
摘要:随着医学影像技术的进步,深度学习在肾脏肿瘤的自动诊断中展现出巨大潜力。本研究旨在比较三种主流深度学习模型——ResNet50、VGG16和Swin-Transformer,在肾脏肿瘤影像诊断中的表现。我们使用了包含肾脏肿瘤和正常肾脏图像的CT数据集,评估了模型在分类准确率、灵敏度、特异性和ROC曲线下的面积(AUC)等指标上的性能。
项目信息
编号:PCV-9
数据集:Dataset-9
大小:1.86G
作者:Bob(原创)
环境配置
开发工具:
– PyCharm的安装包:PyCharm: Python IDE for Professional Developers
– PyCharm的历史安装包:PyCharm: Python IDE for Professional Developers
– Anaconda的安装包:Anaconda | Start Coding Immediately
语言环境:Python == 3.12.0
依赖包:
– pip install numpy==2.3.3
– pip install opencv-python==4.12.0.88
– pip install pillow==11.3.0
– pip install PyQt==5.15.11
– pip install torch==2.7.0+cu118
– pip install torchvision== 0.22.0+cu118
– pip install matplotlib==3.10.7
研究背景
肾脏肿瘤是泌尿系统常见的实体肿瘤之一。临床实践中,增强计算机断层扫描(contrast-enhanced CT, CECT)仍是病灶筛查、分型与术前评估的核心影像学手段。然而,肿瘤在不同期相(皮质髓质期、肾实质期、排泄期)呈现的密度、强化模式与边界特征差异显著;同时,病灶体积可小、形态多样,且与囊肿、炎症等良性病变在影像表型上存在重叠。这些因素导致判读过程对阅片者经验高度依赖,易受观察者间/内变异与工作负荷影响,进而增加漏诊与误诊风险。基于 CECT 的稳定、可推广的自动化诊断技术,因而对提升早期发现率与减轻临床负担具有重要意义。
近年来,深度学习在医学影像领域取得快速进展,为上述问题提供了可行路径。以 VGG16、ResNet50 为代表的卷积神经网络(convolutional neural networks, CNNs)能够逐层提取局部纹理与形状等判别性特征,并在多器官病变识别任务中展现出良好基线性能。VGG16 具有规则且同构的深层结构,便于在训练策略与正则化方法上开展可比性研究;ResNet50 借助残差连接缓解网络退化与梯度消失问题,在兼顾模型深度与优化稳定性方面具有代表性。随着视觉 Transformer 架构的发展,Swin-Transformer 通过层次化表示与移位窗口(shifted windows)机制有效建模长程依赖,在复杂背景、边界模糊或异质性强的病灶识别情境下具有潜在优势。
尽管相关研究数量不断增长,现阶段仍存在若干共性不足:其一,任务设定不统一。分类、检测与分割等目标混用,且输入范式在 2D 切片、2.5D 堆叠与 3D 体素间不一致,导致结果横向可比性受限;其二,数据分布差异显著。不同中心在扫描协议、期相比例、层厚与重建核上的差异引入域偏移(domain shift),影响模型外部泛化;其三,样本规模与标注质量受限。类别不均衡及小样本问题易致过拟合,而病灶边界与标签一致性亦限制上限性能;其四,评估不充分。部分工作仅报告准确率(accuracy),而欠缺对灵敏度(sensitivity)、特异性(specificity)以及 ROC 曲线下面积(area under the ROC curve, AUC)等临床相关指标的系统评估,难以反映在高漏诊成本场景下的真实效用;其五,可解释性与稳健性验证不足。缺乏基于显著性可视化(如 Grad-CAM)与对扰动/域外数据的鲁棒性检验。
