,实现了自适应的不确定性建模。在数据关联阶段,系统采用级联匹配策略:首先对已确认轨迹按丢失时长优先级进行IoU代价的匈牙利匹配,未匹配的轨迹与未确认轨迹再进行二次匹配,最大IoU距离阈值设为0.7。新检测目标需连续匹配成功5次方可确认为有效轨迹,丢失超过30帧的轨迹将被删除。每个轨迹维护一个容量为30帧的骨骼关键点双端队列,为动作识别提供时序输入。
AlphaPose姿态估计算法
姿态估计环节采用AlphaPose框架中的FastPose模型,骨干网络为ResNet50,输入尺寸为224×160。该模型属于自顶向下(Top-Down)的姿态估计方案:首先根据YOLO11输出的人体边界框对原图进行仿射变换裁剪,将每个人体区域缩放至统一尺寸后送入网络,输出各关键点的热力图(Heatmap)。系统在热力图层面直接裁剪掉左右眼和左右耳共4个面部通道(保留鼻子),仅保留13个躯干及四肢关键点,随后通过热力图解码获取二维坐标及置信度分数。解码后的关键点经姿态非极大值抑制(PoseNMS)去除冗余检测,最终输出每个人体的关键点坐标数组及对应分数,供后续动作识别模块使用。
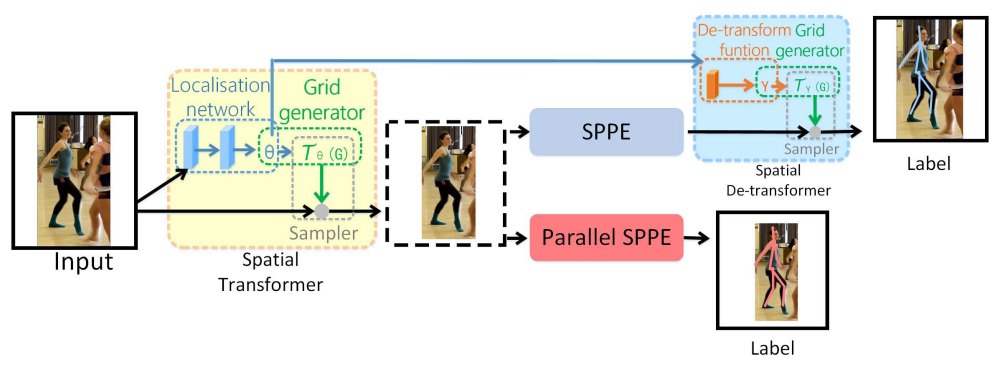
图3 AlphaPose 多人姿态估计架构图
