

摘要:本文针对海量新闻文本场景下信息过载、人工摘要效率低以及用户难以快速获取核心内容等问题,设计并实现了一套基于 LSTM 的新闻文本摘要系统。系统以新闻标题与新闻正文为输入,围绕“文本预处理—模型训练—摘要生成—结果展示”构建完整流程,旨在 提升新闻信息的提炼效率与系统展示性,为新闻内容智能处理提供可实现的工程方案。
项目简介
基于LSTM的新闻文本摘要系统,能够对输入的新闻正文进行自动摘要生成与可视化展示。
系统概述
在系统设计上,项目采用 Flask 构建 Web 交互界面,使用 PyTorch 搭建摘要生成模型,核心模型为基于BiLSTM编码器和注意力机制解码器的 Seq2Seq 结构。系统在前端提供新闻输入页与摘要结果页,在后端实现了文本预处理、词表构建、 数据过滤、模型训练、模型推理和结果状态控制等功能模块。针对新闻文本特点,系统引入了分词、停用词过滤、无效样本过滤、 词表重建、训练早停与兜底摘要等机制,以增强整体稳定性与可用性。
在实现过程中,系统重点完成了数据处理链路与模型训练链路的打通。数据层能够读取预处理后的新闻文本数据,并对空摘要样本 和脏数据标记进行过滤;训练层能够完成有效样本统计、LSTM 模型训练、验证集评估、teacher forcing 衰减以及最优模型权重保存;推理层能够根据输入新闻正文生成摘要,并在输出质量较差或语义偏离原文时自动回退到基于原文首句的兜底摘要策略。最终,系统实现了新闻摘要的自动生成与可视化展示,具备较完整的项目运行流程。