基于此,本文在统一的数据预处理、训练与验证流程下,选取三类具有代表性的主流模型——VGG16(规则深层 CNN 基线)、ResNet50(残差深层 CNN)与 Swin-Transformer(层次化视觉 Transformer)——对肾脏肿瘤与正常肾脏的 CECT 影像进行系统比较。研究重点围绕四项核心指标:分类准确率、灵敏度、特异性与 AUC。本文的目标在于:(1)在标准化设定下建立客观、可复现的比较基准;(2)刻画不同架构在肾脏肿瘤影像表型上的优势与短板;(3)为后续的模型选型、临床部署与多中心泛化提供方法学与实证层面的参考。
算法概述
1.VGG16
本研究采用的深度学习模型为VGG16。VGG(Visual Geometry Group)是英国牛津大学计算机视觉小组提出的深度卷积神经网络架构。VGG网络的主要贡献在于其使用了更深的网络结构,通过增加卷积层的数量,能够有效地提取图像中的更为丰富的特征,从而提高模型在图像分类任务中的准确性和泛化能力。具体而言,VGG16由16层组成,包括13个卷积层和3个全连接层。在该架构中,每个卷积层使用相同大小的卷积核(3×3),并采用较小的步幅(1),通过多层堆叠的方式来增强网络的表达能力。VGG16的设计思想基于对较浅网络的深度堆叠,体现了深层网络在提高分类准确率方面的优势。
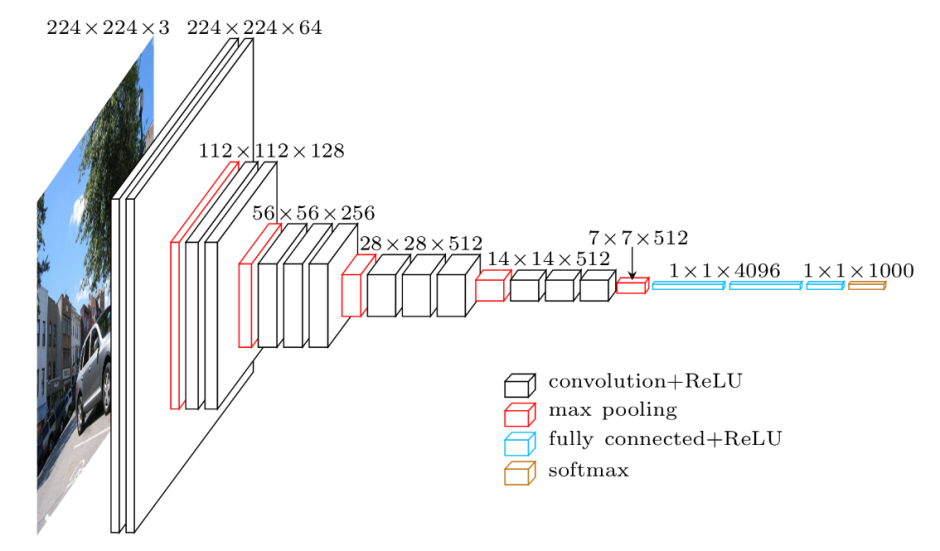
图1 VGG16网络架构示意图
2.ResNet50
ResNet50是一种基于深度卷积神经网络(Convolutional Neural Network,CNN)的图像分类算法。它是由微软研究院的Kaiming He等人于2015年提出的,是ResNet系列中的一个重要成员。ResNet50相比于传统的CNN模型具有更深的网络结构,通过引入残差连接(residual connection)解决了深层网络训练过程中的梯度消失问题,有效提升了模型的性能。
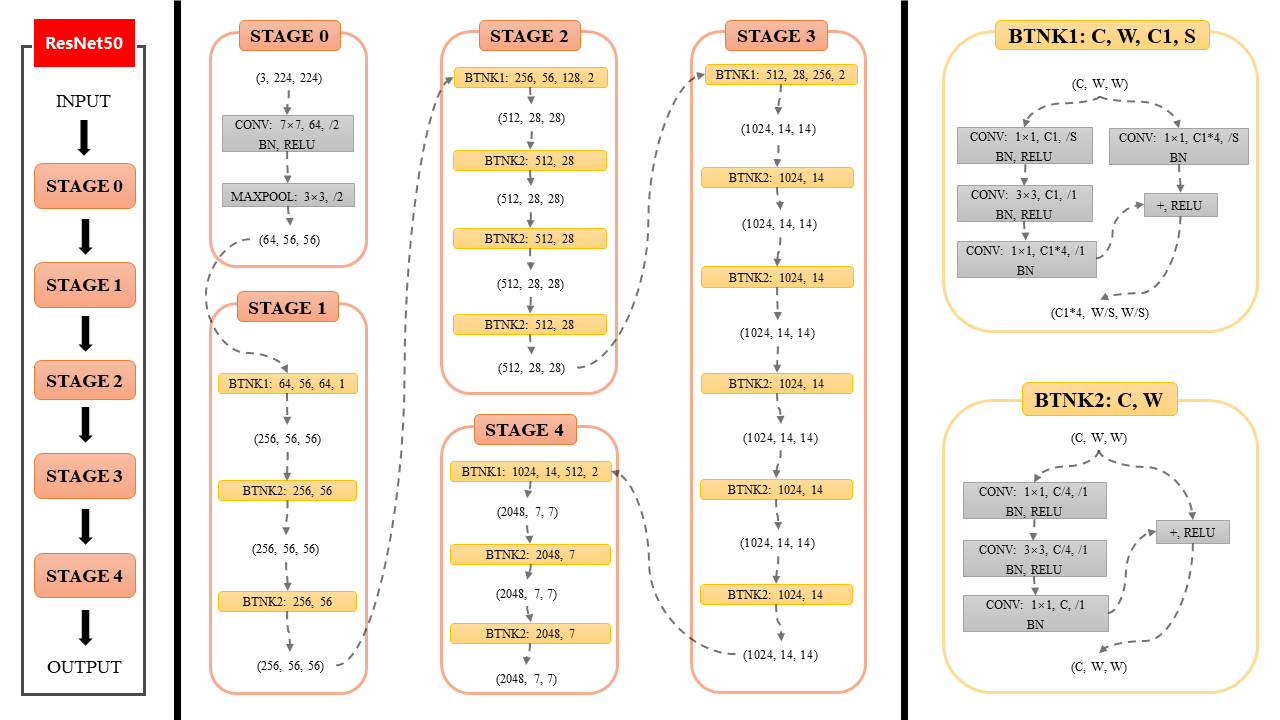
图2 ResNet50网络结构图
这张图展示了ResNet50网络的架构细节,清晰地展示了其分为多个阶段(Stage 0 至 Stage 4)的模块化结构。每个阶段包含不同的卷积层、批量归一化(BN)和残差连接(BTNK1和BTNK2),从而提高了网络的训练效率和准确性。
3.Swin Transformer
Swin Transformer由微软公司的研究人员推出,是一种有效结合了 CNN 和 Transformer模型优势的新型架构。它旨在以类似 CNN 的分层方式处理图像,同时利用变换器固有的自我关注机制。这种混合方法使 Swin 变换器能够有效处理各种规模的视觉信息,从而使其在广泛的视觉任务中具有高度的通用性和强大的功能。
Swin Transformer 的核心创新在于其分层结构和基于移位窗口的自我注意力机制。与标准视觉转换器(ViT)在整个图像中应用自我注意力不同,Swin Transformer将图像划分为不重叠的小窗口,在这些窗口内计算自我注意力,从而减少了计算复杂性。此外,Swin Transformer引入了窗口移位技术,使得在连续的Transformer块之间,图像区域能在不同层之间相互影响,从而更好地整合局部与全局上下文信息。