双流时空图卷积网络(Two-Stream ST-GCN)
动作识别模块将骨骼序列经双重归一化与虚拟颈部节点构造后形成 15 节点×3 通道×30 帧的坐标张量,运动流由相邻帧差值得到 2 通道×29 帧张量,两路分别输入 10 层 ST-GCN 网络(通道 64→128→256),每层通过空间配置分区图卷积与核大小为 9 的时间卷积提取时空特征,配合可学习边重要性权重、残差连接与 Dropout 正则化,最终两路 256 维特征拼接经全连接层与 Sigmoid 激活输出 7 类动作概率。
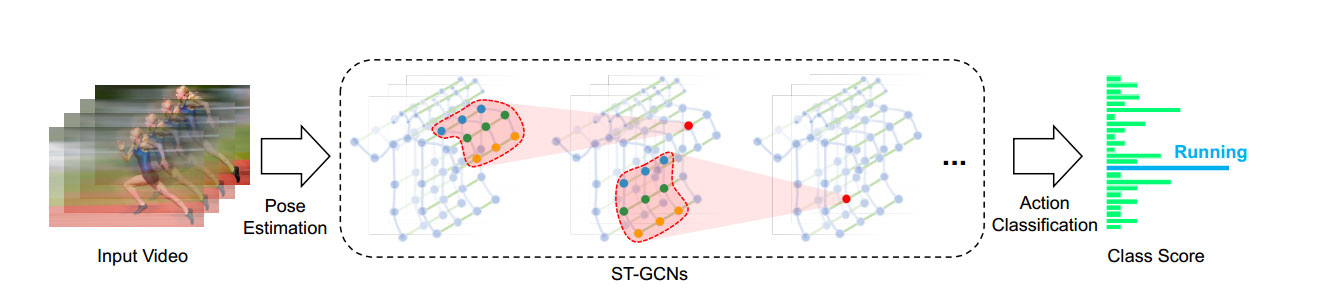
图4 ST-GCN的网络结构图
性能表现
系统采用 YOLO11 实时检测行人、AlphaPose 提取 13 个骨骼关键点、双流 ST-GCN 基于 30 帧时序识别 7 类动作(验证准确率 97.26%),配合 Kalman 滤波多目标跟踪维持人员 ID,检测到摔倒后通过多帧确认与冷却机制触发语音、邮件及视频片段录制三重报警,整体流水线在 GPU 上可达实时推理帧率。
模型性能分析
