

学生课堂行为和表情数据集主要用于对学生在课堂上的行为和情绪进行分析与监控。该数据集包括学生在课堂中的各种行为和表情标签,旨在帮助系统识别和分析学生的专注度与情绪反应,提供实时反馈,辅助教师进行课堂管理。数据集的内容通常包括图像或视频数据,并标注了不同类别的学生行为和表情。
数据集信息
编号:Dataset-4
大小:274M
整理:Bob
数据集概览
数据类型:
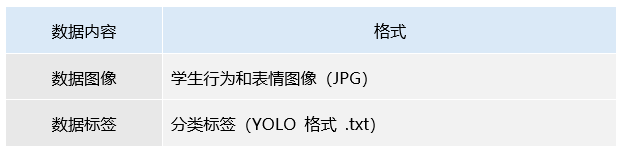
表1 数据类型与格式
数据规模:
(1)数据集划分直方图
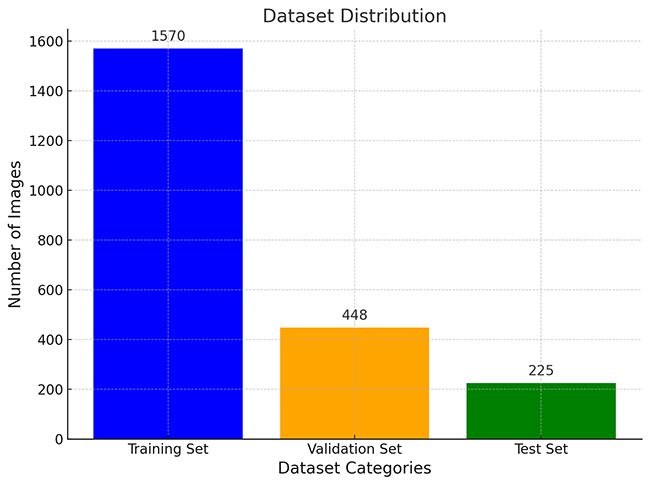
图1 数据集划分直方图
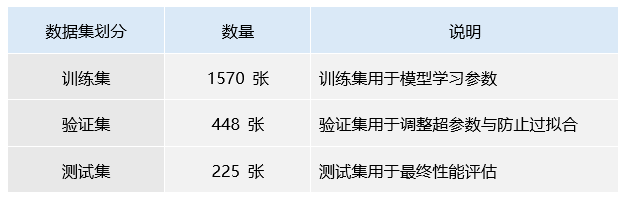
表2 数据集划分与规模
(2)数据集划分饼图