![]()
图3 Swin Transformer多层级表示和ViT对比
如图1所示,Swin Transformer从小的patch开始,通过在深层次逐步合并相邻patch的方式构建了一个层级化的表示。通过这些层级特征图,Swin Transformer可以像FPN和U-Net那样进行多尺度密集预测。通过对图像分区(用红色标出)进行非重叠窗口的局部自注意力计算实现了线性的计算复杂度。每个窗口的patch的个数是固定的,因此计算复杂度和图像的大小成线性关系。
相比于之前只能产生单一分辨率特征图和平方复杂度的Transformer模型,Swin Transformer适合作为各种视觉任务的通用主干网络(backbone)。
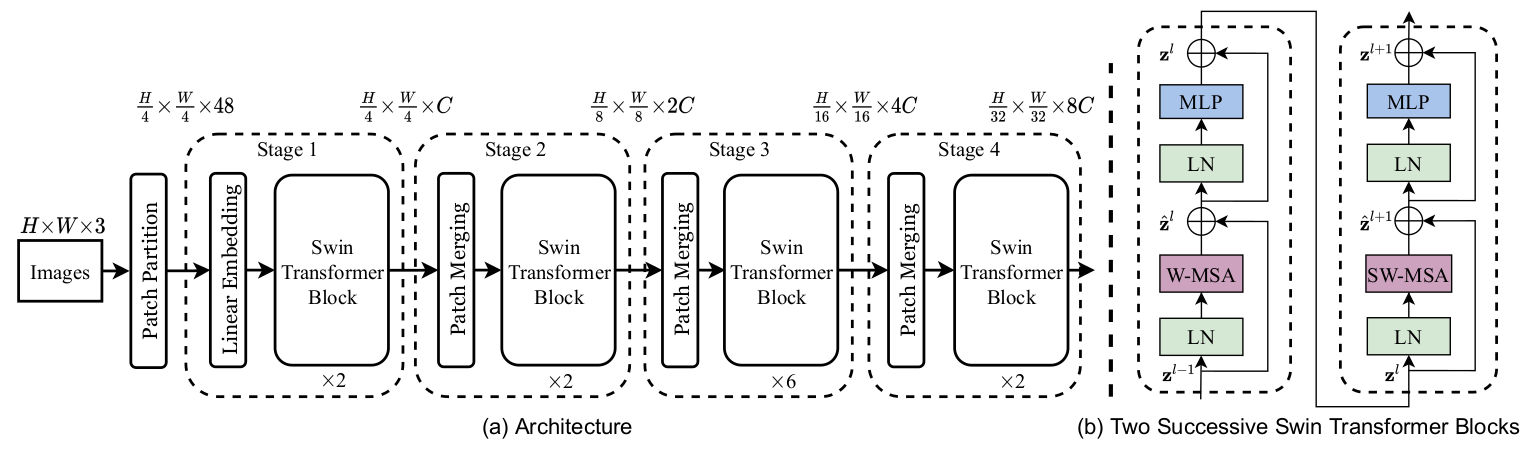
图4:Swin Transformer网络架构
该架构详细展示了 Swin-Transformer 模型如何通过逐层处理和 Patch Merging 实现高效的图像特征提取。每个阶段的 Swin Transformer Block 通过不同的自注意力机制(如 W-MSA 和 SW-MSA)逐步提升图像理解的深度。通过多层次的处理和特征合并,该模型在处理大规模图像数据时表现出色,特别适合于图像分类和目标检测等任务。
Swin Transformer解决了以往基于 CNN 和 Transformer的模型的几个局限性。首先,它的分层设计可以高效处理多种分辨率的图像,有助于完成需要同时了解精细细节和整体结构的任务,如物体检测和语义分割。其次,通过将自我关注机制定位到窗口并采用移位窗口,Swin Transformer 大幅降低了计算要求,使其更易于扩展到大型图像和数据集。最后,它的架构通过将局部特征无缝集成到更广泛的上下文中,实现了更好的特征学习,从而提高了各种视觉任务的性能。
系统设计
本系统面向肾脏肿瘤 CT 影像的自动化分析与分类,采用“数据输入 → 模型推理 → 结果展示”的一体化工作流程。系统架构由八个功能模块构成:图像输入模块、图像预处理模块、数据集准备模块、VGG16/ResNet50/Swin-Transformer 训练模块、推理与分类模块、用户交互界面模块、结果展示模块以及实验结果与性能评估模块。前端图形用户界面(GUI)支持用户便捷导入肾脏相关 CT 数据并进行交互操作;后端在统一的数据处理与训练范式下并行/可切换地运行三类主流模型,对输入图像进行实时二分类(“肾脏正常”“肾脏癌症”),并输出置信度与可解释性可视化。
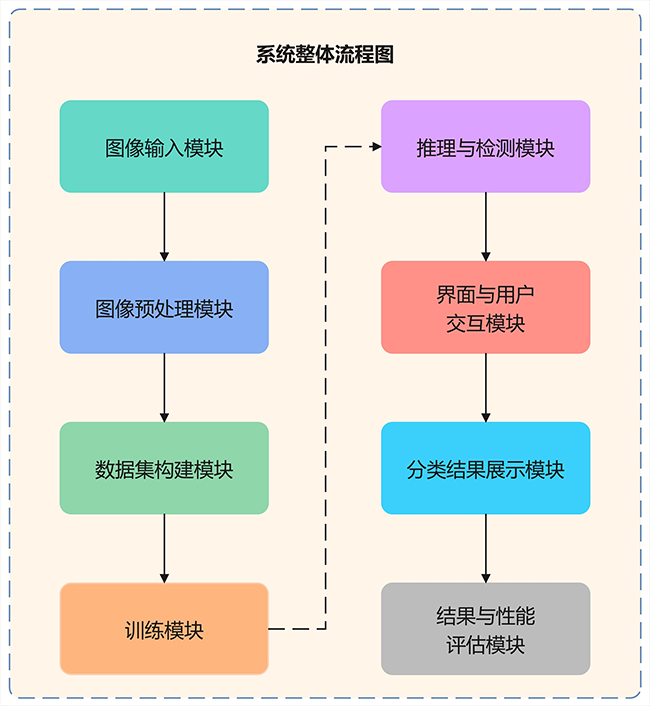
图5 诊断系统整体流程图
通过对肾脏肿瘤 CT 影像数据集的系统训练与优化,我们构建了一体化的肾脏肿瘤影像诊断系统,并在统一框架下比较了 ResNet50、VGG16 与 Swin-Transformer 的二分类性能(“肾脏正常”,“肾脏癌症”)。该系统在实时影像诊断和临床分析中具有广泛的应用前景,为早期干预、个性化治疗以及临床决策提供了强有力的支持。
数据集构建
1.数据来源
本研究所用腹部 CT 切片数据主要来源于 Kaggle 公开数据集 CT KIDNEY DATASET: Normal–Cyst–Tumor–Stone(CT-KIDNEY-NCTS)。该数据集由去标识化的腹部 CT 轴位图像构成,按 Normal、Tumor、Cyst、Stone 四类组织管理,文件以 JPG/PNG 形式提供,分辨率多为约 512×512,已完成软组织窗显示的强度映射(原始 DICOM 元数据与纵向随访信息不提供)。数据来自不同设备与成像方案,具有一定的域内异质性,适合用于评估模型在真实场景中的稳健性与泛化能力。