YOLO11n 以 640×640 输入实时检测行人并输出边界框,AlphaPose(ResNet50 backbone)对每个检测框提取 13 个关键点坐标与置信度,双流 ST-GCN 将连续 30 帧骨骼序列分为坐标流(x, y, score)和运动流(Δx, Δy)分别经 10 层时空图卷积后融合分类,最终 7 类动作验证准确率 97.26%、训练损失 0.1564,三级模型串联在 CUDA 设备上可维持实时处理帧率。
性能优势总结
双流架构同时捕获静态姿态与动态运动特征,Spatial 图分区策略建模关节间拓扑关系,标签平滑与关键点置信度加权提升了训练鲁棒性,训练与验证准确率仅差 1.45% 表明泛化能力强,三级流水线(检测→姿态→识别)解耦设计使各模块可独立优化替换。
系统功能
支持视频文件与摄像头双模式输入,实时识别7类人体动作并在检测到摔倒时触发画面红框、语音播报、邮件通知三重报警,同时提供用户登录管理、报警截图与事件视频自动保存、结构化日志记录及可视化数据分析功能。
功能概述
本系统实现了从视频输入到摔倒报警的完整功能闭环。在输入端,支持本地视频文件与电脑摄像头两种视频源接入方式。在识别端,系统对视频流进行实时处理,逐帧完成人体检测、骨骼关键点提取与动作分类,可识别站立、行走、坐着、躺下、起立、坐下及摔倒共7类动作。