

摘要:糖尿病是一种常见的慢性代谢性疾病,其早期预测与干预对于降低发病率和死亡率具有重要意义。随着医疗数据的快速积累,利用机器学习方法对糖尿病进行预测成为研究热点。本文基于 Pima Indians Diabetes 数据集,构建并比较了多种机器学习模型,包括逻辑回归、支持向量机、朴素贝叶斯、决策树、随机森林、梯度提升等。通过交叉验证与网格搜索进行模型评估与调参,结果表明支持向量机与梯度提升模型在预测准确率与稳定性方面表现最佳。进一步利用特征标准化与集成学习方法,有效提升了模型的泛化能力。研究结果显示,机器学习能够在糖尿病预测中提供可靠的辅助决策支持,对临床诊断与公共健康管理具有一定应用价值。
项目信息
编号:PML-1
大小:27K
作者:Bob(自研改进)
环境配置
开发工具:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
语言环境:Python == 3.12.0
依赖包:
– pip install numpy==2.3.3
– pip install matplotlib==3.10.6
– pip install pandas==2.3.2
– pip install scikit-learn==1.7.2
研究背景
糖尿病已成为全球范围内威胁人类健康的重要慢性疾病。根据世界卫生组织(WHO)的统计,全球糖尿病患者数量持续上升,且呈现年轻化趋势。糖尿病若未能在早期得到有效识别与干预,极易引发心血管疾病、肾功能衰竭、视网膜病变等严重并发症,增加社会与家庭的医疗负担。因此,如何利用现有的临床与健康数据开展糖尿病的早期预测与风险评估,是医学与数据科学交叉领域的一个关键问题。