在本研究中,我们仅选取 Normal 与 Tumor 两类构建“肾脏正常 vs 肾脏癌症”的二分类子集。经数据整理与质量控制(图像质量筛除、近重复样本剔除与分层抽样划分训练/验证/测试集)后,形成覆盖多样影像表型的肾脏肿瘤二分类数据集,并在统一的预处理与评估协议下,对 ResNet50、VGG16 与 Swin-Transformer 三种方法进行系统比较。
该公开、去标识化数据为肾脏肿瘤的自动化识别与早期筛查提供了可复用的训练与评测基础,推动深度学习模型在腹部 CT 影像中的应用与方法学对照研究;结合本文报告的 Accuracy、Sensitivity、Specificity 与 AUC 等指标,可为临床辅助诊断与后续多中心泛化研究提供客观基线与参考。

表1 数据集基本信息
该数据集包括“肾脏正常”、“肾脏癌症”等不同的肾脏影像。数据集不仅涵盖了二种类型,且具有较高的质量,适用于系统的分类任务,为肾癌及其他的自动化诊断提供了高质量的训练数据。该数据集旨在推动深度学习和人工智能技术在医学影像分析领域中的应用,特别是在肾癌检测中,提供强有力的数据支持,旨在提高诊断的准确性和效率。

图6 数据集图片
本研究所用肾脏 CT 数据集涵盖“肾脏正常”与“肾脏癌症”两类腹部轴位切片,图像质量较高、来源多样(不同设备与成像协议),能够较全面地反映肾脏肿瘤的影像表型差异。数据集适用于二分类(正常 vs 癌症)任务,可用于训练与评估深度学习模型在肾脏肿瘤识别中的性能与稳健性。通过对该数据的系统整理与质量控制(去标识化、图像清洗与标准化划分),我们构建了用于 ResNet50、VGG16 与 Swin-Transformer 的统一评测基座。该数据集的构建与使用旨在推动深度学习与人工智能在医学影像分析领域的应用,特别是在肾脏肿瘤自动化检测与早期筛查中提供有力的数据支持,从而提升诊断的准确性与效率并服务于临床决策。
2.分类方法
本系统所使用的肾脏影像数据的分类信息由专业人员完成。每个肾脏影像都被分配到一个明确的疾病状态,如“肾脏正常”和“肾脏癌症”。为确保分类的准确性和可靠性,分类过程由专业人员独立完成,并通过交叉验证的方式进行审核,从而有效降低个体差异带来的偏差,确保数据分类的一致性和权威性。该分类方法确保了数据集的高质量,并为后续基于深度学习模型的肾脏疾病分类模型训练提供了坚实的数据支持。
(1)分类数据集格式
该格式主要用于肾脏影像分类任务,常见于Swin Transformer、VGG16、ResNet50等深度学习模型的训练。其方法是将每张肾脏影像归类为一个明确的类别,如“肾脏正常”和“肾脏癌症”。该格式能够确保数据与模型在训练与推理过程中的高效匹配,从而提高分类精度和推理效率。Swin Transformer通过其分层结构和移位窗口自注意力机制,能够更好地处理图像中的局部与全局上下文信息,进一步提升了分类性能。而VGG16和ResNet50作为经典的卷积神经网络,凭借其深层网络结构和强大的特征提取能力,在肾脏影像分类任务中同样能够取得出色的表现。该格式简化了数据准备过程,并为基于Swin Transformer、VGG16和ResNet50的肾脏影像分类模型训练提供了高效且标准化的数据输入。
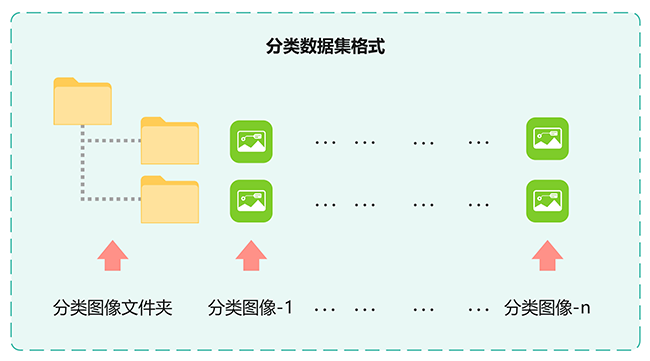