实验与运行结果表明,该系统已经能够完成新闻文本摘要任务的基本功能,实现从模型训练到页面展示的闭环流程。尽管受限于当前训练数据规模与标注质量,模型在摘要准确性和泛化能力方面仍有进一步提升空间,但系统在工程实现、流程完整性和展示效果 方面已具备较好的应用基础。该研究为基于 LSTM 的新闻文本摘要系统设计提供了实践参考,同时也为后续引入更高质量数据集和更优摘要模型奠定了基础。
系统架构
系统采用前后端分离架构,前端通过 Flask 提供新闻输入与摘要展示页面,后端集成文本预处理、词表构建、BiLSTM+Attention Seq2Seq 模型训练与推理、兜底摘要回退及结果状态控制等功能模块。
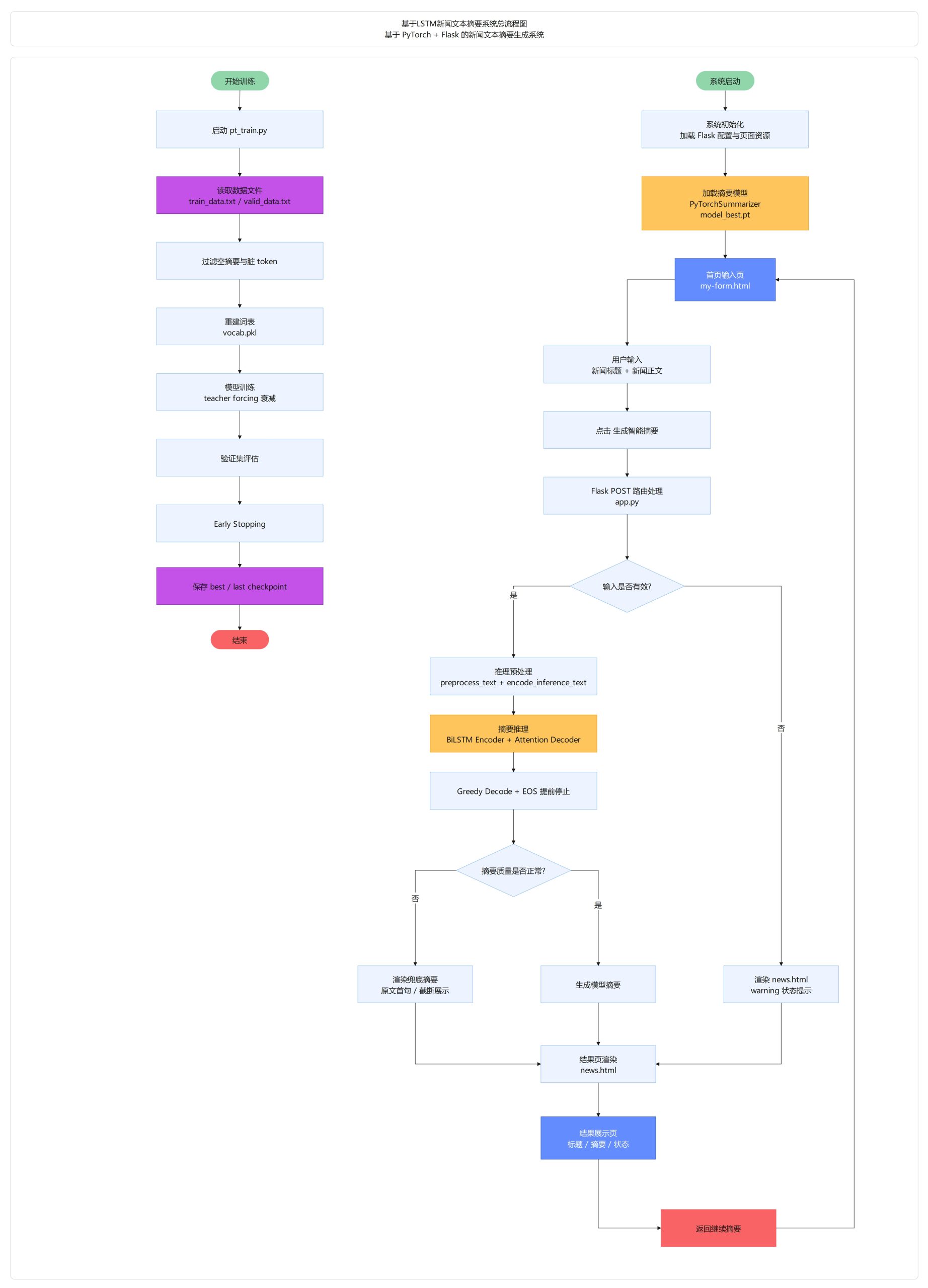