传统的糖尿病诊断方法依赖于血糖检测及临床症状判断,但其预测能力有限。近年来,机器学习技术因其在数据挖掘、模式识别和非线性建模方面的优势,被广泛应用于医学预测研究。通过对患者的基础信息与医学指标进行建模分析,机器学习能够从复杂的多维数据中提取潜在规律,从而提高预测的准确性和鲁棒性。基于此,本文尝试对多种主流机器学习算法进行比较与优化,以构建更为有效的糖尿病预测模型,为后续临床诊断与个性化干预提供参考。
系统架构
1.功能模块
数据层:负责数据导入、缺失值。
特征工程层:完成数据标准化,确保训练与预测一致。
模型训练与选择:对比多种算法,进行交叉验证与网格搜索,选择最佳模型。
模型管理:保存与版本化模型(model.pkl)。
2.架构设计
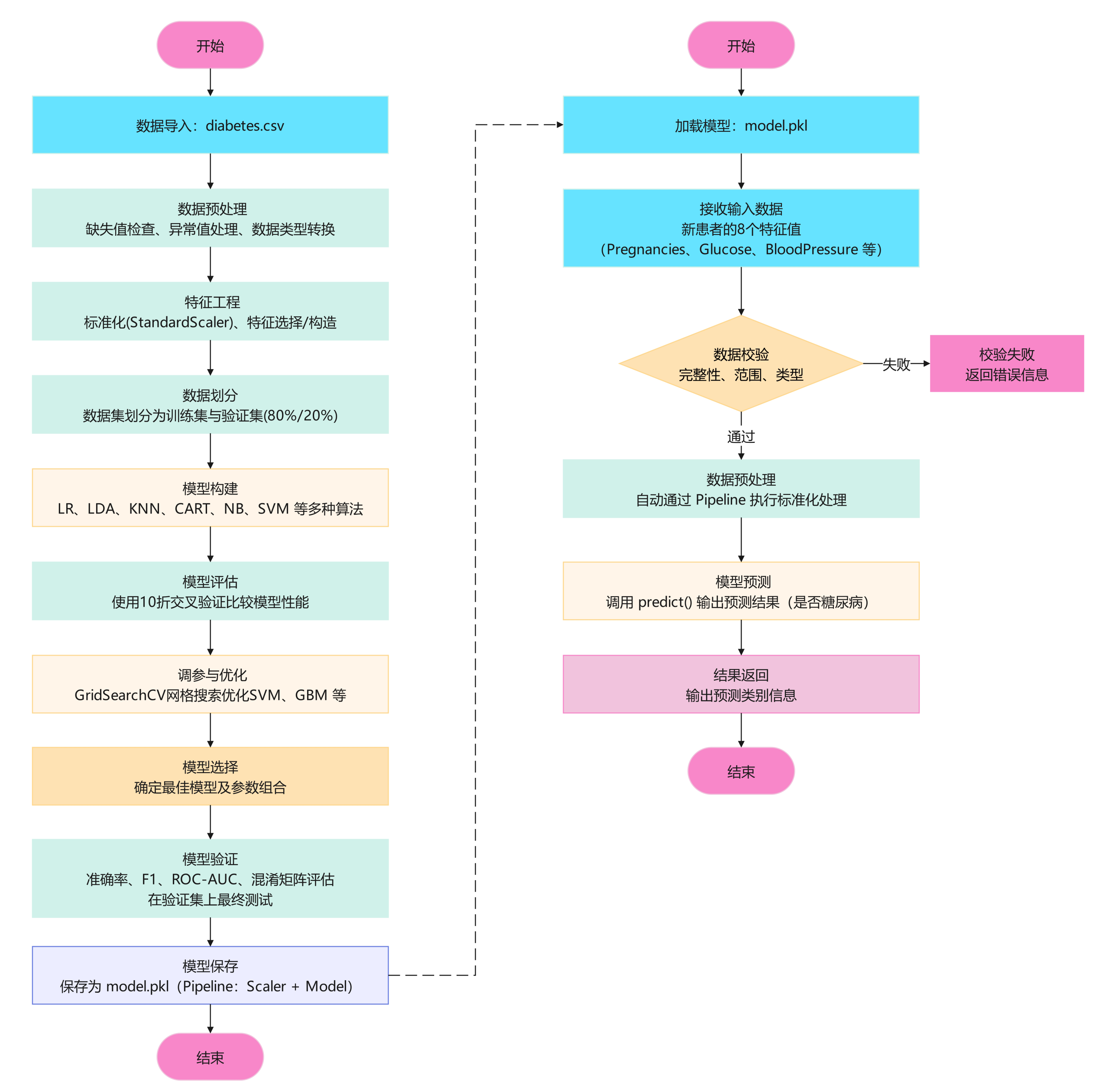
研究方法
本研究通过数据预处理与标准化,构建并比较多种机器学习模型,结合交叉验证和网格搜索选择最佳模型,并保存为可复用的预测模型用于糖尿病风险预测。

数据来源

实验设计
本研究采用 diabetes.csv 数据集,在数据标准化基础上构建并比较多种机器学习模型,结合 10 折交叉验证与网格搜索选择最佳模型,并通过准确率、混淆矩阵及精度、召回率、F1 值等指标进行评估,最终保存最优模型用于糖尿病预测。

结果分析
整体准确率尚可,但在医疗场景中更应提升 1 类召回率以减少漏诊。
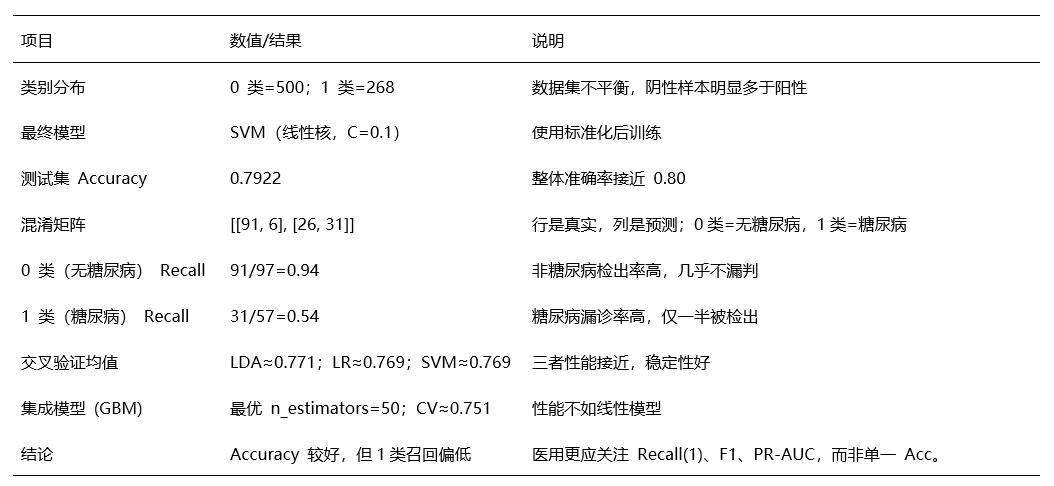