图7 分类数据集格式
(2)数据集划分
标注后的数据集不仅包括图像文件,还包含对应的分类信息。经过上述所有步骤处理和验证后的图像数据被划分成训练集和测试集,形成最终的数据集,用于算法训练学习模型。

图8 数据集划分:测试集和训练集
以下是数据集的具体含义及每个数据集的作用:
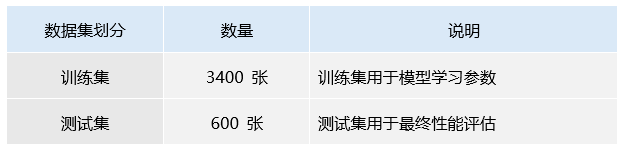
表2 数据集概述
模型训练
Swin Transformer 是一种常用于图像分类任务的深度学习模型。其训练过程主要包括以下几个关键步骤:配置文件与超参数的设置、训练过程的执行以及训练结果的可视化分析。Swin Transformer 通过其分层结构和移位窗口自注意力机制,能够有效捕捉图像中的局部与全局上下文信息,显著提升分类精度和效率。此外,Swin Transformer 通过高效的计算方式,可以应对大规模数据集,并在多个图像分类任务中表现出了优异的性能。
除了 Swin Transformer 外,VGG16 和 ResNet50 作为经典的卷积神经网络模型,也在图像分类中展现了卓越的能力。VGG16 通过其简洁的网络结构和较小的卷积核尺寸,成功地提取了图像中的高层次特征。而 ResNet50 则通过引入残差连接,使得网络能够更深,避免了梯度消失和信息丢失的问题,从而提升了网络的训练效果和分类性能。
通过结合 Swin Transformer、VGG16 和 ResNet50 的优势,图像分类模型的整体表现可以得到显著提升。特别是在处理复杂且多样化的图像数据时,这些模型能够为图像分类任务提供强大的支持,适用于广泛的应用场景。
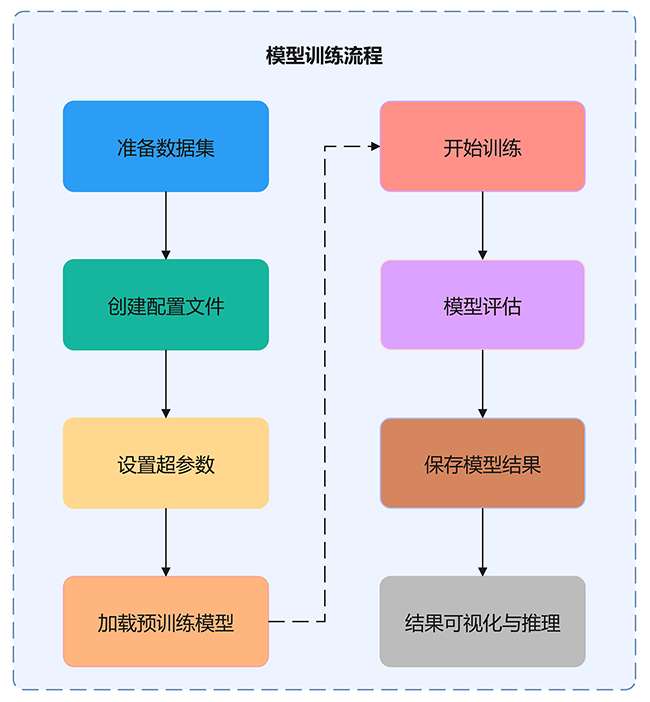
图9 模型训练流程图
1.配置文件与超参数设置
以下是关于Swin Transformer模型训练过程中的配置文件和超参数设置,并通过配置文件以及相关参数进行训练设置。

表3 Swin Transformer模型训练超参数设置
以下是关于ResNet50模型训练过程中的配置文件和超参数设置,并通过配置文件以及相关参数进行训练设置。

表4 ResNet50模型训练超参数设置
以下是关于VGG16模型训练过程中的配置文件和超参数设置,并通过配置文件以及相关参数进行训练设置。

表5 VGG16模型训练超参数设置
2.模型性能评估
在 Swin Transformer模型的训练过程中,模型性能评估是衡量其在图像分类任务中表现的重要环节,能够全面反映模型在分类精度和泛化能力方面的表现。科学而准确的评估不仅有助于揭示模型的优势与不足,还能为后续的改进与优化提供可靠依据。
(1)训练与验证准确率和损失曲线
![]()
图10 Swin Transformer训练与验证准确率和损失曲线
该图分为两部分,分别展示了模型在训练和验证集上的准确率和交叉熵损失随训练周期变化的情况。从上方的准确率曲线可以看到,随着训练进展,训练准确率逐步提高并稳定在较高值(接近1.0),而验证准确率也逐渐提升,显示模型在验证集上的表现逐渐变好,且没有出现明显的过拟合现象。下方的损失曲线则显示,训练损失和验证损失随着训练进程的推进都显著下降,并趋于平稳,进一步说明了模型训练的成功与稳定性。
(2)混淆矩阵热力图
![]()
图11 Swin Transformer混淆矩阵热力图
该热图展示了模型在分类任务中的混淆矩阵。通过该图可以看到,模型对于“正常”和“肿瘤”类别的分类完全正确。矩阵中的每个单元格均为1.0,表示所有样本都被正确分类。这说明模型的预测完全符合实际标签,没有出现任何假阳性或假阴性,体现出非常高的分类精度。