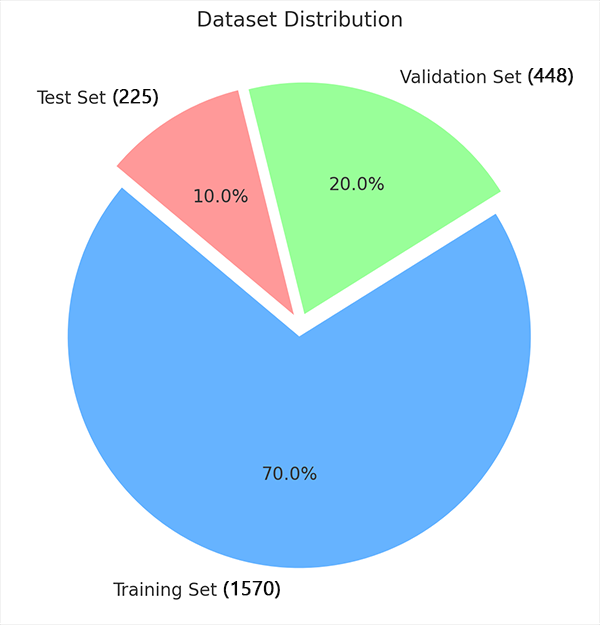
图2 数据集划分饼图
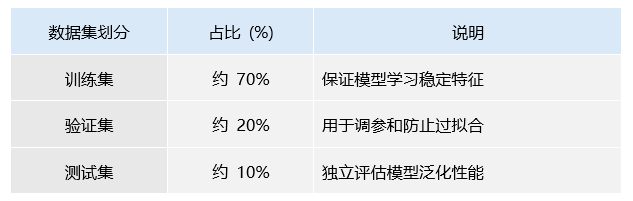
表3 数据集比例及作用
任务类型:
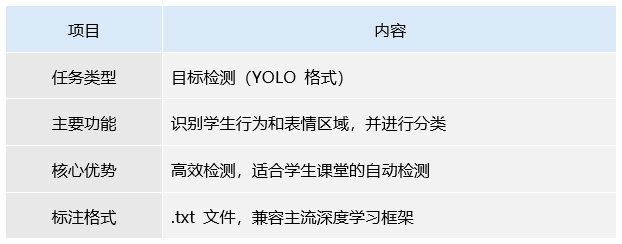
表4 任务类型说明
数据集类别
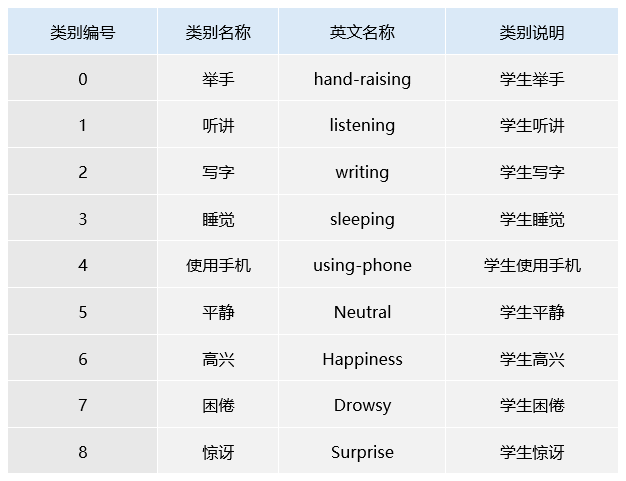
表5 类别定义
数据集来源

表6 数据集来源与说明
数据集用途
本数据集可用于:
(1)学生行为与表情检测与分类模型训练(YOLOv10等深度学习模型)。
(2)教室管理辅助(学生行为和表情分析与专注度检测)。
(3)算法性能对比(Benchmark测试与对比实验)。
(4)教学与科研(课堂行为与表情识别课程实验数据)。
数据集须知