图示分析
运行 糖尿病预测.py
图1:各变量直方图 (Histograms of Features)
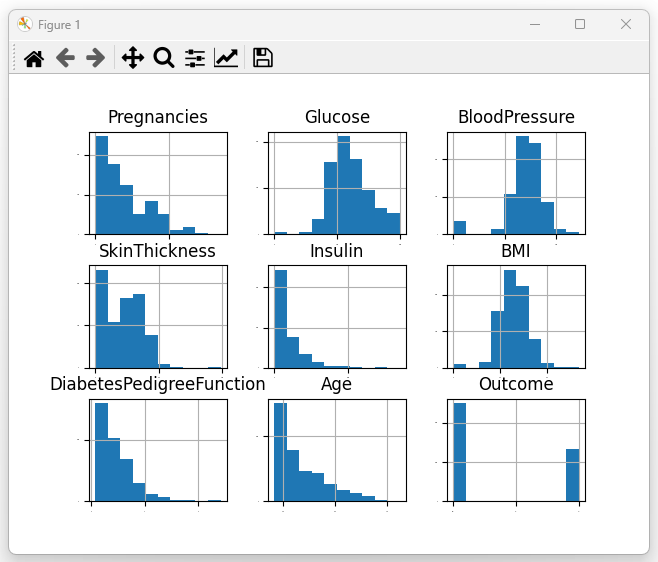
分析:
(1)大部分变量(如 Glucose、BloodPressure、BMI)接近高斯分布,但存在一定偏态。
(2)Insulin、DiabetesPedigreeFunction 明显右偏,存在长尾。
(3)Outcome 类别不均衡(0 > 1)。
→ 说明数据需标准化或 Box-Cox 等变换,避免偏态对模型性能造成影响。
图2:各变量密度图 (Kernel Density Plots)
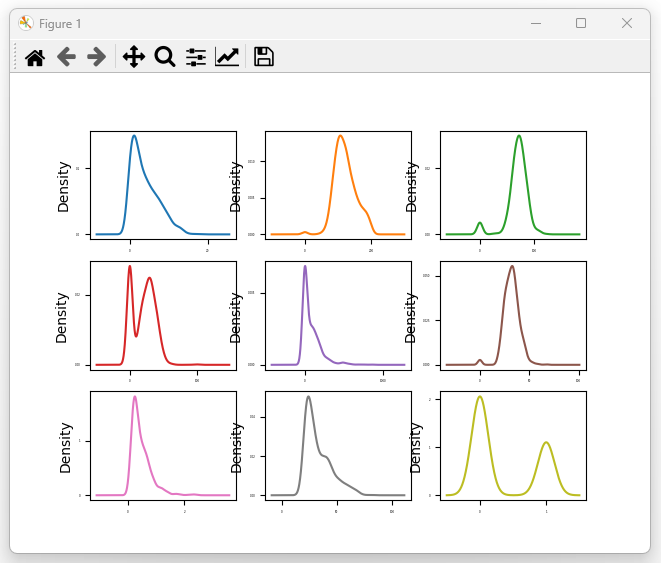
分析:
(1)进一步确认了变量分布的不均衡性。
(2)SkinThickness、Insulin 等特征出现多峰现象,提示可能存在数据记录误差或不同人群亚类。
(3)多数特征未严格服从正态分布,标准化是必要的。
图3:相关系数矩阵 (Correlation Matrix Heatmap)
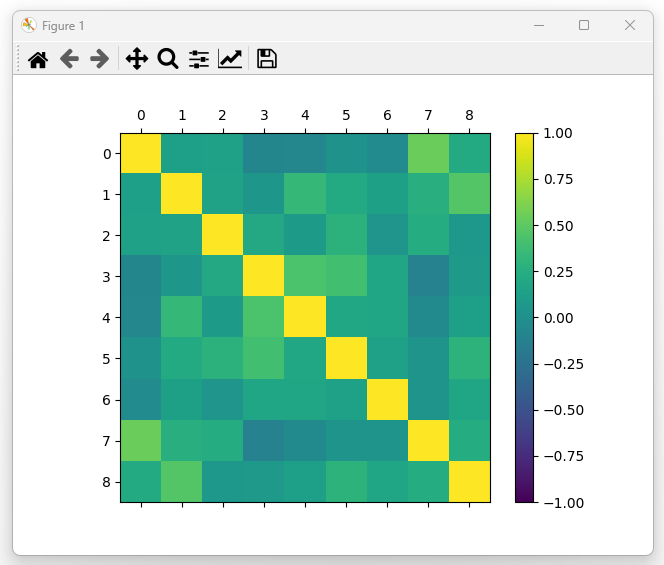
分析:
(1)Glucose 与 Outcome 相关性最高,说明血糖水平是糖尿病预测的重要因子。
(2)Pregnancies 与 Age 存在一定相关性(符合常识:高龄人群更可能有多次妊娠史)。
(3)其他变量相关性较弱,表明特征相对独立,可以共同提升模型表现。
图4:基础模型对比 (Baseline Models Comparison)