数据集构建
本数据集构建采用新闻文本的原始数据采集、文本清洗、分词处理、停用词过滤和摘要标签筛选相结合的方式,形成可用于LSTM新闻摘要模型训练与验证的结构化数据集。
数据集训练
数据集训练基于经过清洗、分词和标签筛选后的新闻文本数据,利用LSTM Seq2Seq模型完成新闻正文到摘要结果的监督学习训练。
运行:pt_train.py
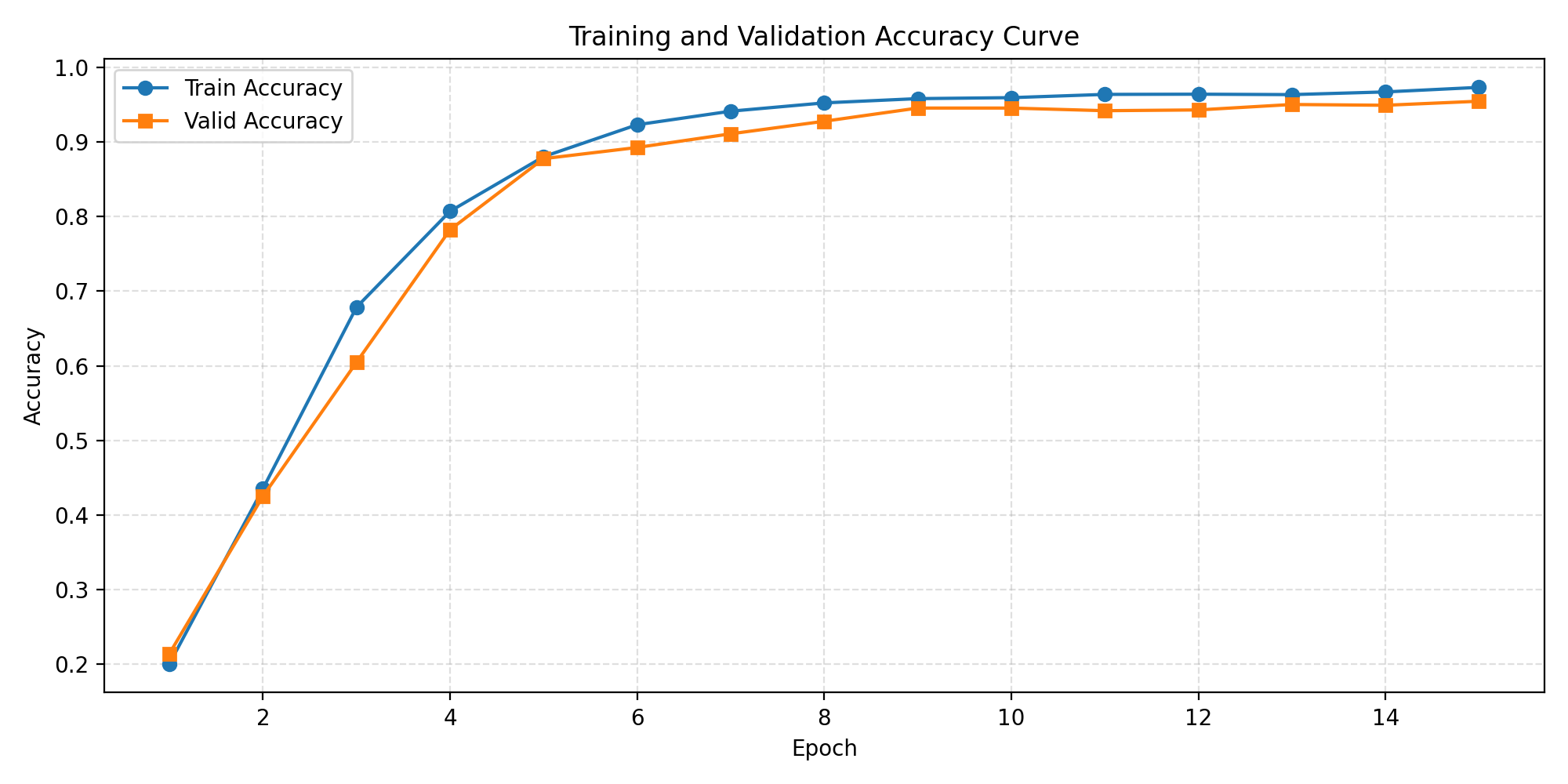
图1 Accuracy Curve
训练与验证准确率曲线。两条线从 20% 起步,前 5 轮快速攀升到 88%,之后增速放缓,最终稳定在 train 97% / valid 95.5%。两条线始终紧密贴合(差距约 2%),说明模型泛化能力好,没有过拟合。