(1)类别不平衡:某些学生行为和表情的样本较少,需考虑类别权重或使用Focal Loss优化。
(2)图像格式:JPG/PNG格式,缺少学生专注度的定量信息,适合行为和表情检测与分类。
(3)匿名化处理:已去除学生个人信息,确保数据安全。
数据集性能
训练与验证性能曲线:
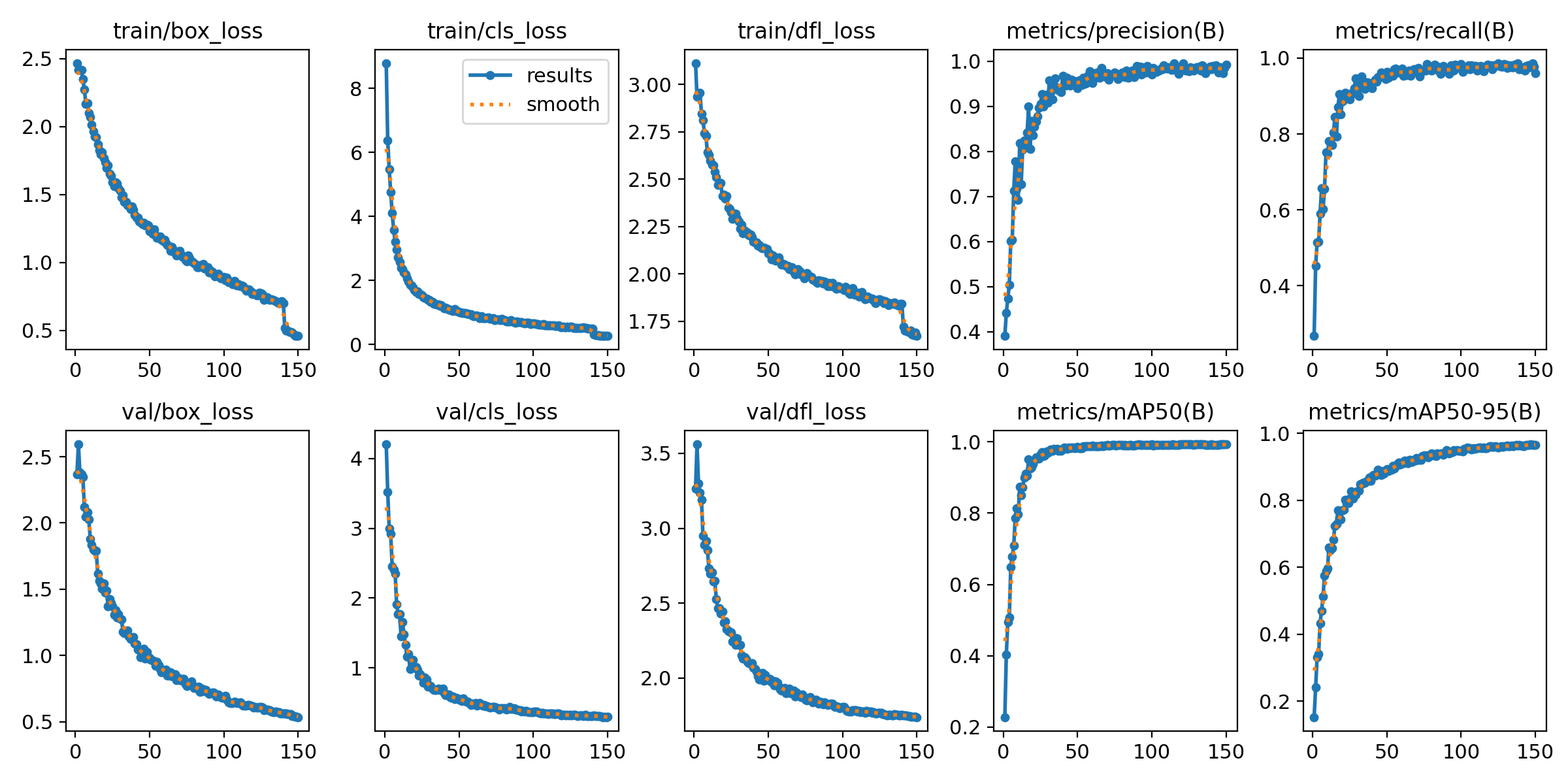
图3 YOLOv10 模型训练与验证性能曲线
该图展示了模型在训练和验证过程中的损失与评估指标,表明随着训练轮次的增加,损失逐渐降低,精度和召回率不断提升,显示出模型训练的有效性和稳定性。
精确率-召回率曲线(Box与Mask):
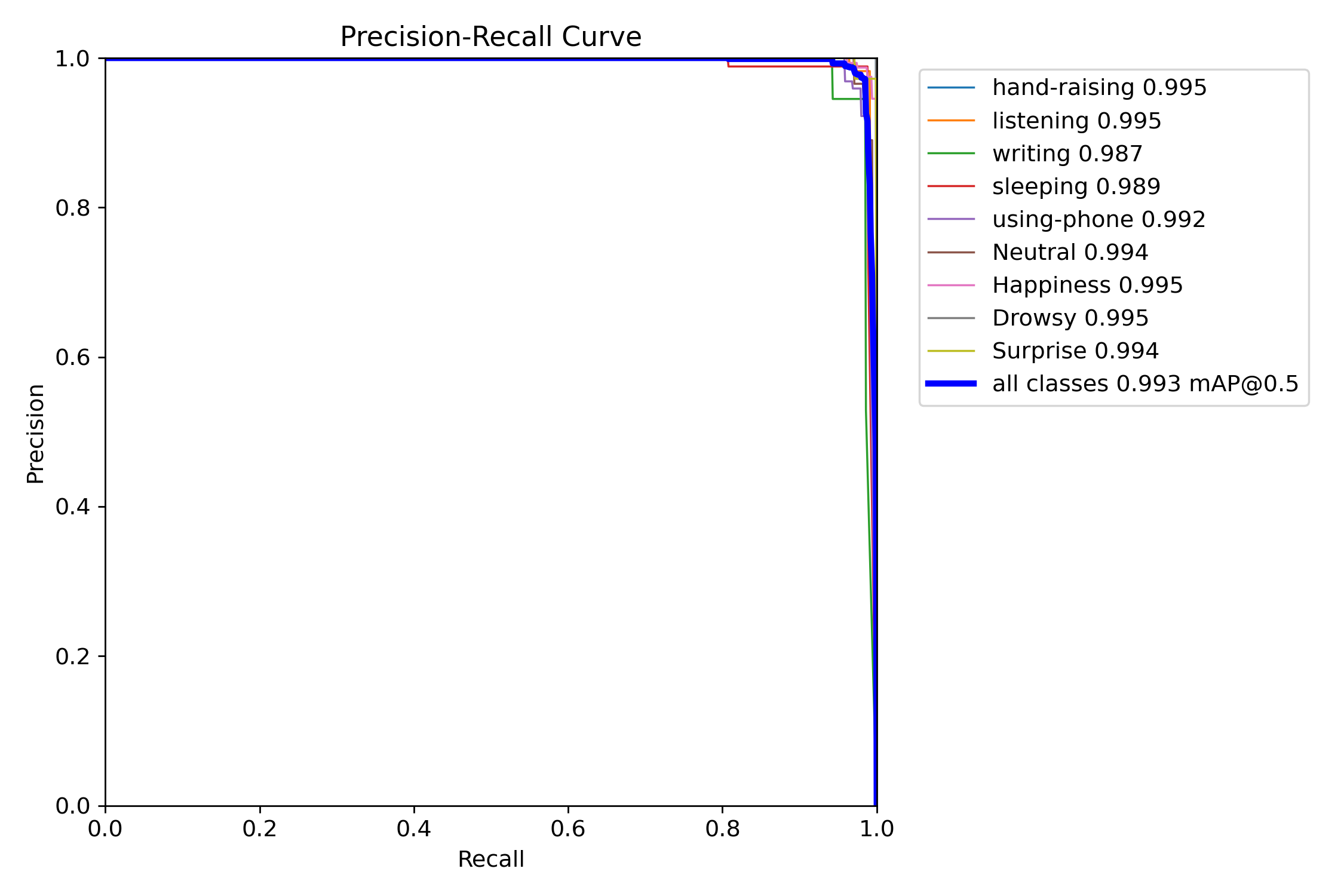
图4 PR曲线
该图展示了不同类别(如举手、听讲、写字等)的精度-召回率曲线,并显示了每个类别的mAP@0.5值,所有类别的mAP@0.5均接近1.0,表明模型在各个类别的精度和召回率上均表现优异。