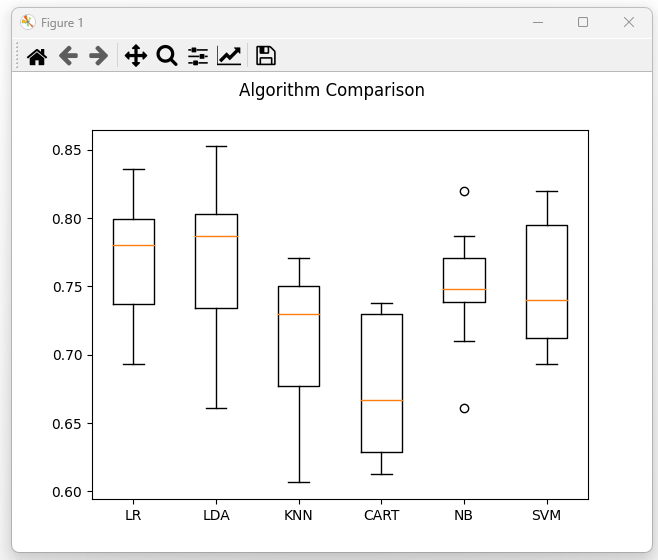
分析:
(1)LDA、LR 表现最佳,均值接近 0.80。
(2)CART、KNN 效果相对较差,且波动较大。
(3)SVM 中位数不低,但离群点较多,说明稳定性稍差。
图5:标准化数据后的模型对比 (Scaled Models Comparison)
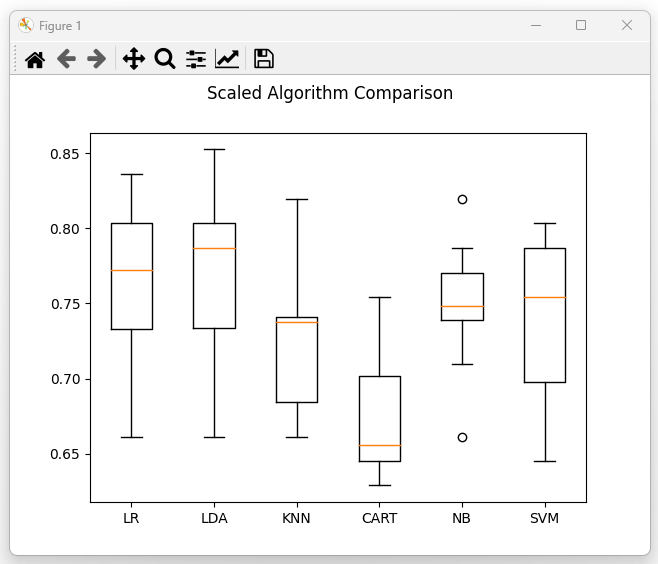
分析:
(1)标准化后,LR 和 LDA 表现进一步稳定,整体优于未缩放数据。
(2)SVM 表现提升明显,均值达到 ~0.76–0.78,说明 SVM 对特征缩放较敏感。
(3)CART 改善不大,仍然较差。
图6:集成模型对比 (Ensemble Models Comparison)
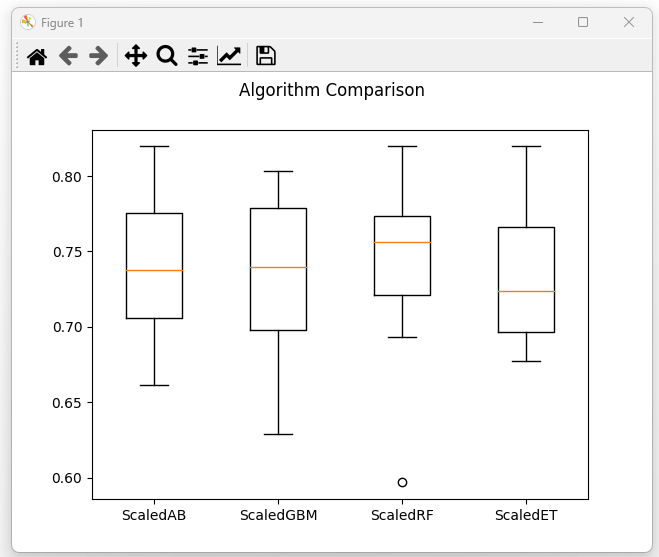
分析:
(1)GBM (Gradient Boosting Machine) 表现最优,平均准确率在 0.78 左右,且波动较小。
(2)RF、AB 也有不错表现,ET 波动稍大。
(3)集成方法整体优于单一模型,说明 Boosting 和 Bagging 能较好地捕捉复杂特征关系。
文件清单
本系统基于 Python 平台 开发,主要集成以下脚本与模块:

结论展望