在报警端,当检测到摔倒动作时,系统经多帧确认后触发画面红框闪烁、语音播报及邮件通知三重报警联动,并自动保存报警截图与事件前后各5秒的视频片段。在管理端,系统提供用户登录与注册、检测阈值调节、告警开关配置、系统日志实时查看及历史报警数据的可视化统计分析功能。
系统架构
本系统采用 Python 3.12 开发,基于 Ultralytics YOLOv11 深度学习框架实现目标检测,使用 PySide6 (Qt for Python) 构建现代化图形用户界面,通过 OpenCV 进行图像和视频处理,采用 DetectWorker 多线程异步处理技术保证界面流畅性,并使用 SQLite 数据库实现数据持久化存储和查询,系统架构清晰、模块化设计,便于功能扩展和维护。
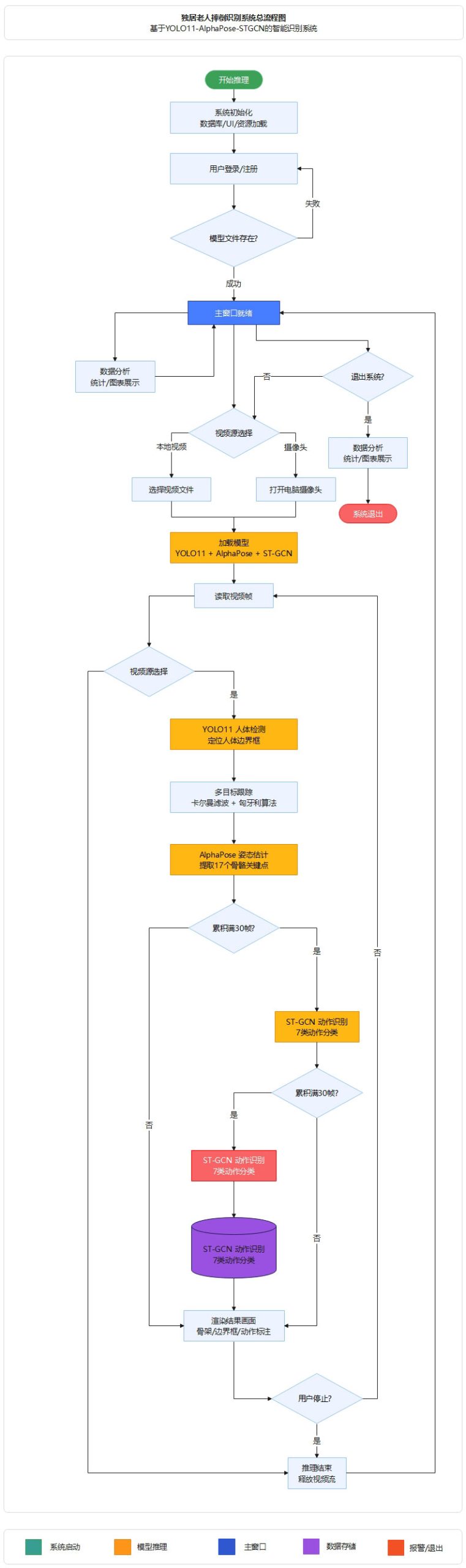
图5 基于YOLO11-AlphaPose-STGCN的独居老人摔倒识别系统总流程图
系统优势
本系统基于骨骼关键点进行动作分类,不依赖人体外观特征,天然保护被监护者隐私;双流ST-GCN联合建模姿态形态与运动速度,有效区分摔倒与躺下等易混淆动作;三阶段级联架构全程GPU部署,满足实时处理需求;多帧确认与多级冷却机制逐层抑制误报;事件视频自动保存与SHA-256校验日志形成完整证据链;PySide6图形界面集成检测、报警、管理与数据分析功能,开箱即用,部署成本低,适用于独居老人居家监护与养老机构智能管理等场景。
运行展示
系统运行后通过PySide6主界面实时展示视频画面、骨骼姿态叠加、动作分类结果及FPS帧率,摔倒时画面边框红色闪烁并在日志区同步输出报警记录
登录和注册
图6 登录主界面
图7 用户注册主界面
图8 管理员注册主界面
检测效果展示
系统运行模块:
图9 系统运行界面
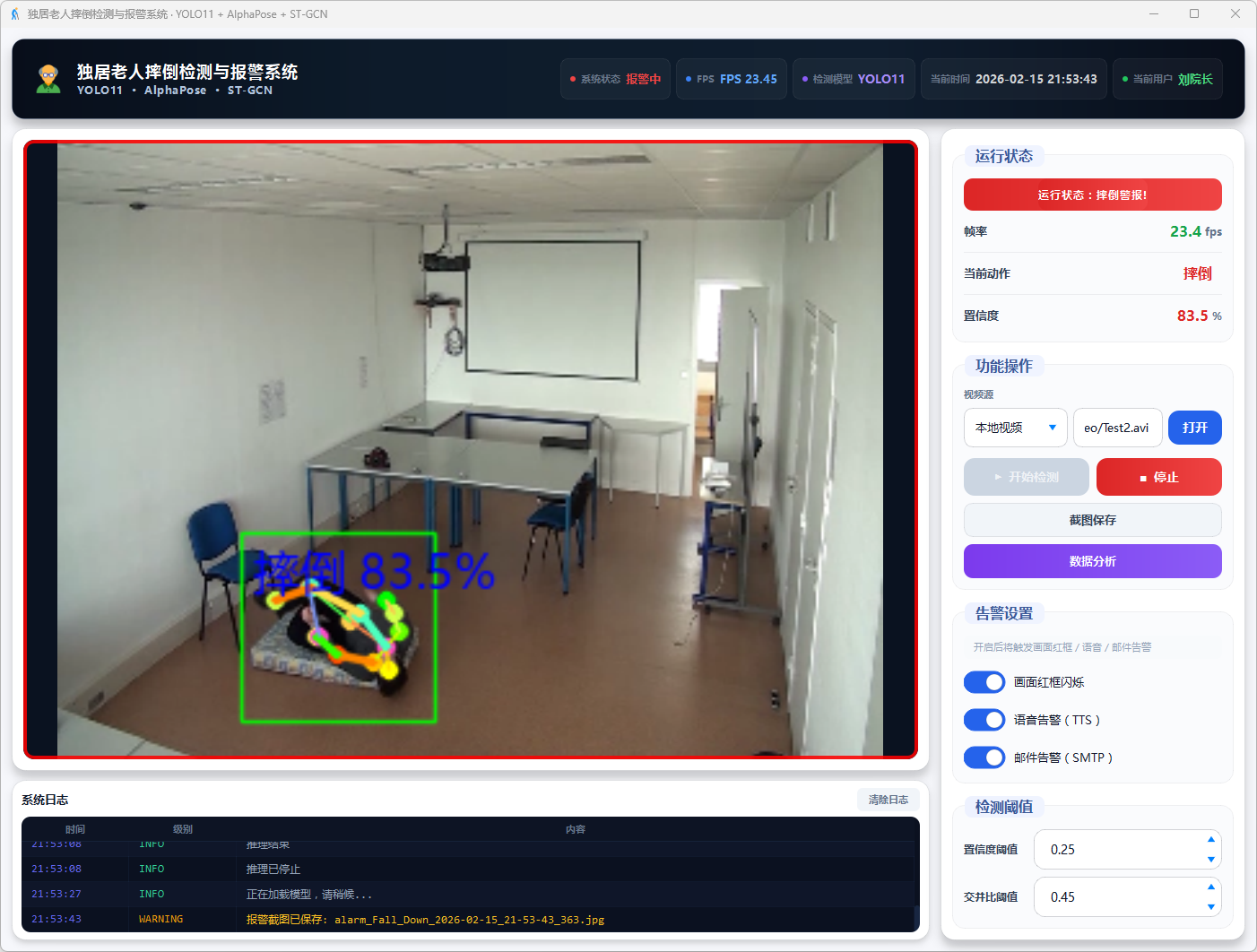
图10 视频检测:摔倒警告
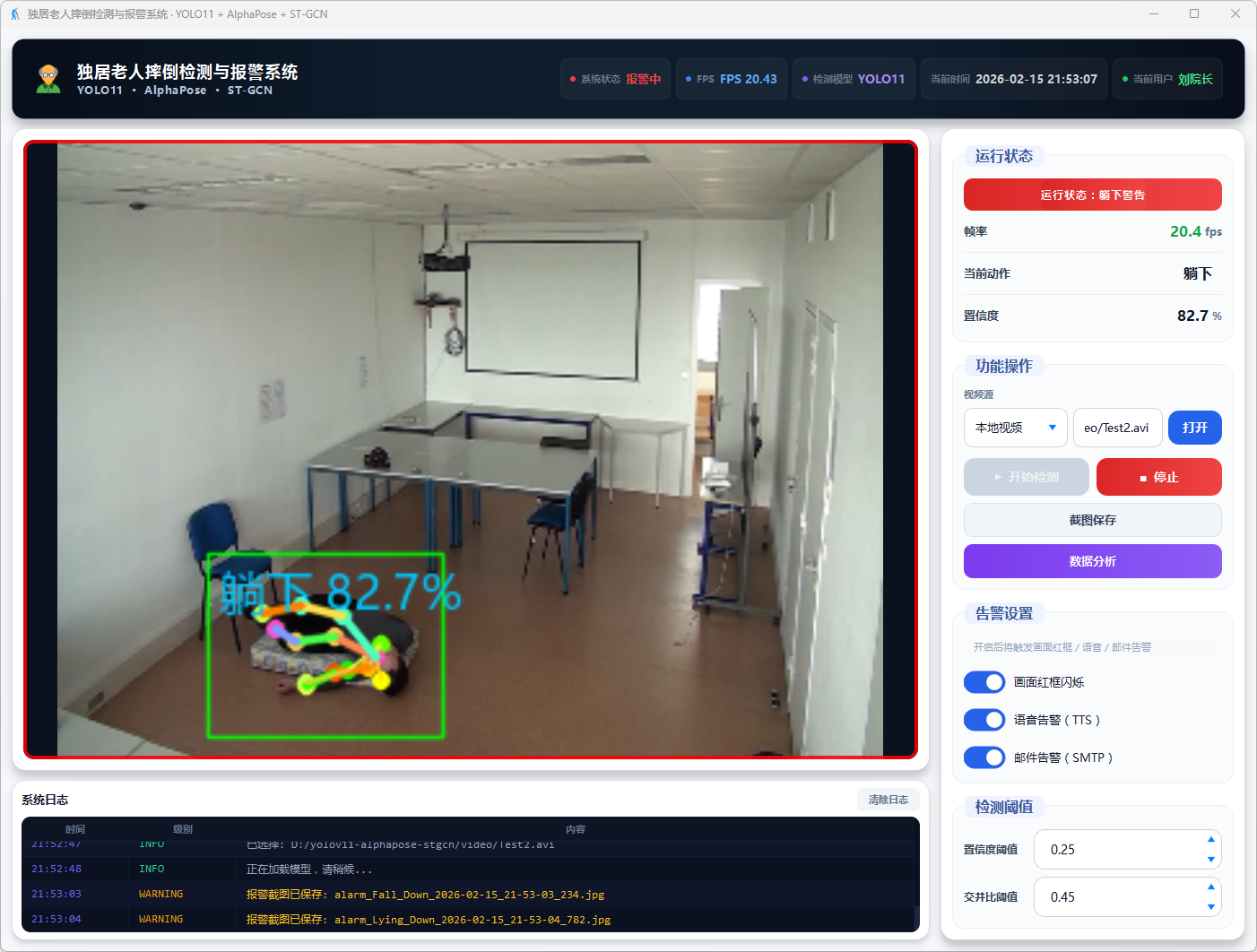
图11 视频检测:躺下警告

图12 实时检测:摔倒警告

图13 实时检测:躺下警告
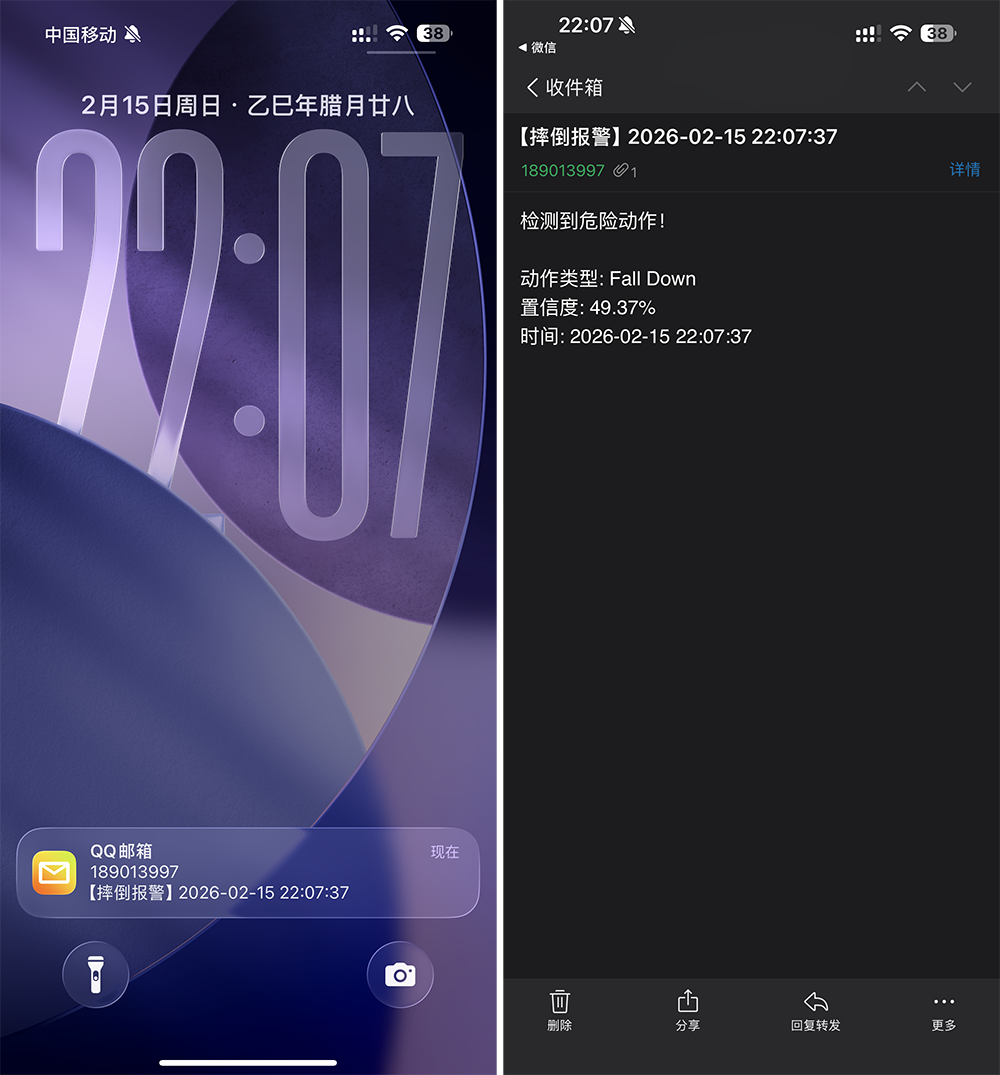
图14 邮件报警
数据分析模块:
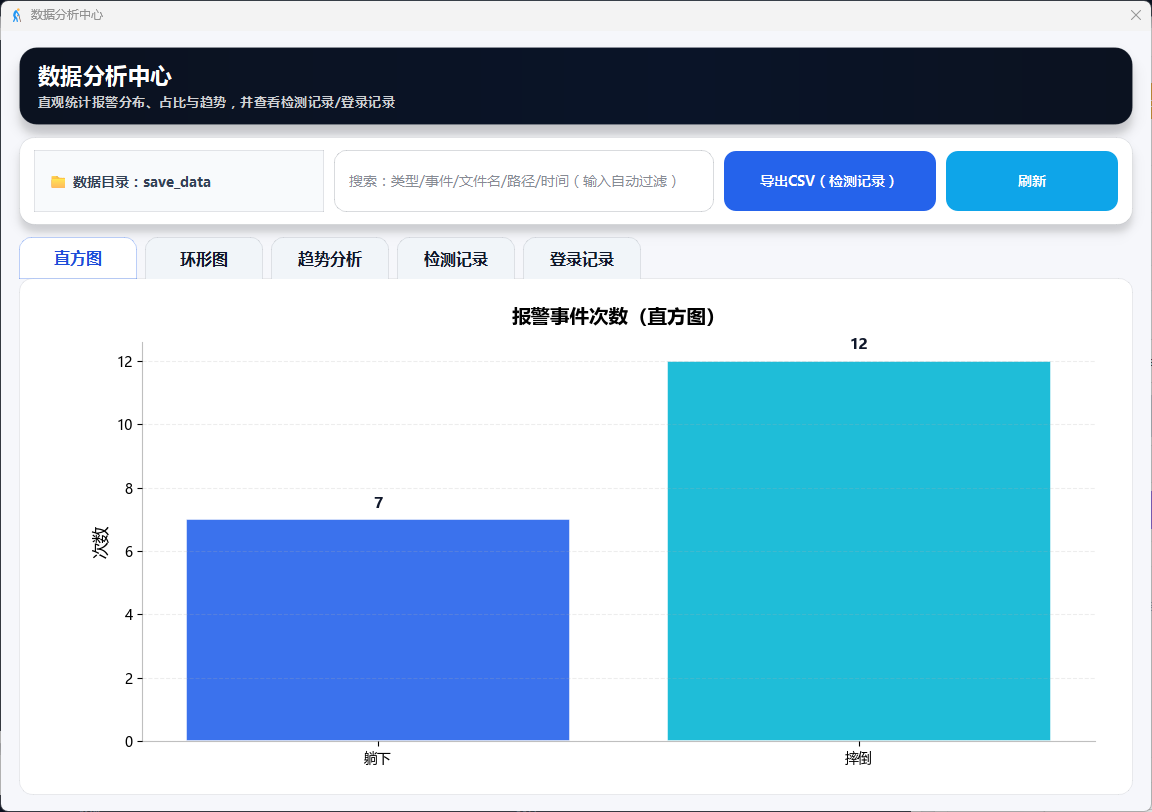
图15 数据分析:直方图
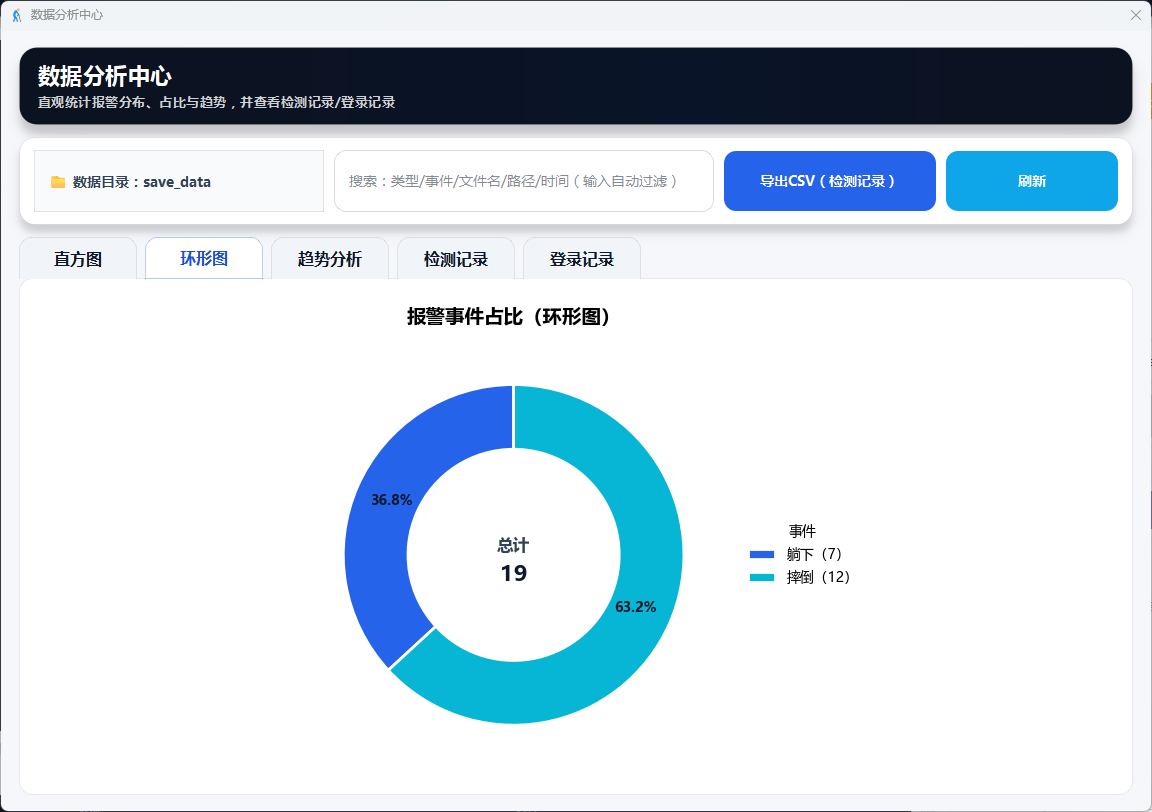
图16 数据分析:环形图