混淆矩阵与归一化混淆矩阵:
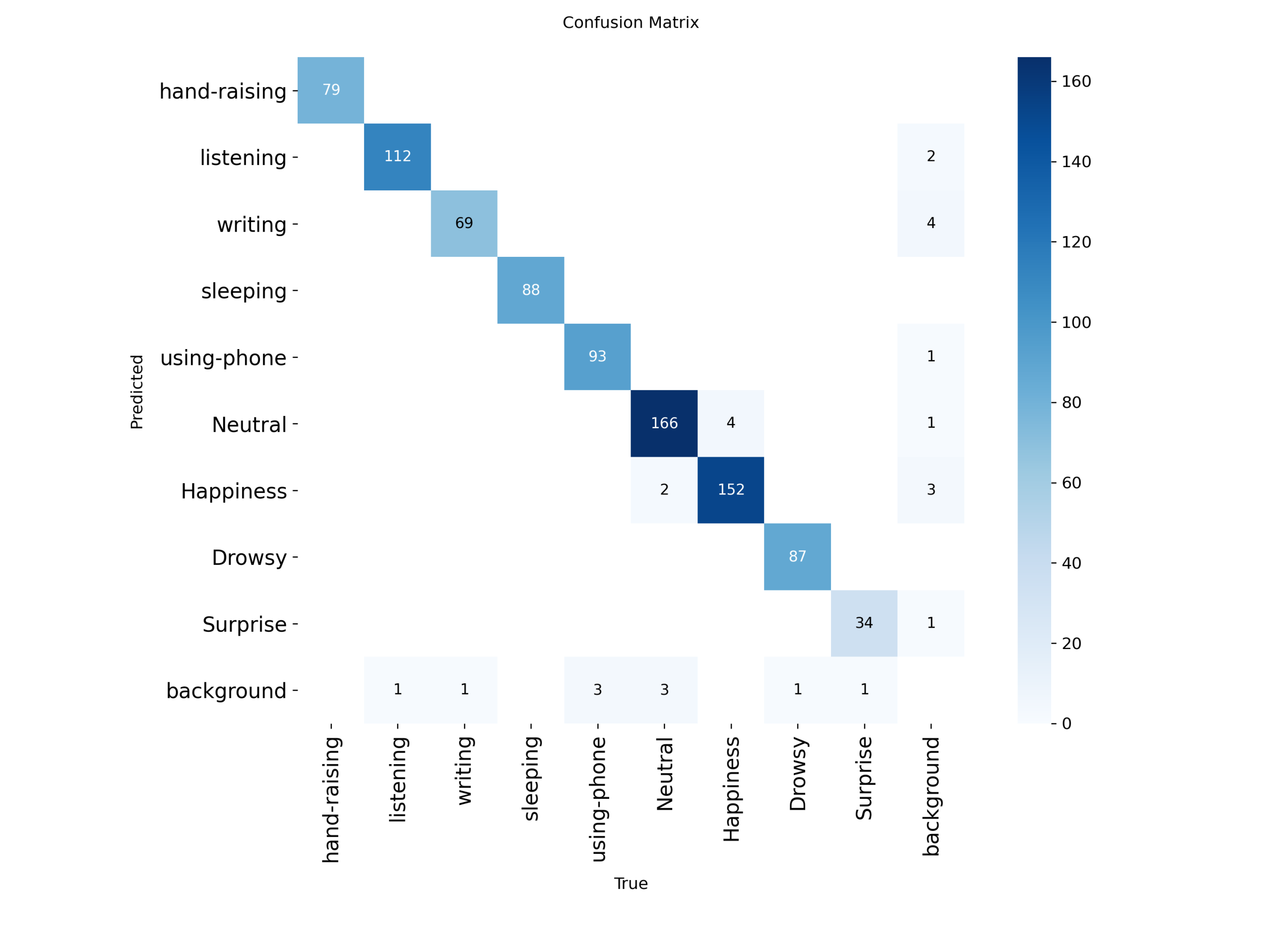
图5 混淆矩阵
该混淆矩阵显示了模型在不同类别的预测情况,模型对大部分类别(如举手、听讲、写字等)的预测准确性较高,且误分类主要集中在少数类别之间。
训练数据可视化

图6 训练与验证数据可视化对比
这张图展示了训练样本和验证样本的可视化,左侧是训练集图像,右侧是验证集图像,并标注了相应的学生行为和表情类型,有助于理解模型如何学习并检测不同类型的行为和表情。
联系我们

官方声明
(1)实验环境真实性与合规性声明:
本研究所使用的硬件与软件环境均为真实可复现的配置,未采用虚构实验平台或虚拟模拟环境。实验平台为作者自主购买的惠普(HP)暗影精灵 10 台式整机,具体硬件参数详见表。软件环境涵盖操作系统、开发工具、深度学习框架等,具体配置详见表,所有软件组件均来源于官方渠道或开源社区,并按照其许可协议合法安装与使用。
研究过程中严格遵循学术诚信和实验可复现性要求,确保所有实验数据、训练过程与结果均可在相同环境下被重复验证,符合科研规范与工程实践标准。
(2)版权声明:
本算法改进中涉及的文字、图片、表格、程序代码及实验数据,除特别注明外,均由2zcode.Bob独立完成。未经2zcode官方书面许可,任何单位或个人不得擅自复制、传播、修改、转发或用于商业用途。如需引用本研究内容,请遵循学术规范,注明出处,并不得歪曲或误用相关结论。
本研究所使用的第三方开源工具、框架及数据资源均已在文中明确标注,并严格遵守其相应的开源许可协议。使用过程中无违反知识产权相关法规,且全部用于非商业性学术研究用途。
评论(0)