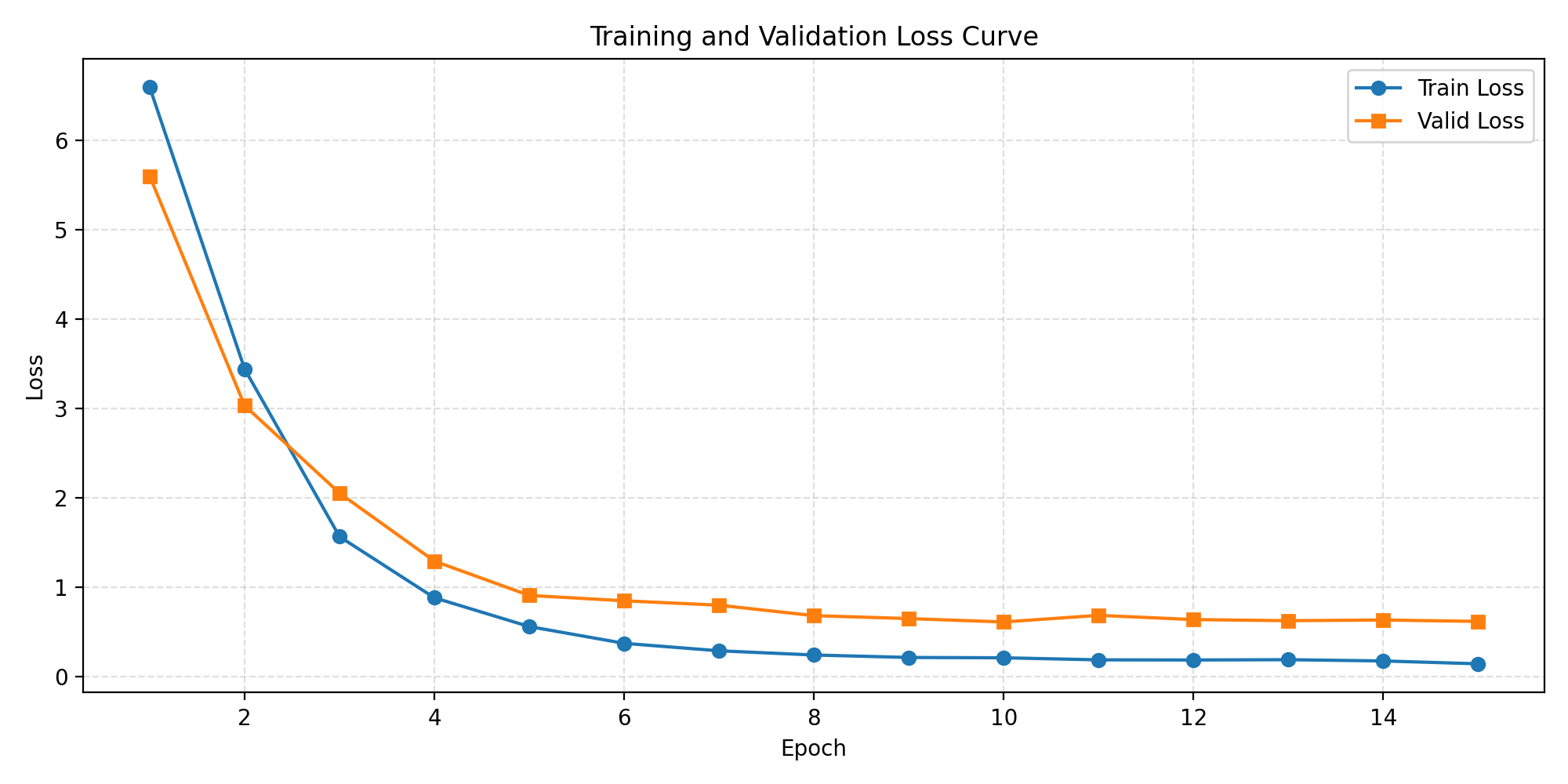
图2 Loss Curve
训练与验证损失曲线。Loss 从 6.5 急剧下降,epoch 5 后进入平台期。训练损失持续降到 0.14,验证损失在 0.6 附近趋于平稳。验证损失不再下降触发了 early stopping(epoch 15),这是正常的收敛行为——模型已经学到了数据中的主要模式。
项目结构
项目结构由前端展示层、后端业务层、数据处理层、模型训练层和模型推理层组成,形成了新闻输入、摘要生成、结果展示一体化的完整系统。
核心技术
项目核心技术包括 Flask Web 开发、PyTorch 深度学习框架、LSTM Seq2Seq 