(3)各类认知障碍的分类性能评估:准确率、精确率、召回率与F1分数图
![]()
图12 各类认知障碍的分类性能评估:准确率、精确率、召回率与F1分数图
该图展示了图像分类模型在不同评估指标上的表现,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1得分。每个指标分别展示了所有类别的表现,精确率、召回率和F1得分在“正常”和“肿瘤”两个类别中的数值均为1.00,表明模型在这两个类别的分类上表现出色,几乎没有误差。整体准确率同样达到了1.00,显示模型的分类性能非常高,基本没有误判的情况。
(4)训练日志(Training Log)
训练日志记录了Swin Transformer模型在训练过程中的详细信息,包括训练轮次、每轮的损失值、验证准确率以及训练时间等,这些信息帮助评估模型的训练效果和性能。
![]()
图13 Swin Transformer训练日志
![]()
表6 模型训练日志概要
在 ResNet50 模型的训练过程中,模型性能评估是衡量其在图像分类任务中表现的重要环节,能够全面反映模型在分类精度和泛化能力方面的表现。科学而准确的评估不仅有助于揭示模型的优势与不足,还能为后续的改进与优化提供可靠依据。
(1)训练与验证准确率和损失曲线
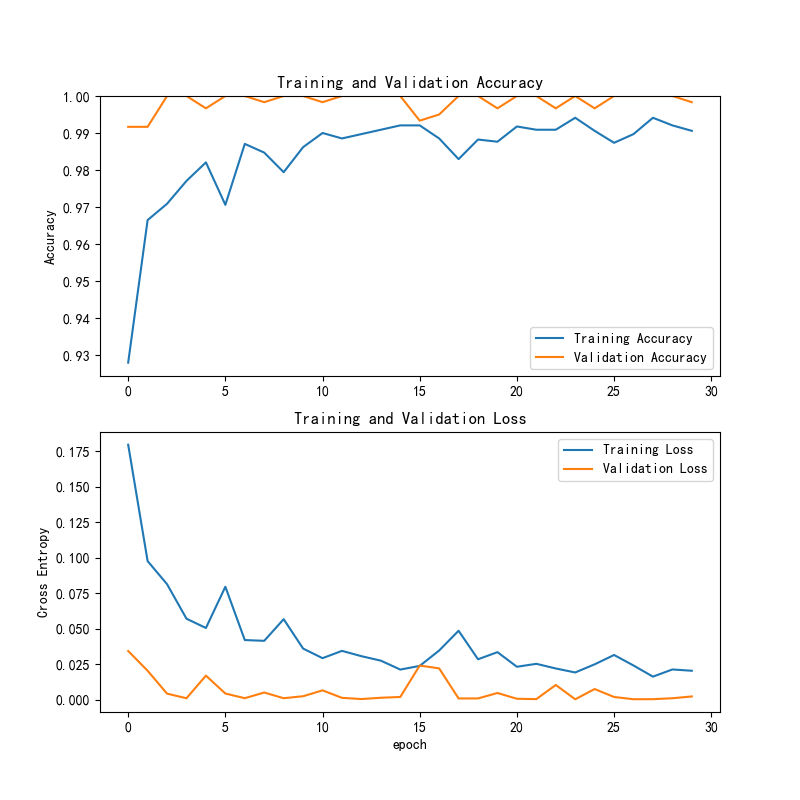
图14 ResNet50训练与验证准确率和损失曲线
该图分为两部分,分别展示了模型在训练和验证集上的准确率和交叉熵损失。上方的准确率曲线显示,训练准确率在训练过程中逐步提高并趋于稳定,在最后几个轮次达到了接近完美的值(接近1.0)。验证准确率也表现出相似的趋势,最终在最后一轮稳定在1.000。下方的交叉熵损失曲线显示,训练损失逐步减少,且验证损失保持在较低的水平,表明模型在训练和验证过程中逐渐优化,未出现明显的过拟合现象。
(2)混淆矩阵热力图
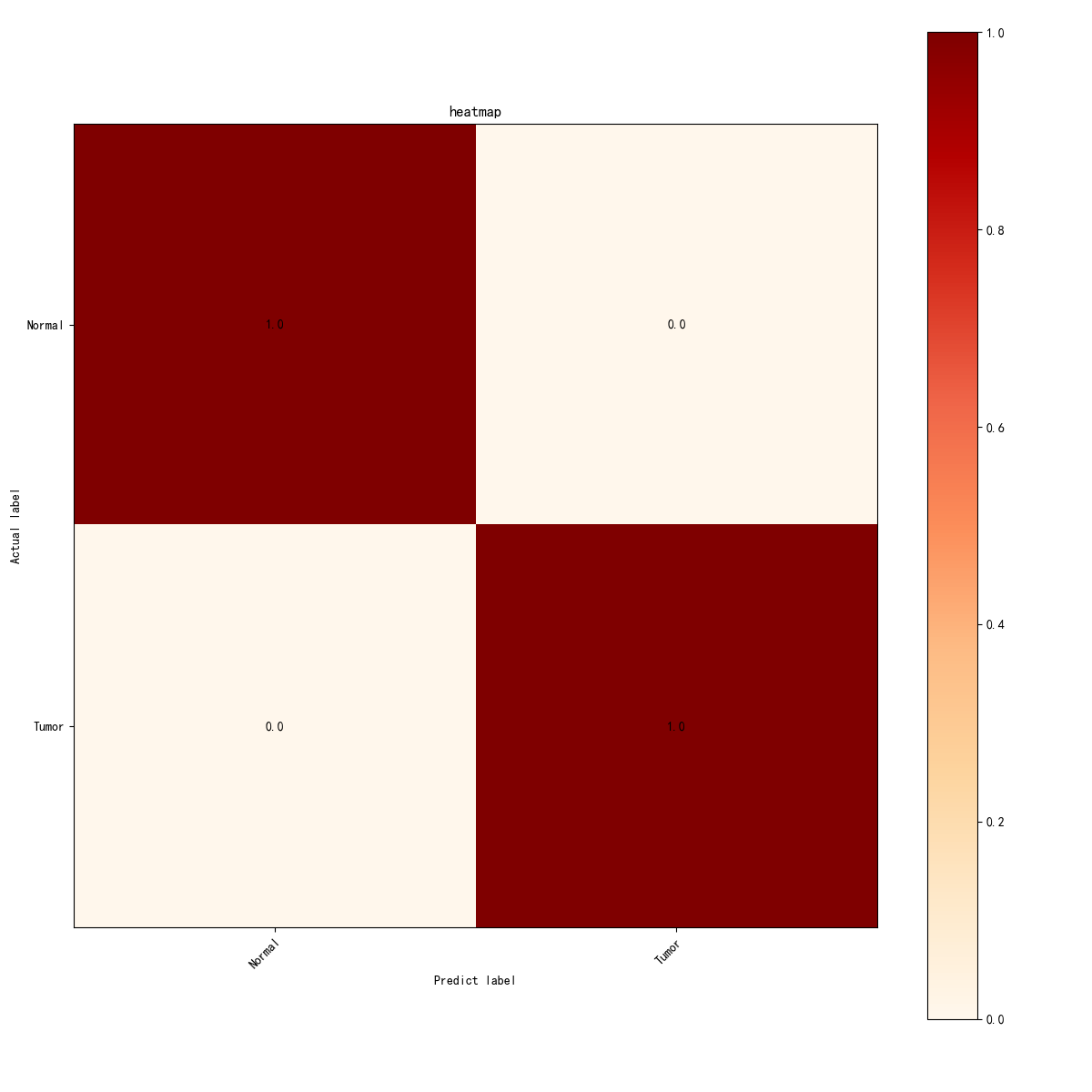
图15 ResNet50混淆矩阵热力图
混淆矩阵热图显示了模型在测试数据集上的分类情况。在该热图中,“正常”和“肿瘤”类别的预测完全正确,所有的预测都完全符合实际标签。矩阵中的每个单元格数值为1.0,表示所有样本都被正确分类,未出现任何假阳性或假阴性。该热图展示了模型的高精度和鲁棒性。
(3)各类认知障碍的分类性能评估:准确率、精确率、召回率与F1分数图
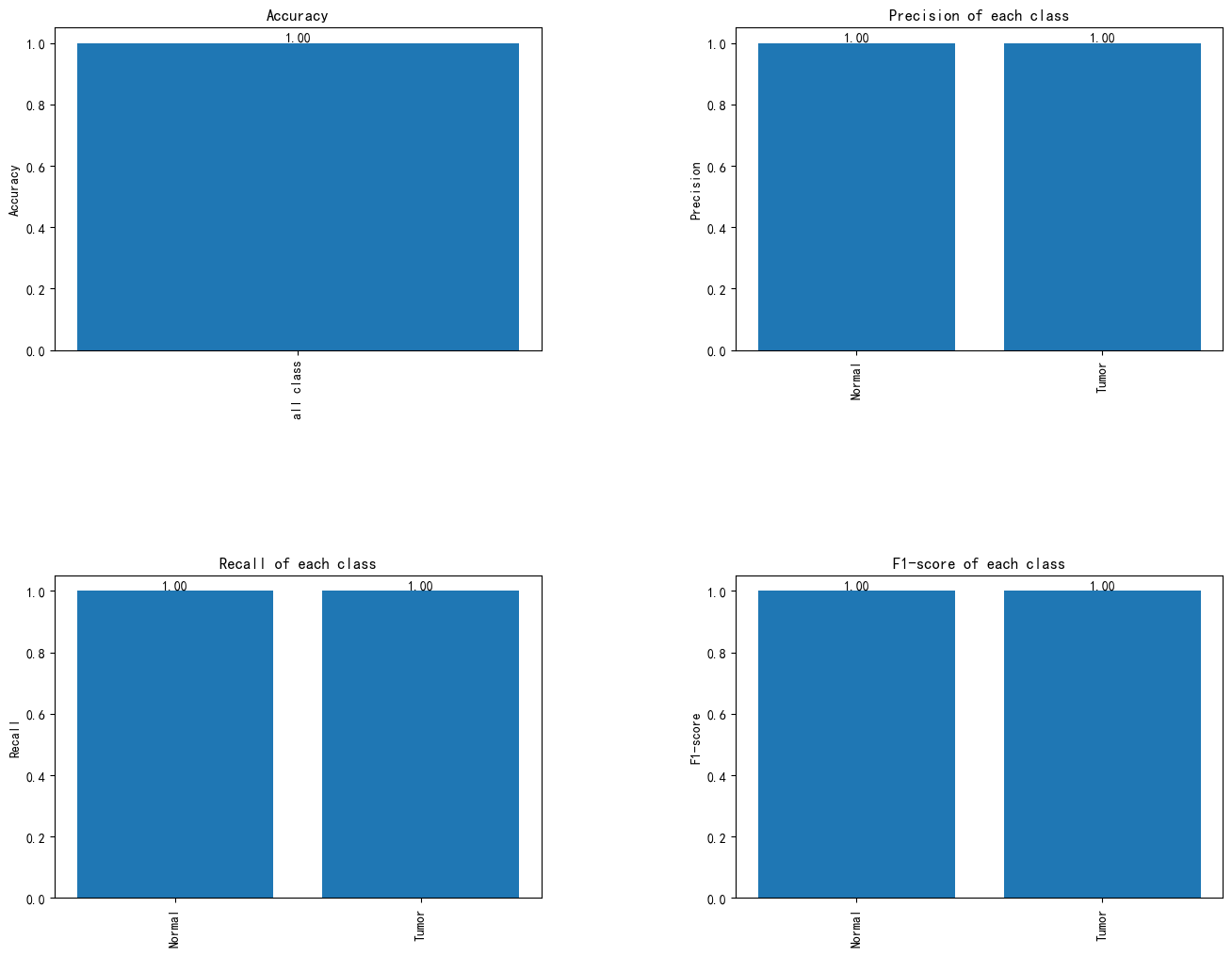
图16 各类认知障碍的分类性能评估:准确率、精确率、召回率与F1分数图
该图展示了模型在分类任务中的多个评估指标,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1得分。每个指标都显示了模型在“正常”和“肿瘤”两个类别中的表现,所有指标的数值均为1.00,表明模型在分类任务中的表现非常优秀,几乎没有任何误分类现象。精确率、召回率和F1得分均为完美值,说明模型在两类样本的分类上都取得了高度的精度和召回能力。
(4)训练日志(Training Log)
训练日志记录了ResNet50模型在训练过程中的详细信息,包括训练轮次、每轮的损失值、验证准确率以及训练时间等,这些信息帮助评估模型的训练效果和性能。
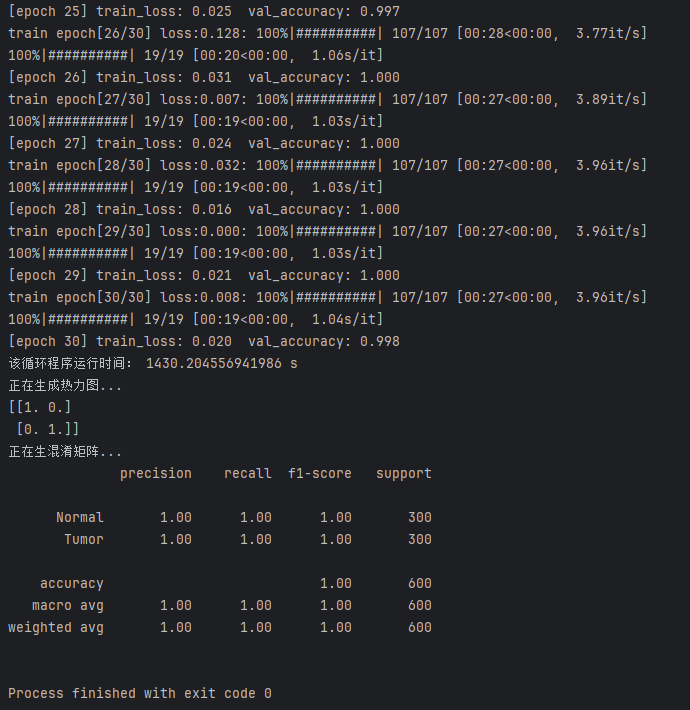
图17 ResNet50训练日志