本研究利用多种机器学习方法对糖尿病预测进行了比较,结果表明模型整体准确率约为 0.79,具备一定应用价值。然而在类别不平衡的数据下,阳性样本(糖尿病患者)的召回率仍然偏低,存在漏诊风险。在医疗场景中,仅依赖准确率并不足以全面反映模型性能,因此需更多关注 Recall(1)、F1 值和 PR-AUC 等指标。未来的研究可在数据平衡处理、特征工程、模型集成以及决策阈值优化等方面进一步改进,以提升对阳性样本的识别能力,更好地满足临床应用需求。
实验环境
硬件配置如表:实验所用硬件平台为惠普(HP)暗影精灵10台式机整机,运行 Windows 11 64 位操作系统,作为模型训练与测试的主要计算平台,能够良好支持Matlab的开发需求。

官方声明
实验环境真实性与合规性声明:
本研究所使用的硬件与软件环境均为真实可复现的配置,未采用虚构实验平台或虚拟模拟环境。实验平台为作者自主购买的惠普(HP)暗影精灵 10 台式整机,具体硬件参数详见表。软件环境涵盖操作系统、开发工具、深度学习框架等,具体配置详见表,所有软件组件均来源于官方渠道或开源社区,并按照其许可协议合法安装与使用。
研究过程中严格遵循学术诚信和实验可复现性要求,确保所有实验数据、训练过程与结果均可在相同环境下被重复验证,符合科研规范与工程实践标准。
版权声明:
本算法改进中涉及的文字、图片、表格、程序代码及实验数据,除特别注明外,均由2zcode.Bob独立完成。未经2zcode官方书面许可,任何单位或个人不得擅自复制、传播、修改、转发或用于商业用途。如需引用本研究内容,请遵循学术规范,注明出处,并不得歪曲或误用相关结论。
本研究所使用的第三方开源工具、框架及数据资源均已在文中明确标注,并严格遵守其相应的开源许可协议。使用过程中无违反知识产权相关法规,且全部用于非商业性学术研究用途。
评论(0)