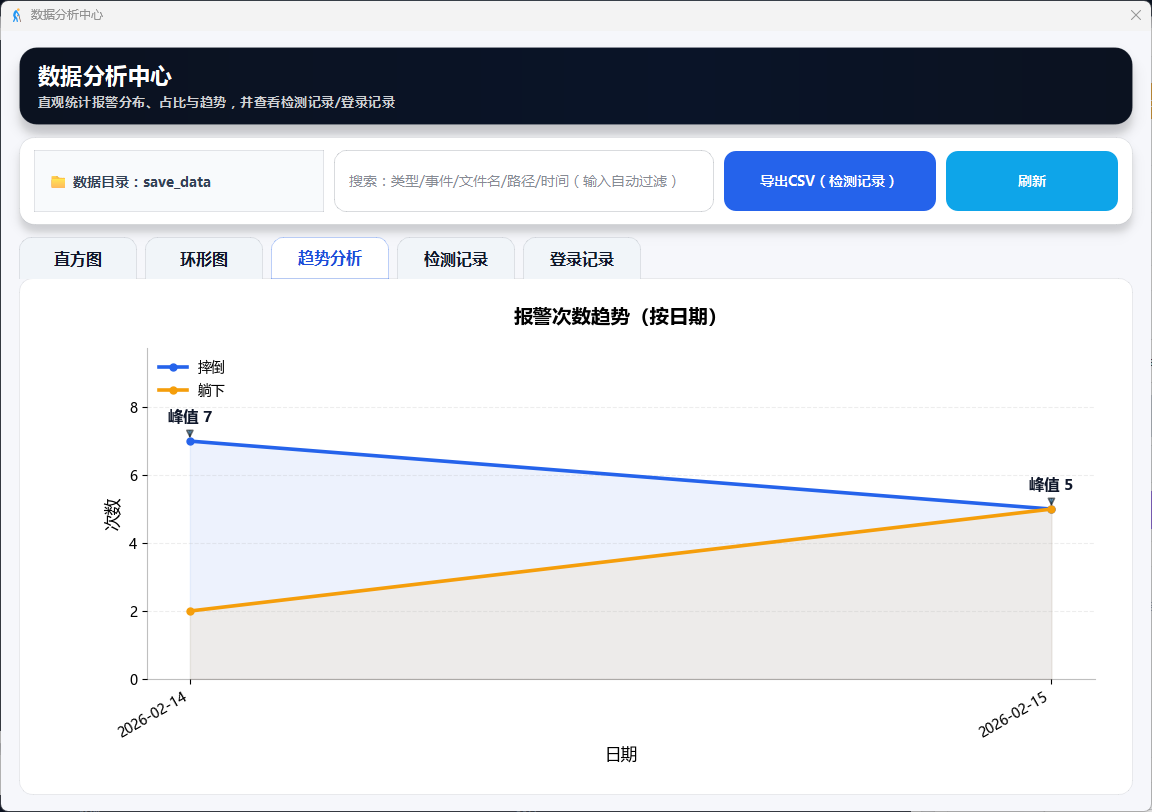
图17 数据分析:趋势分析
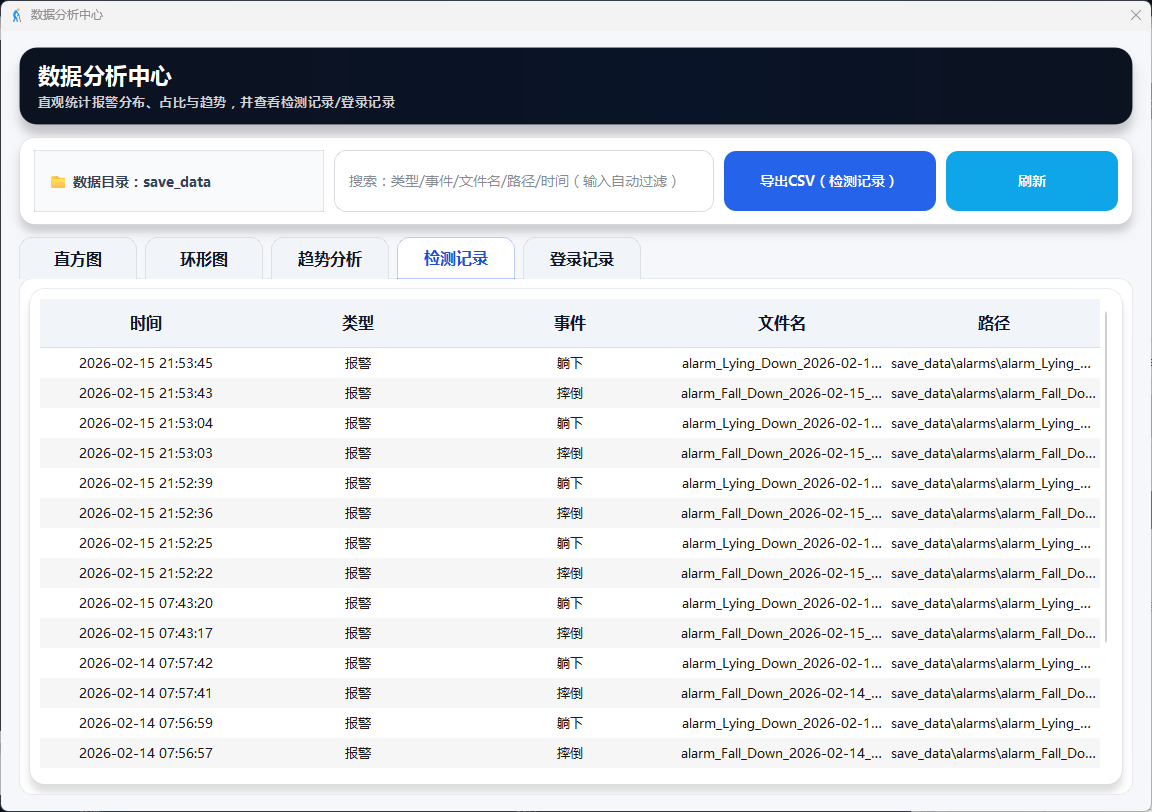
图18 数据分析:检测记录
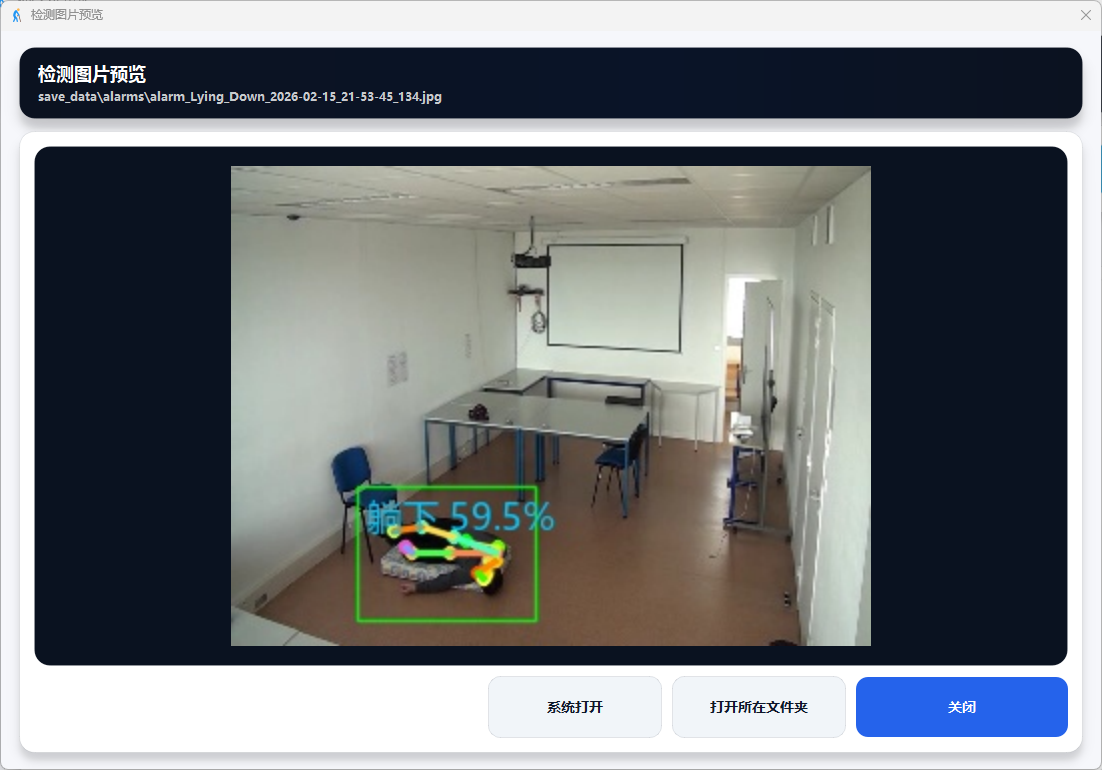
图19 数据分析:检测图片预览
图20 数据分析:登录记录
图21 数据分析:导出检测记录
数据集与训练
数据集采用咖啡室和家庭两个场景的人体骨骼关键点数据,包含 7 类动作标注,经滑动窗口切片为 30 帧时序样本,使用 Adadelta 优化器和 BCELoss 训练双流 ST-GCN 模型 30 轮。
数据集构建
数据集由 AlphaPose 从咖啡室和家庭两个场景视频中提取 13 个人体关键点的坐标与置信度,人工标注 7 类动作标签后,经去除 NaN 帧、标签平滑(esp=0.1)、骨骼点归一化(scale_pose)、主要关键点(肩部与髋部)置信度加权×1.5,再以 30 帧为窗口滑动切片,最终生成形状为(N, 30, 14, 3)的时序骨骼样本与对应的 one-hot 标签。
训练流程