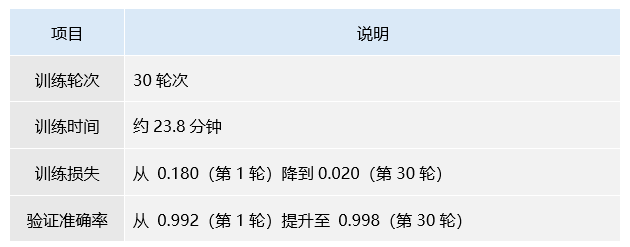
表7 模型训练日志概要志
在 VGG16 模型的训练过程中,模型性能评估是衡量其在图像分类任务中表现的重要环节,能够全面反映模型在分类精度和泛化能力方面的表现。科学而准确的评估不仅有助于揭示模型的优势与不足,还能为后续的改进与优化提供可靠依据。
(1)训练与验证准确率和损失曲线
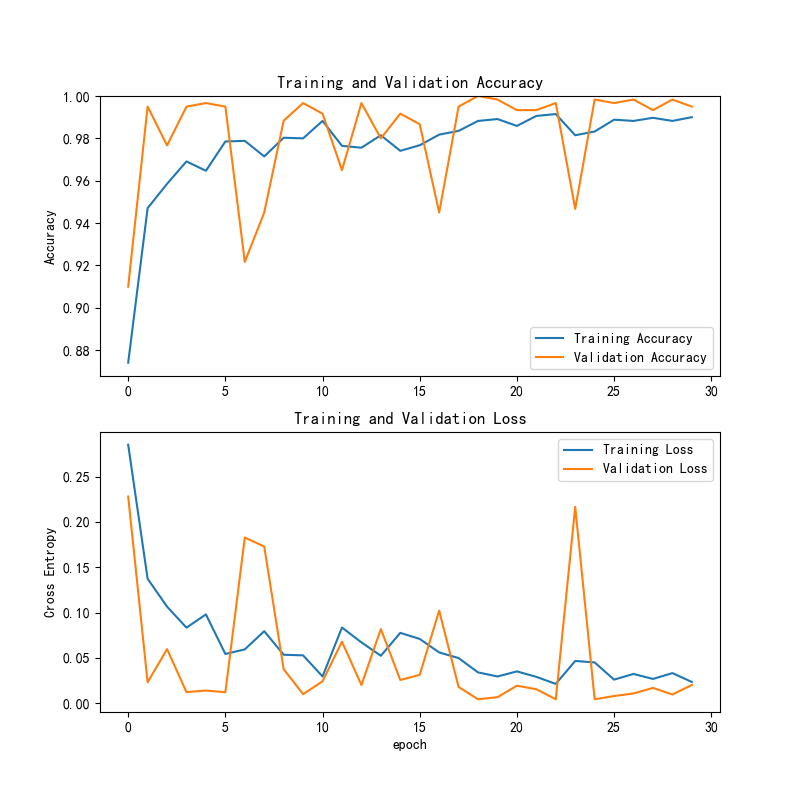
图18 VGG16训练与验证准确率和损失曲线
该图分为两部分,分别展示了训练过程中的准确率和损失。上方的训练准确率曲线显示,随着训练的进行,准确率逐步提高,并在训练的后期趋于稳定,验证准确率的变化也基本保持一致。下方的交叉熵损失曲线显示,训练损失和验证损失都有明显下降,并在后期趋于平稳,表明模型在优化过程中逐渐减少了误差,未出现明显的过拟合现象。
(2)混淆矩阵热力图
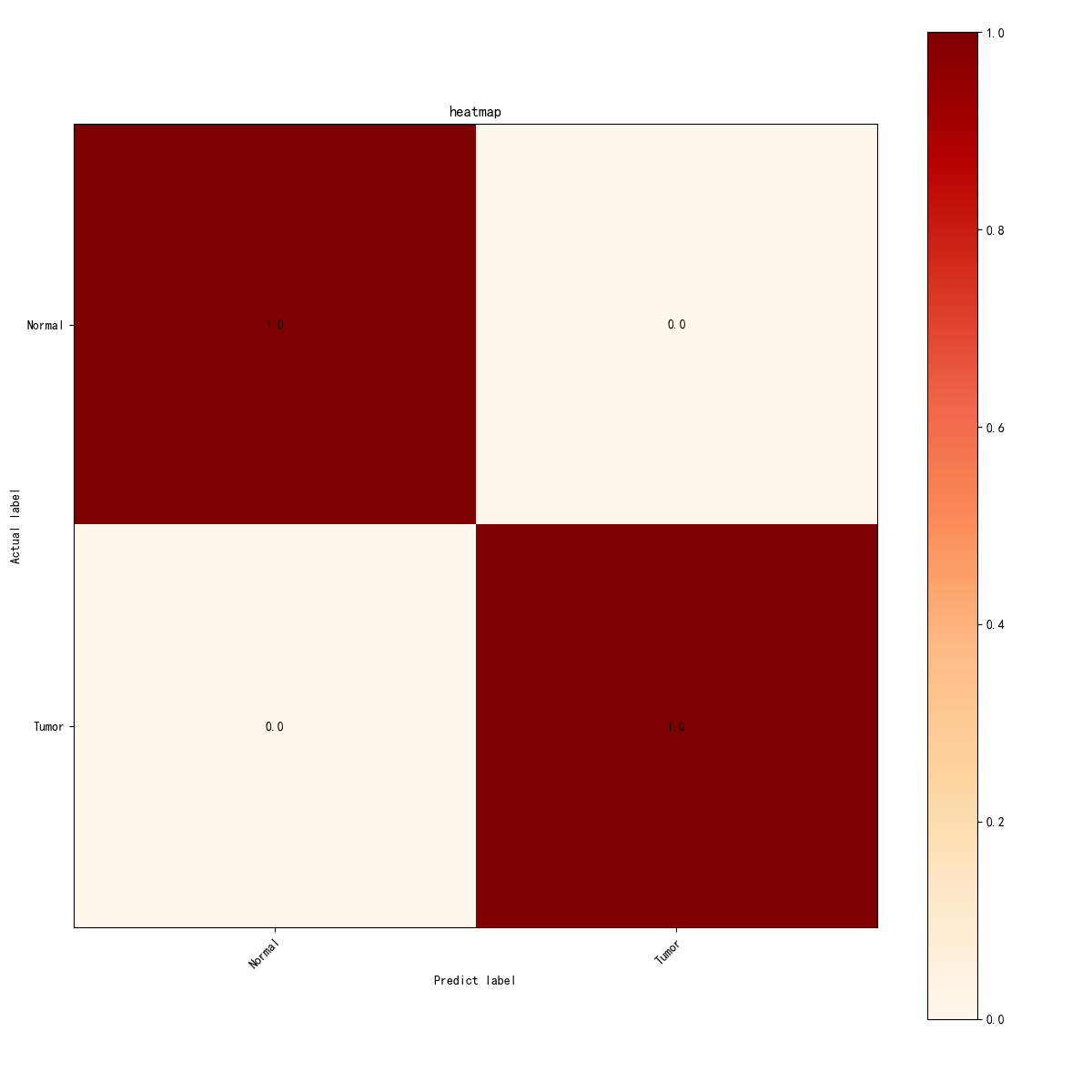
图19 VGG16混淆矩阵热力图
该热图展示了模型在测试数据集上的分类效果。通过混淆矩阵可以看到,所有的预测都完全正确,所有的“正常”和“肿瘤”样本都被准确分类,矩阵中的数值为1.0,表示模型在这两个类别的分类中没有出现任何错误的预测(假阳性或假阴性)。该图进一步验证了模型的高精度和稳定性。
(3)各类的分类性能评估:准确率、精确率、召回率与F1分数图
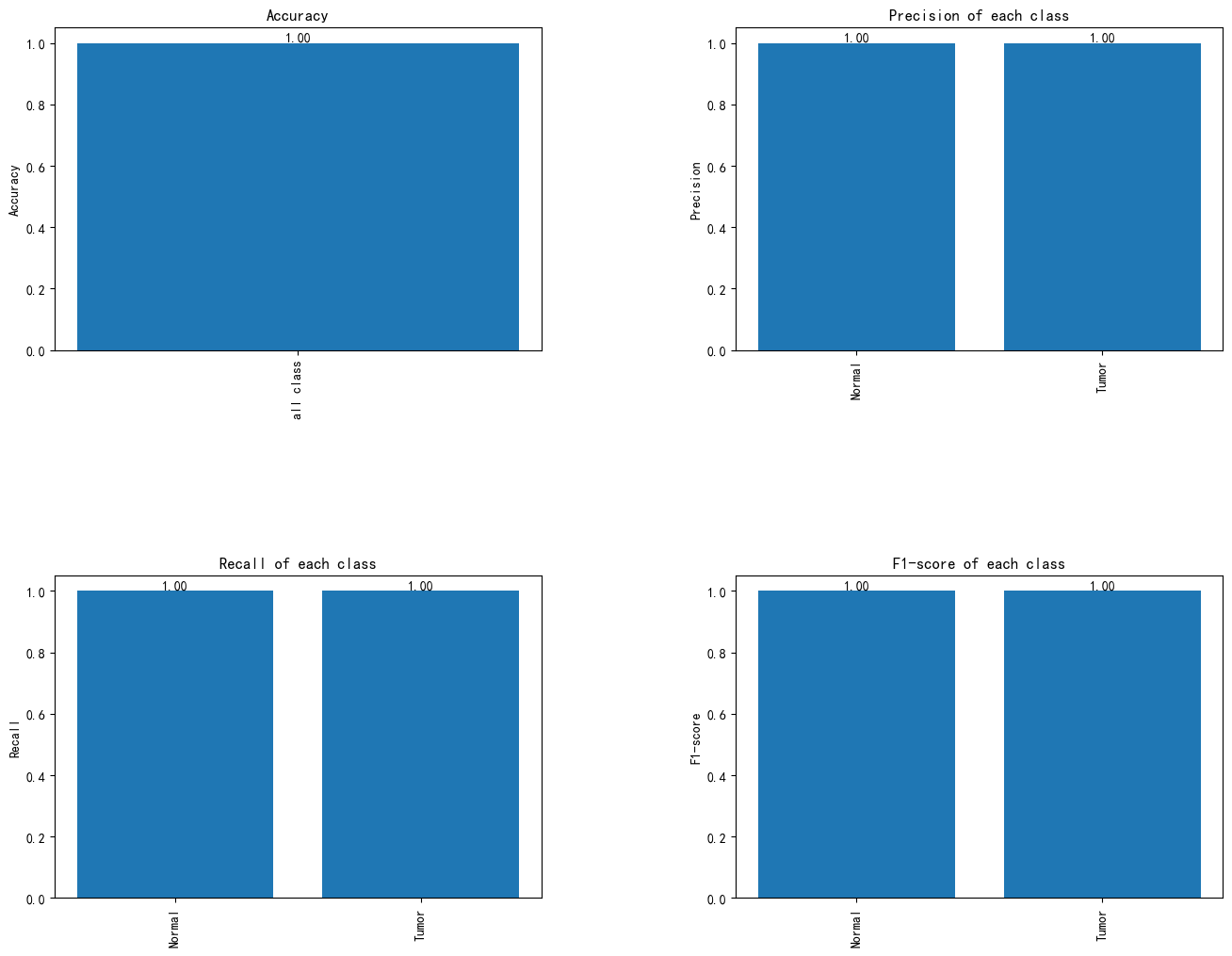
图20 各类认知障碍的分类性能评估:准确率、精确率、召回率与F1分数图
该图分为两部分,分别展示了训练过程中的准确率和损失。上方的训练准确率曲线显示,随着训练的进行,准确率逐步提高,并在训练的后期趋于稳定,验证准确率的变化也基本保持一致。下方的交叉熵损失曲线显示,训练损失和验证损失都有明显下降,并在后期趋于平稳,表明模型在优化过程中逐渐减少了误差,未出现明显的过拟合现象。
(4)训练日志(Training Log)
训练日志记录了VGG16模型在训练过程中的详细信息,包括训练轮次、每轮的损失值、验证准确率以及训练时间等,这些信息帮助评估模型的训练效果和性能。
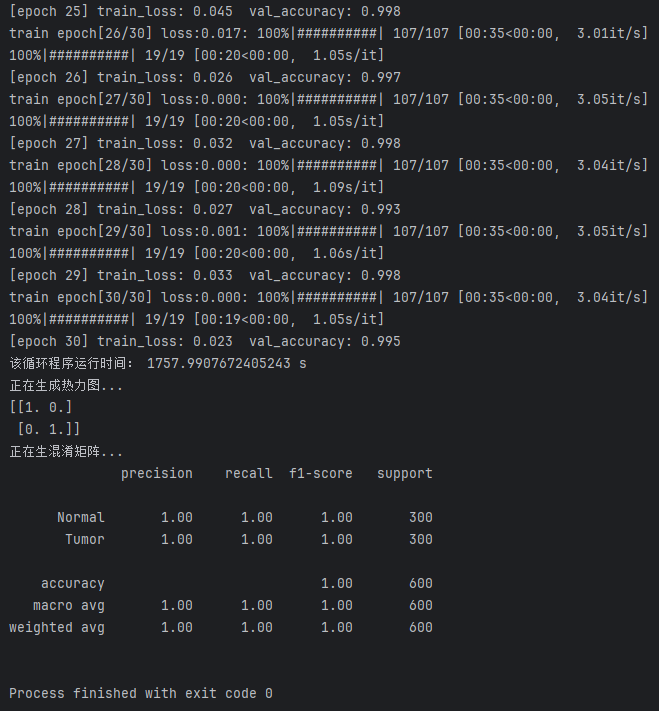
图21 VGG16训练日志
表8 模型训练日志概要志
功能展示
本系统基于深度学习卷积神经网络,旨在实现肾脏肿瘤影像的自动诊断与分类。系统集成了多种深度学习模型,包括ResNet50、VGG16和Swin Transformer,用于对肾脏肿瘤影像进行特征提取、分类及诊断结果展示。通过对比不同模型的性能表现,本系统为肾脏肿瘤的智能化、标准化诊断提供了技术支撑。以下为主要功能界面的展示:
1. 系统主界面展示
系统主界面集成了肾脏肿瘤影像上传、模型选择、实时分析及诊断结果展示等功能。用户可以在界面中直观选择不同的深度学习模型(如ResNet50、VGG16和Swin Transformer),上传肾脏肿瘤影像后,系统将自动进行特征提取与分类分析,并生成对应的诊断结果。界面支持对模型预测结果的可视化展示,方便科研人员和临床医生对比不同模型在肾脏肿瘤影像诊断中的性能表现。
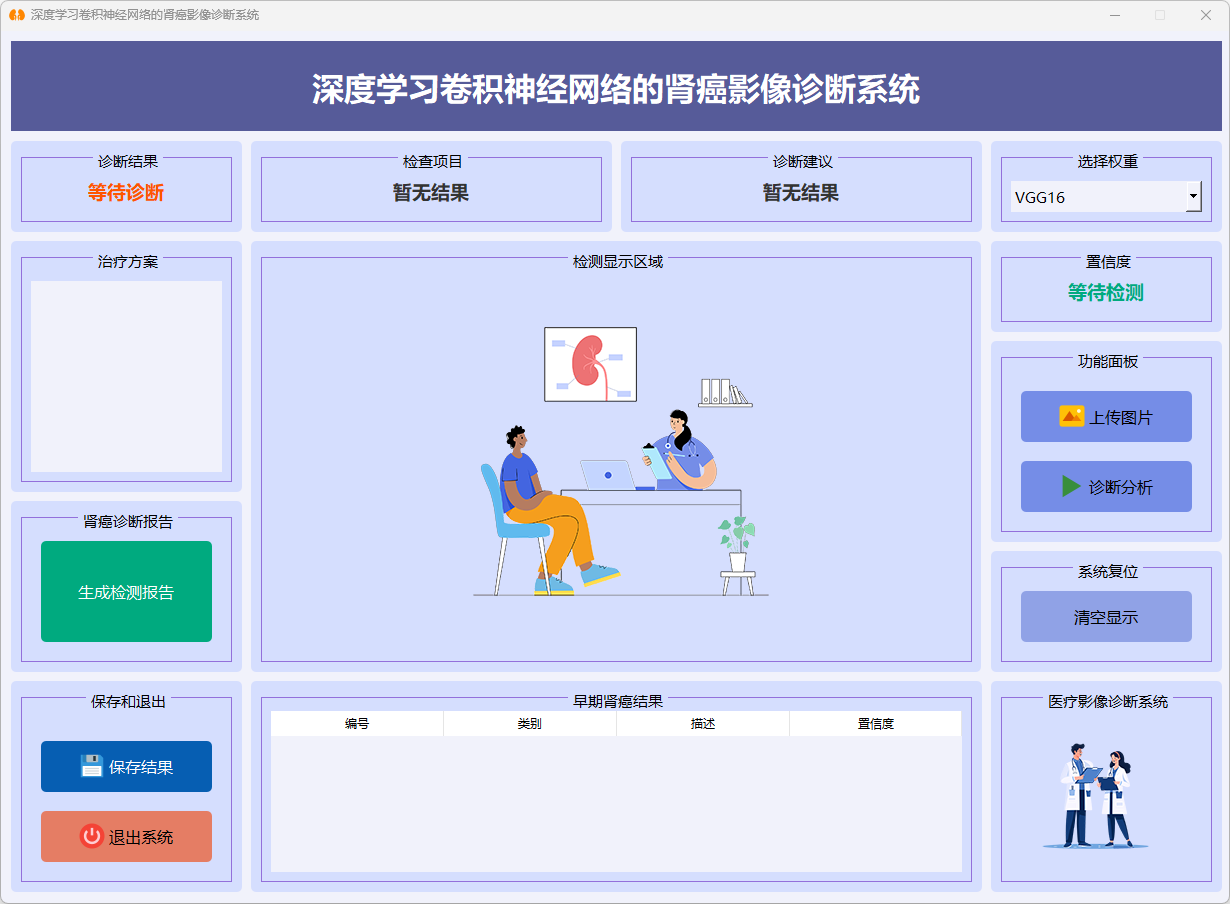
图22 系统主界面
2. 图片检测功能
系统支持对肾脏肿瘤影像进行快速诊断。用户可以上传肾脏肿瘤影像样本,系统会自动进行分析,识别肾脏肿瘤的类型,并给出诊断结果、分类标签和置信度评分。诊断结果通过清晰的文本和图表直观呈现,帮助科研人员和临床医生快速评估不同模型(如ResNet50、VGG16和Swin Transformer)在肾脏肿瘤影像诊断中的性能表现,从而为进一步的医疗决策提供支持。