模型训练采用端到端的方式,首先加载训练集和验证集进行数据预处理,然后加载YOLOv11预训练权重进行模型初始化,接着使用SGD优化器进行150轮迭代训练,每轮训练后在验证集上评估性能指标,系统自动保存验证集上性能最佳的模型权重,最终输出完整的性能指标和训练曲线。
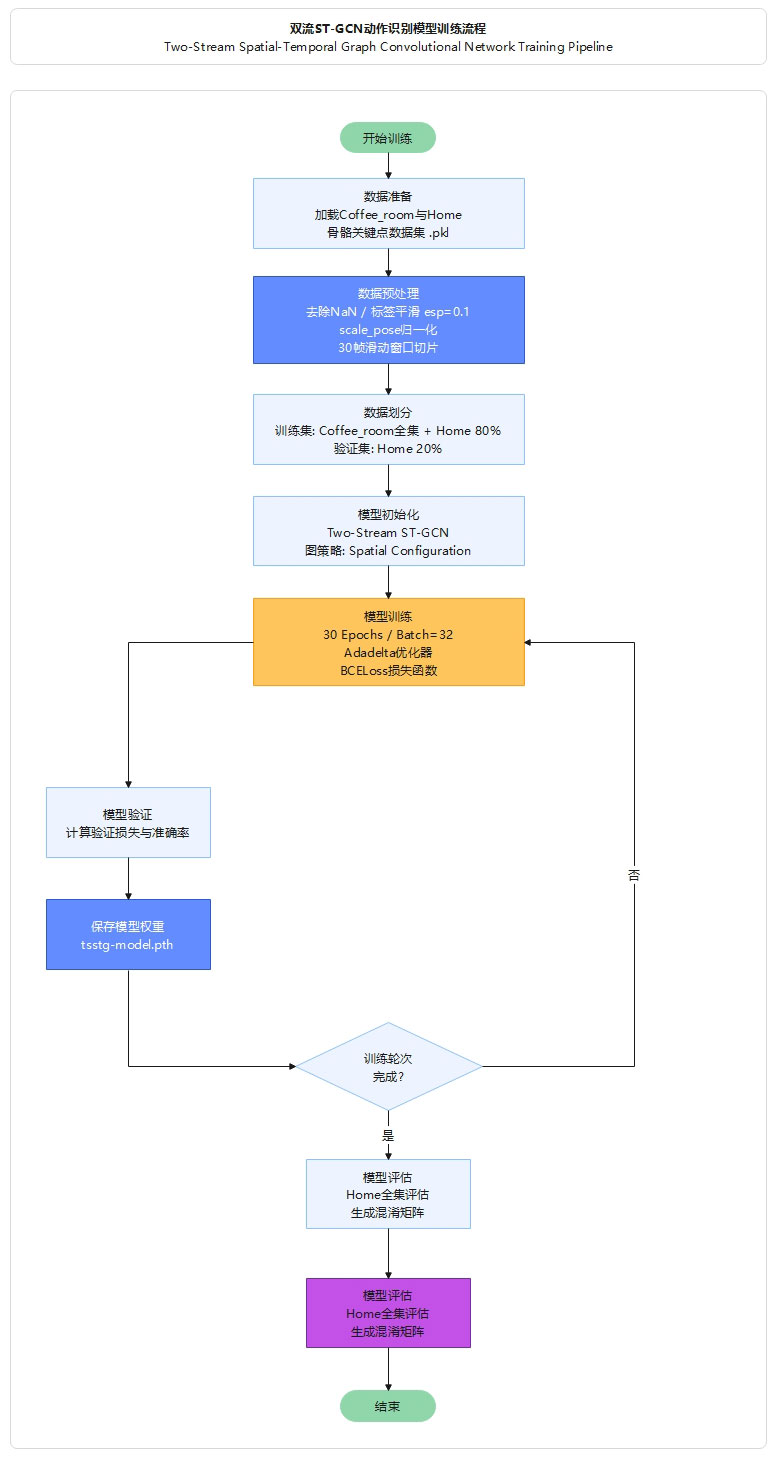
图21 模型训练流程
训练配置
硬件环境:

软件环境

训练结果
核心指标概览:
模型经 30 轮训练后,训练准确率达 98.71%,验证准确率 97.26%,验证损失收敛至 0.1726,训练与验证差距约 1.45%,无明显过拟合。

训练曲线分析:
训练损失与验证损失均在前 10 轮快速下降后趋于平稳,最终分别收敛至 0.1564 和 0.1726,两条曲线走势一致且间距较小,表明模型泛化能力良好。
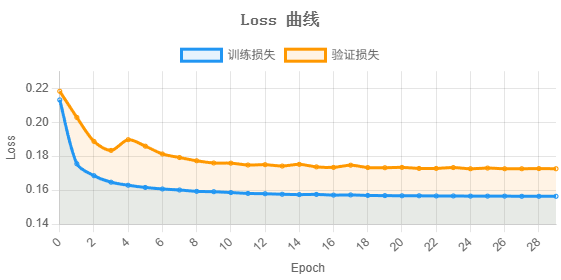
图22 训练/验证损失曲线
训练准确率与验证准确率在前 10 轮快速攀升后进入平台期,最终分别稳定在 98.71% 和 97.26%,两条曲线紧密贴合,表明模型未出现过拟合
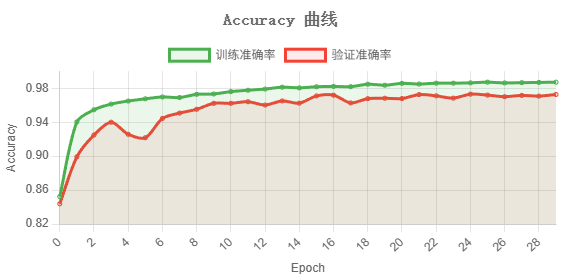
图23 准确率曲线
训练稳定性分析