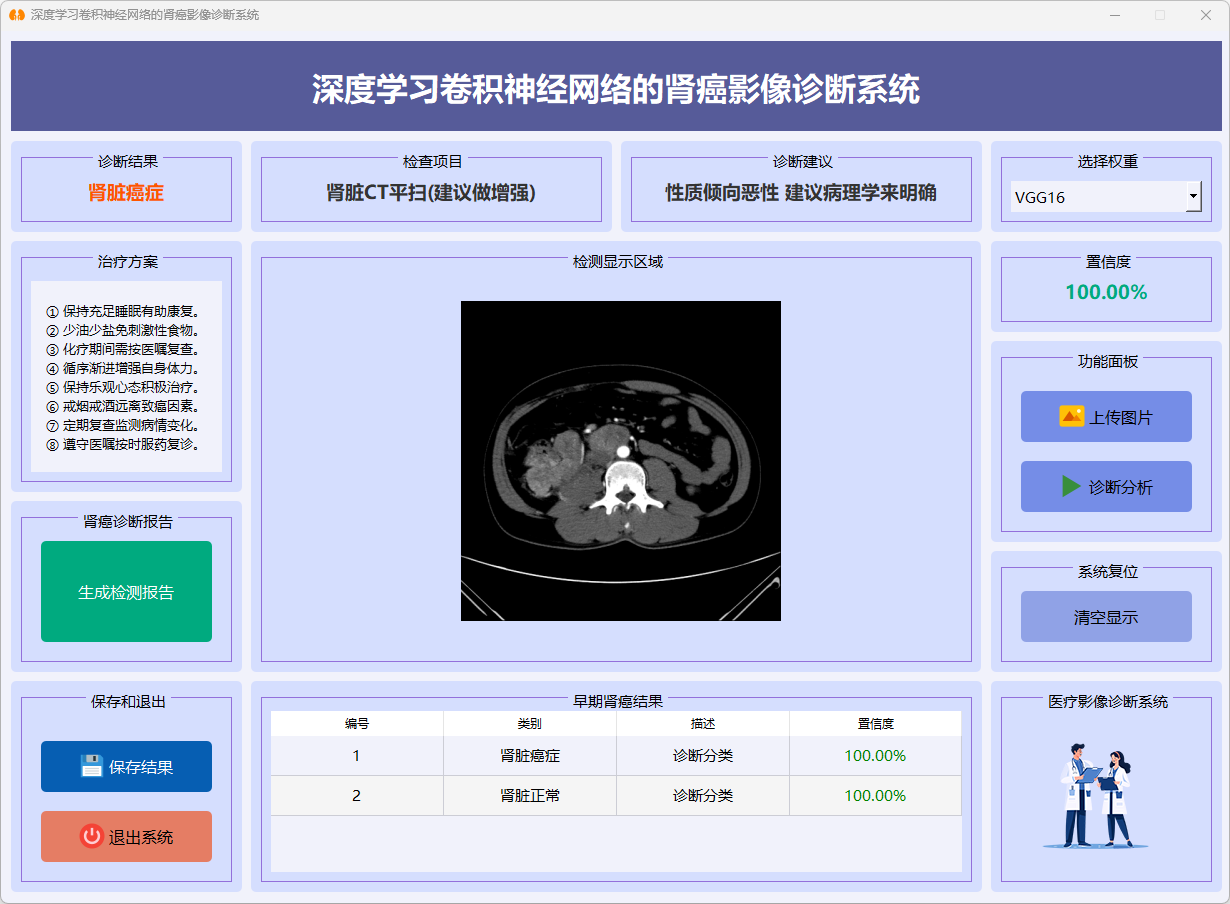
图23 肾脏癌症(VGG16)
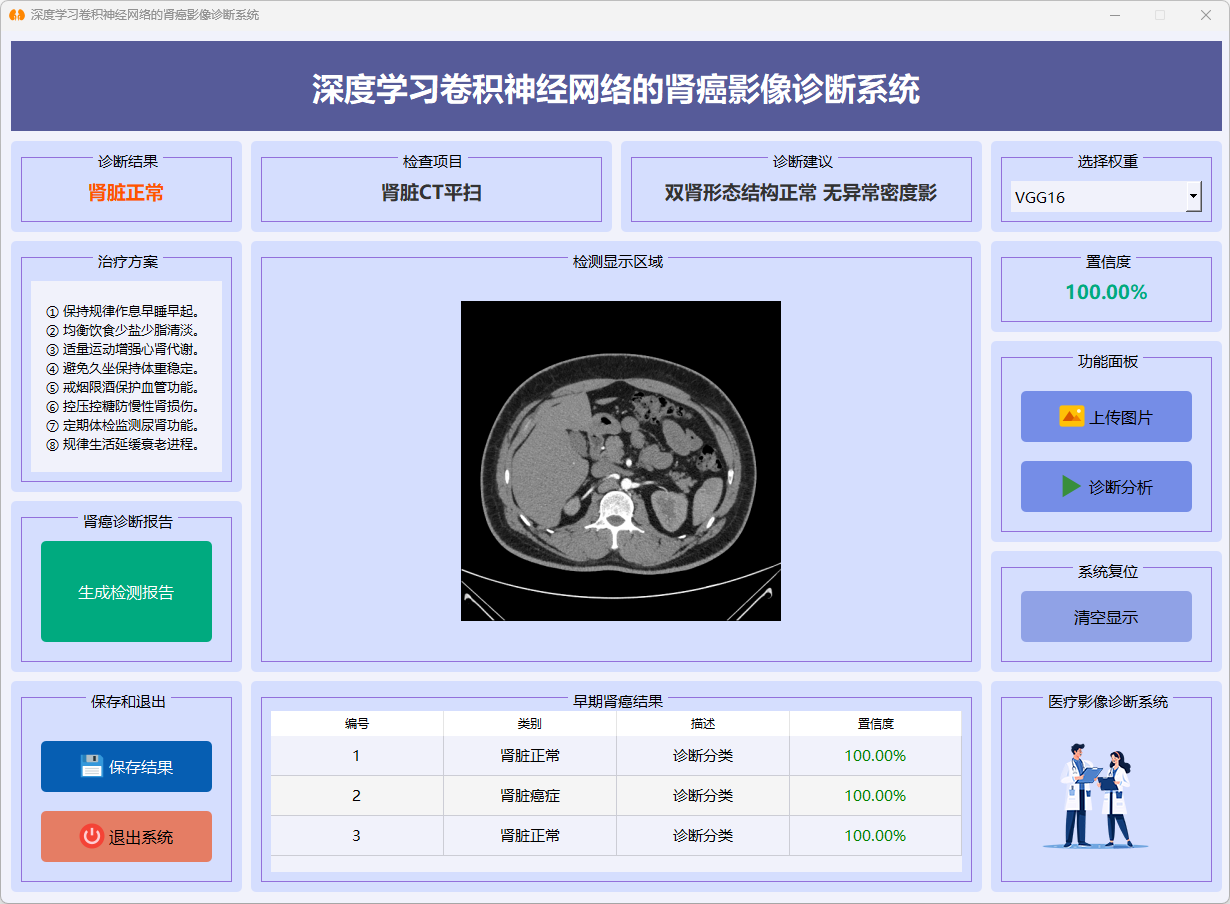
图24 肾脏正常(VGG16)
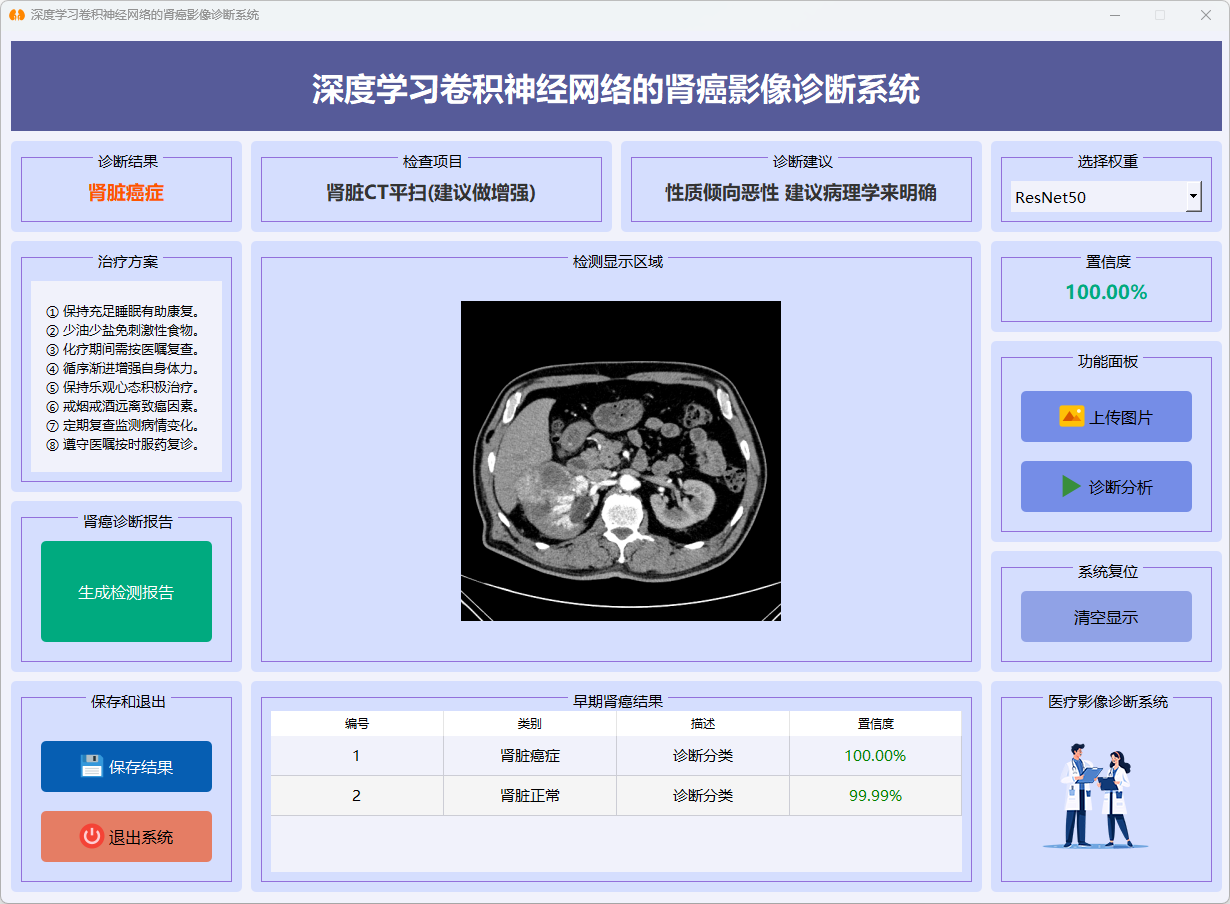
图25 肾脏癌症(ResNet50)
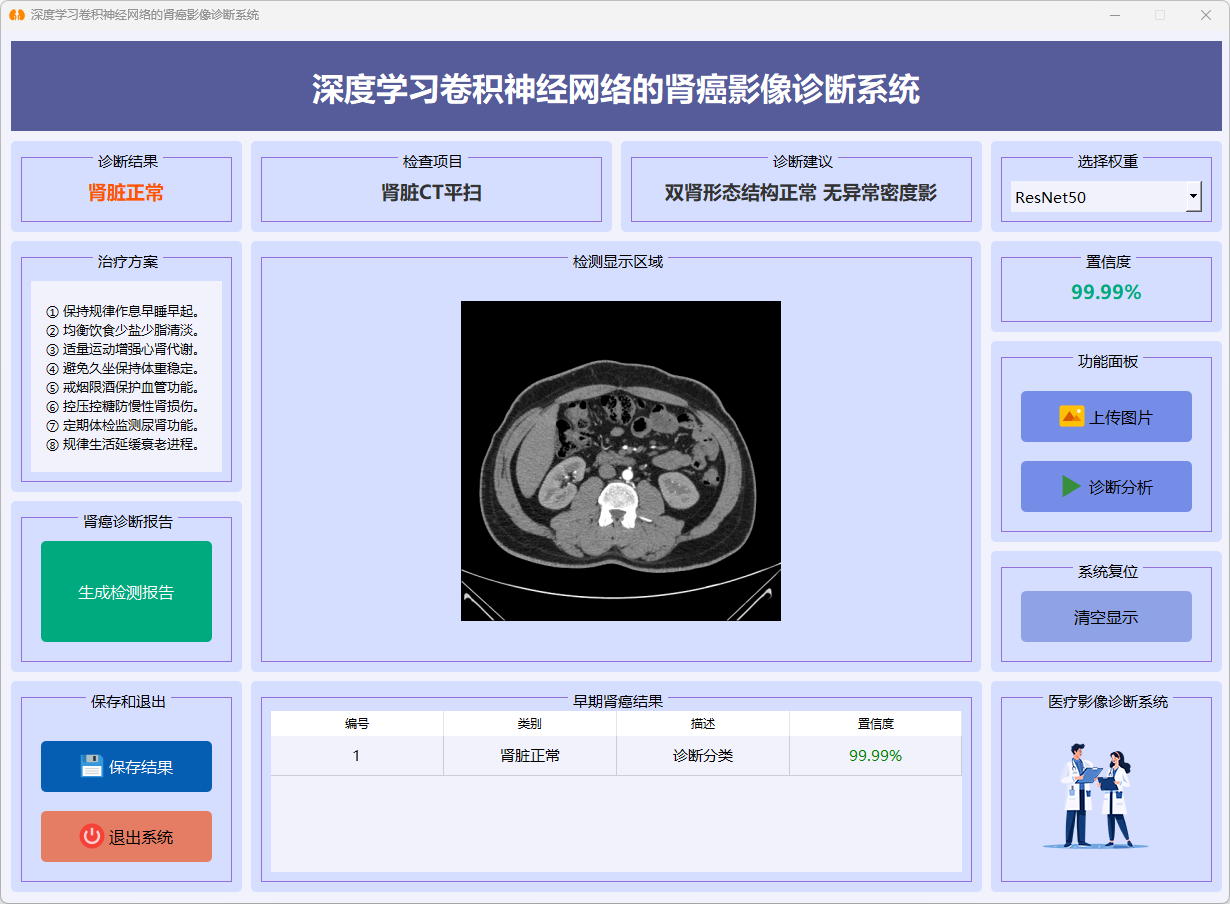
图26 肾脏正常(ResNet50)
![]()
图27 肾脏癌症(Swin-Transformer)
![]()
图28 肾脏癌症(Swin-Transformer)
3. 保存结果
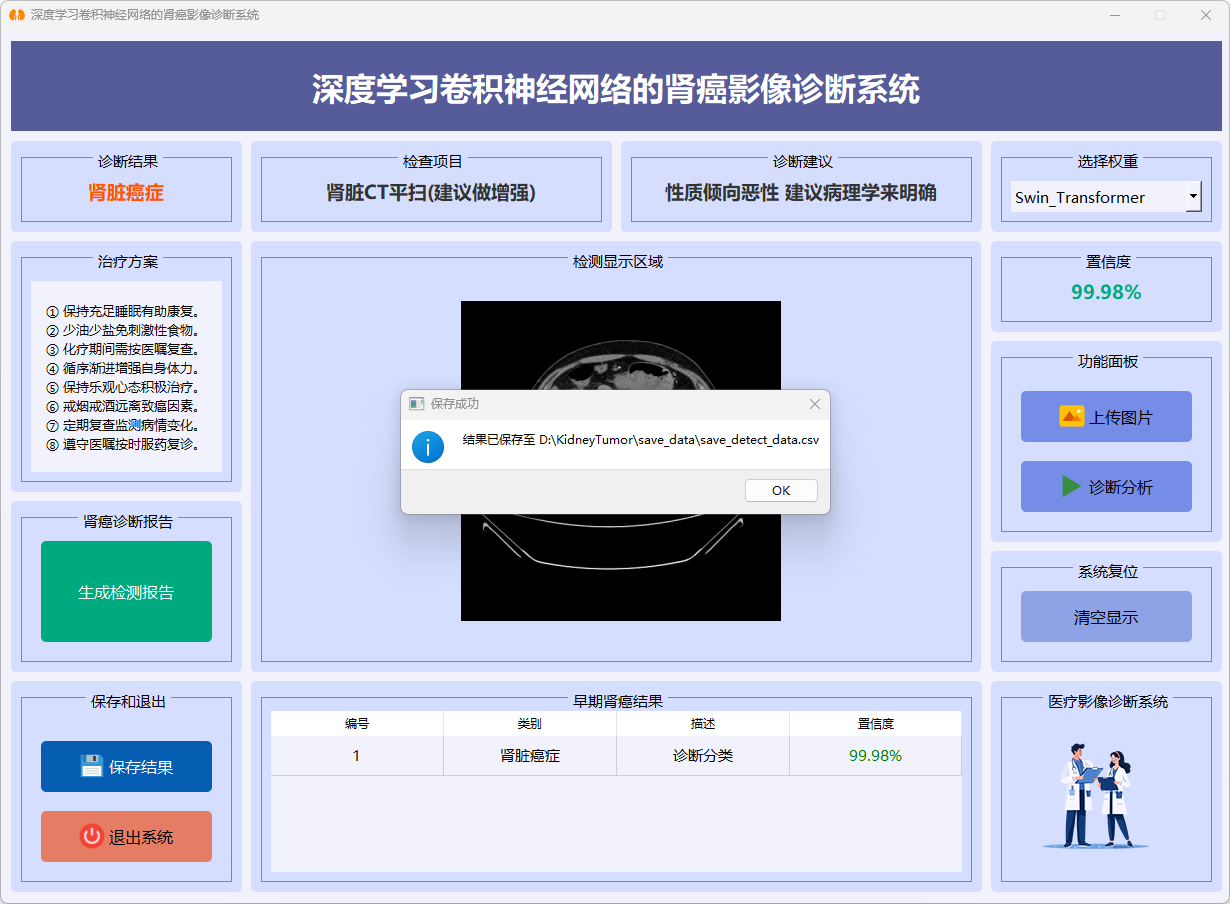
图29 结果保存
4. 生成医疗影像诊断报告
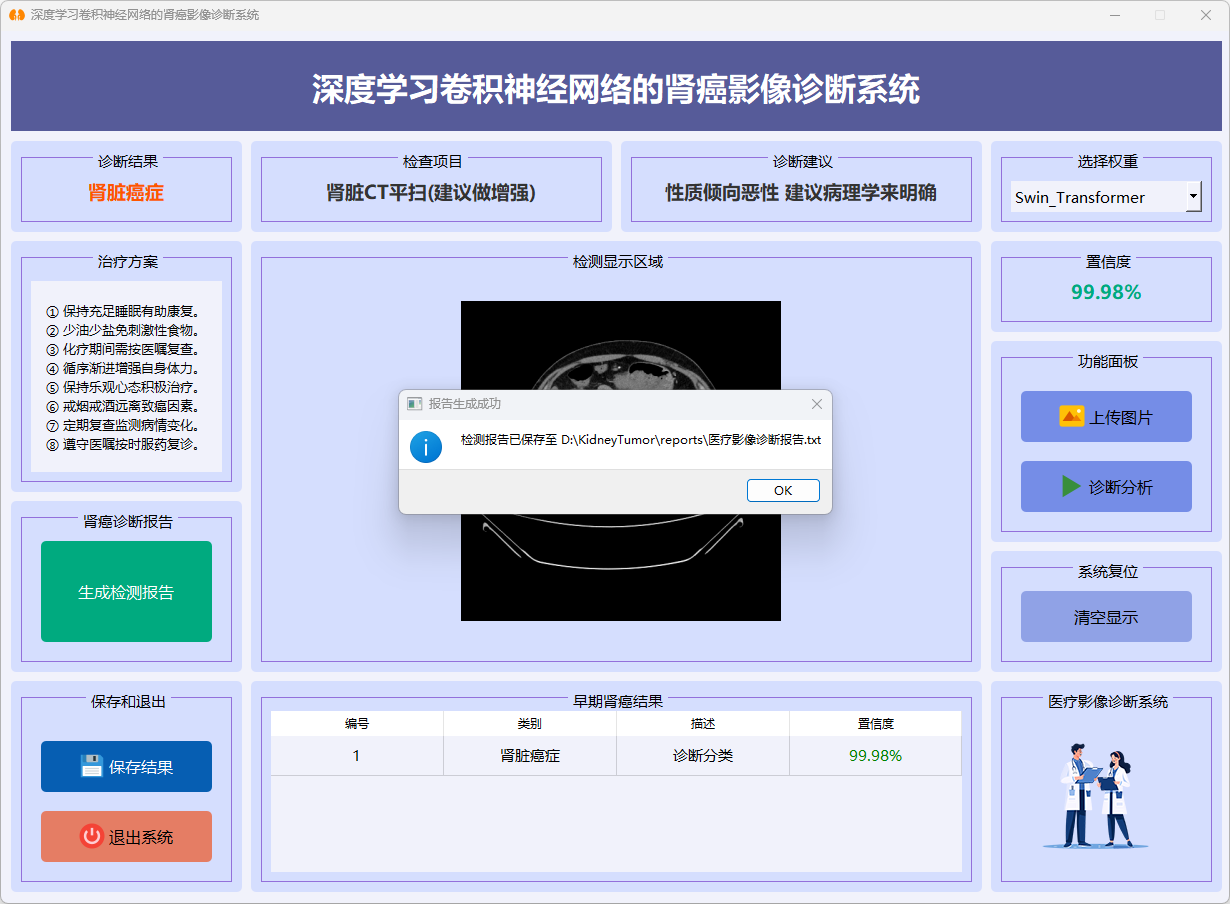
图30 成功生成医疗影像诊断报告
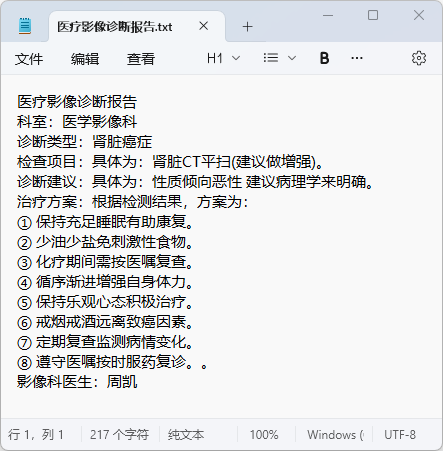
图31 诊断报告
界面设计
本系统的图形用户界面采用PyQt5框架开发,致力于打造直观、高效且流畅的交互体验。通过精心设计的界面布局和模块化架构,系统功能得以清晰呈现,并确保各项操作的高效执行,全面提升用户使用体验。
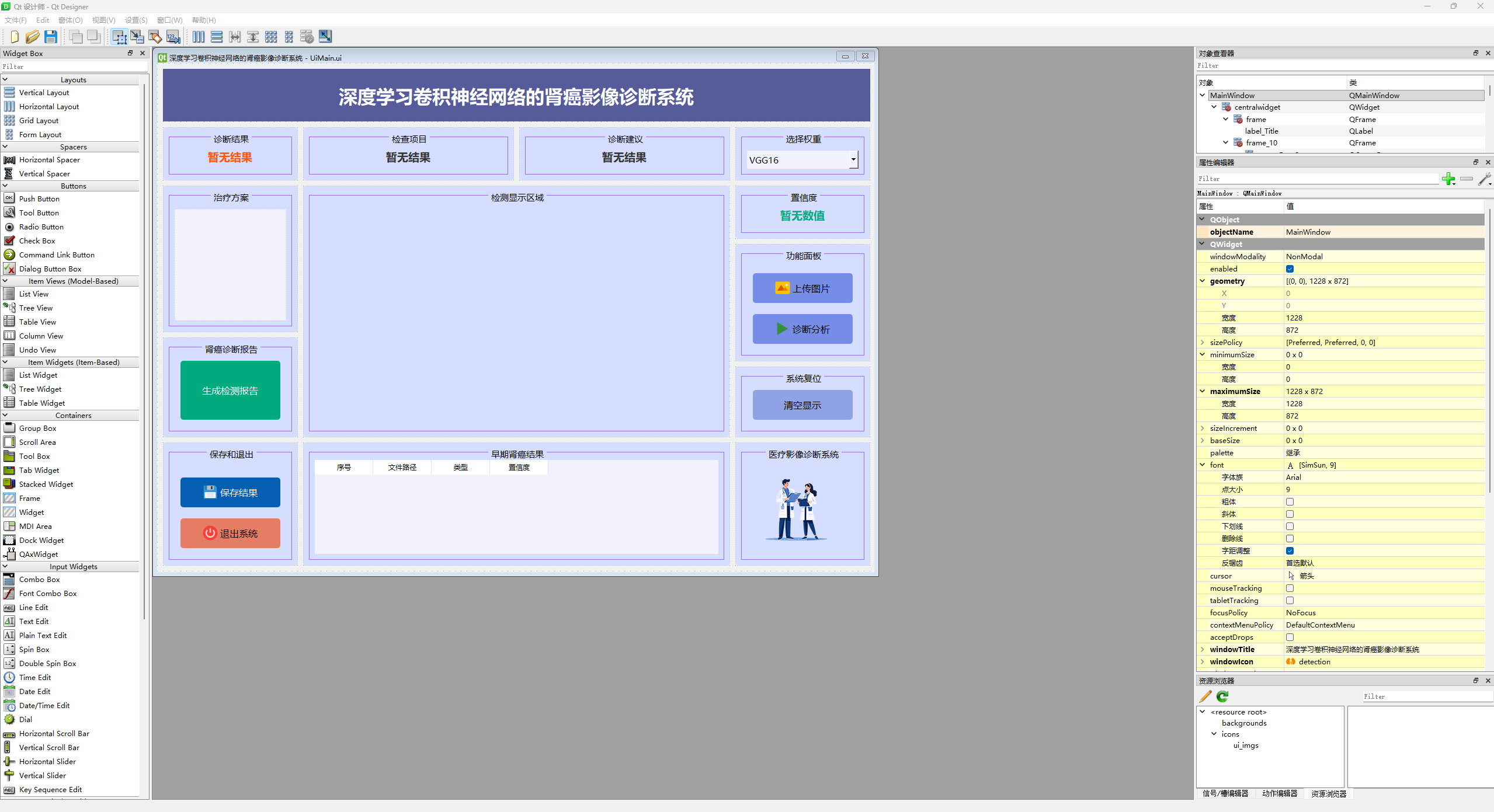
图32 PyQt5主控面板界面
该界面展示了基于PyQt5框架精心设计的医疗影像诊断系统,界面布局简洁、直观且高度集成。通过巧妙的模块化设计,系统涵盖了多项功能模块,确保用户能够高效、流畅地进行操作与交互,充分体现了系统在医学领域中的智能化与人性化设计。
文件清单
1.核心文件

2.训练文件
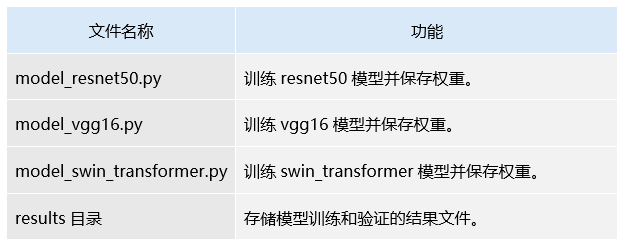
3.训练模型
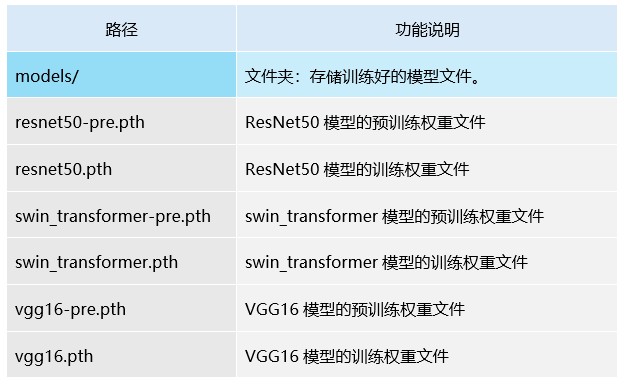
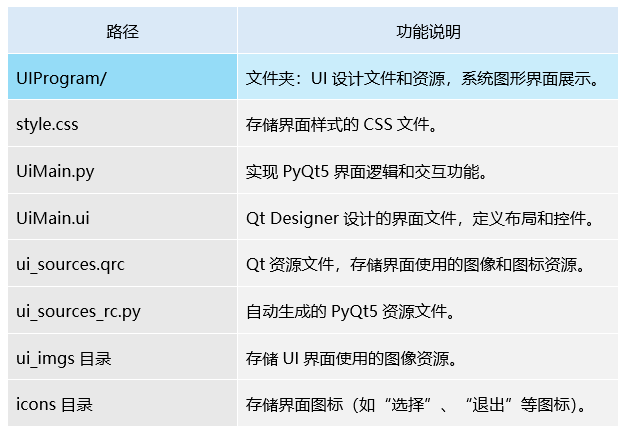
4.界面文件
5.数据集文件

服务项目
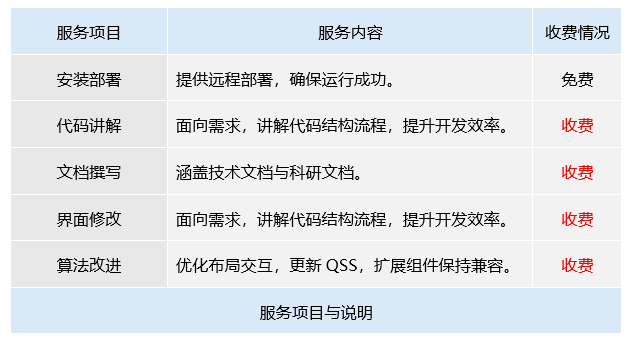
联系我们

官方声明
(1)实验环境真实性与合规性声明:
本研究所使用的硬件与软件环境均为真实可复现的配置,未采用虚构实验平台或虚拟模拟环境。实验平台为作者自主购买的外星人笔记本(Alienware)笔记本,具体硬件参数详见表。软件环境涵盖操作系统、开发工具、深度学习框架等,具体配置详见表,所有软件组件均来源于官方渠道或开源社区,并按照其许可协议合法安装与使用。
研究过程中严格遵循学术诚信和实验可复现性要求,确保所有实验数据、训练过程与结果均可在相同环境下被重复验证,符合科研规范与工程实践标准。
(2)版权声明:
本算法改进中涉及的文字、图片、表格、程序代码及实验数据,除特别注明外,均由2zcode.Bob独立完成。未经2zcode官方书面许可,任何单位或个人不得擅自复制、传播、修改、转发或用于商业用途。如需引用本研究内容,请遵循学术规范,注明出处,并不得歪曲或误用相关结论。
本研究所使用的第三方开源工具、框架及数据资源均已在文中明确标注,并严格遵守其相应的开源许可协议。使用过程中无违反知识产权相关法规,且全部用于非商业性学术研究用途。
评论(0)