验证准确率在 Epoch 4-5 出现约 2% 的短暂回落(94.00%→92.17%),随后迅速恢复并持续上升,后 15 轮在 96.8%~97.3% 区间内小幅波动,整体训练过程稳定收敛,无震荡或发散现象。
项目资源
我们提供项目的完整技术资源,包括源代码、训练脚本、配置文件、数据集和模型权重等全部内容。代码采用模块化设计,结构清晰,注释完善,支持完全复现论文中的所有实验结果。项目提供详细的文件清单和技术架构说明(网页已经提供),帮助用户快速理解项目结构,便于二次开发和功能扩展。所有资源均已开源,遵循AGPL-3.0协议,用户可自由使用、修改和分发。

关于项目
本项目是一套基于 YOLO11 + AlphaPose + 双流 ST-GCN 的独居老人摔倒检测与报警系统,通过实时视频流完成行人检测、骨骼关键点提取和 7 类动作识别,检测到摔倒后自动触发画面红框闪烁、语音播报和邮件通知三重报警。
项目背景
随着我国老龄化加剧,独居老人摔倒后无法及时求助已成为突出的安全隐患,亟需一种基于计算机视觉的实时摔倒检测与自动报警系统来降低意外伤害风险。
作者信息
作者:Bob (张家梁)
项目编号:YOLO_4
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)