文本摘要模型、Attention 注意力机制、jieba 中文分词以及新闻文本预处理与词表构建技术。
快速开始
安装项目依赖后,先运行模型训练脚本生成摘要模型文件,再启动 Flask 应用,即可在浏览器中输入新闻标题与正文并生成摘要结果。
环境要求
项目运行环境建议为 Python 3.8 及以上版本,需安装 PyTorch、Flask、jieba 等相关依赖库,并具备可正常读取本地训练数据与模型文件的运行环境。
结果展示
运行app.py
图3 主界面
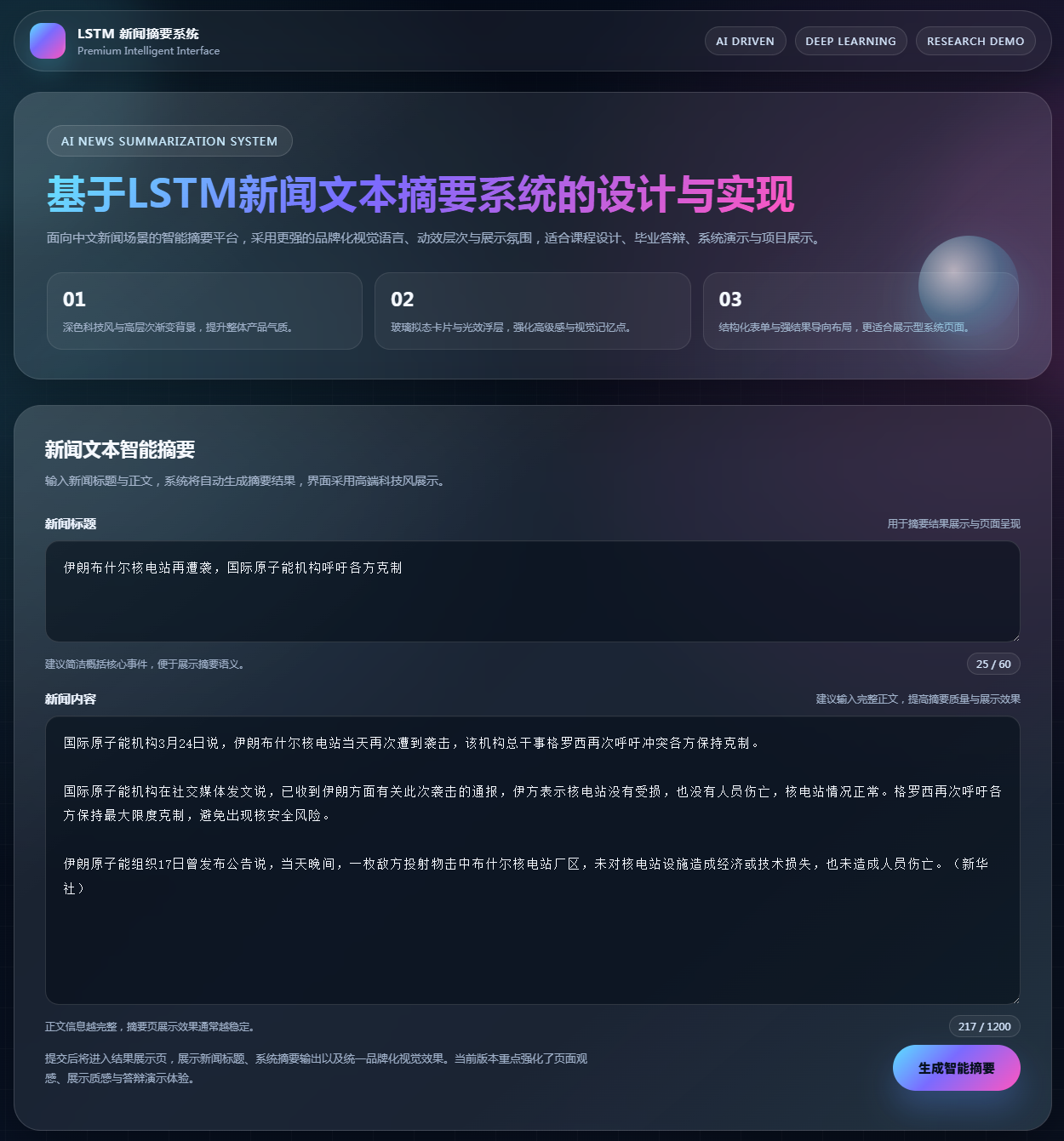
图4 短新闻内容
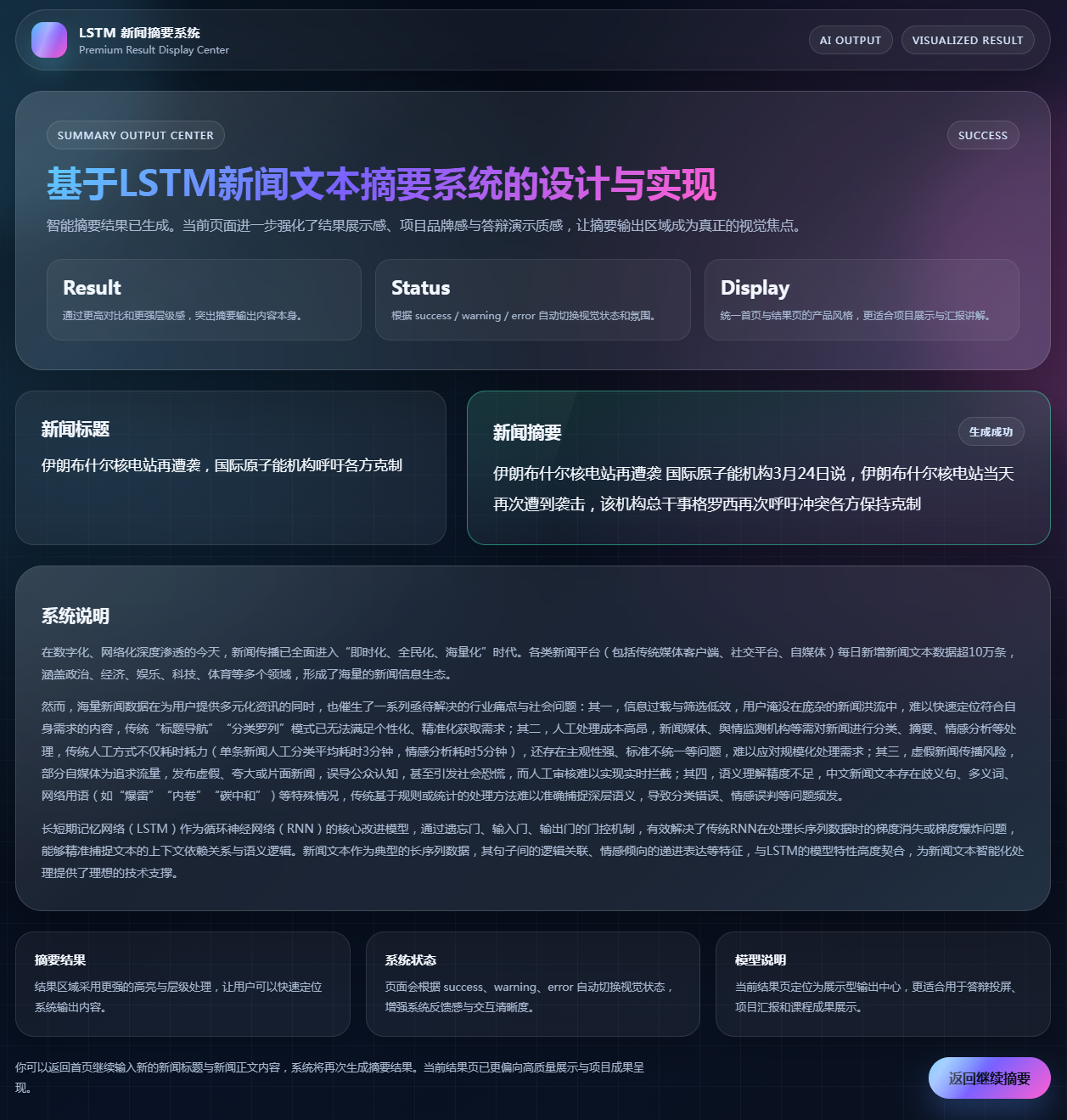
图5 短新闻摘要
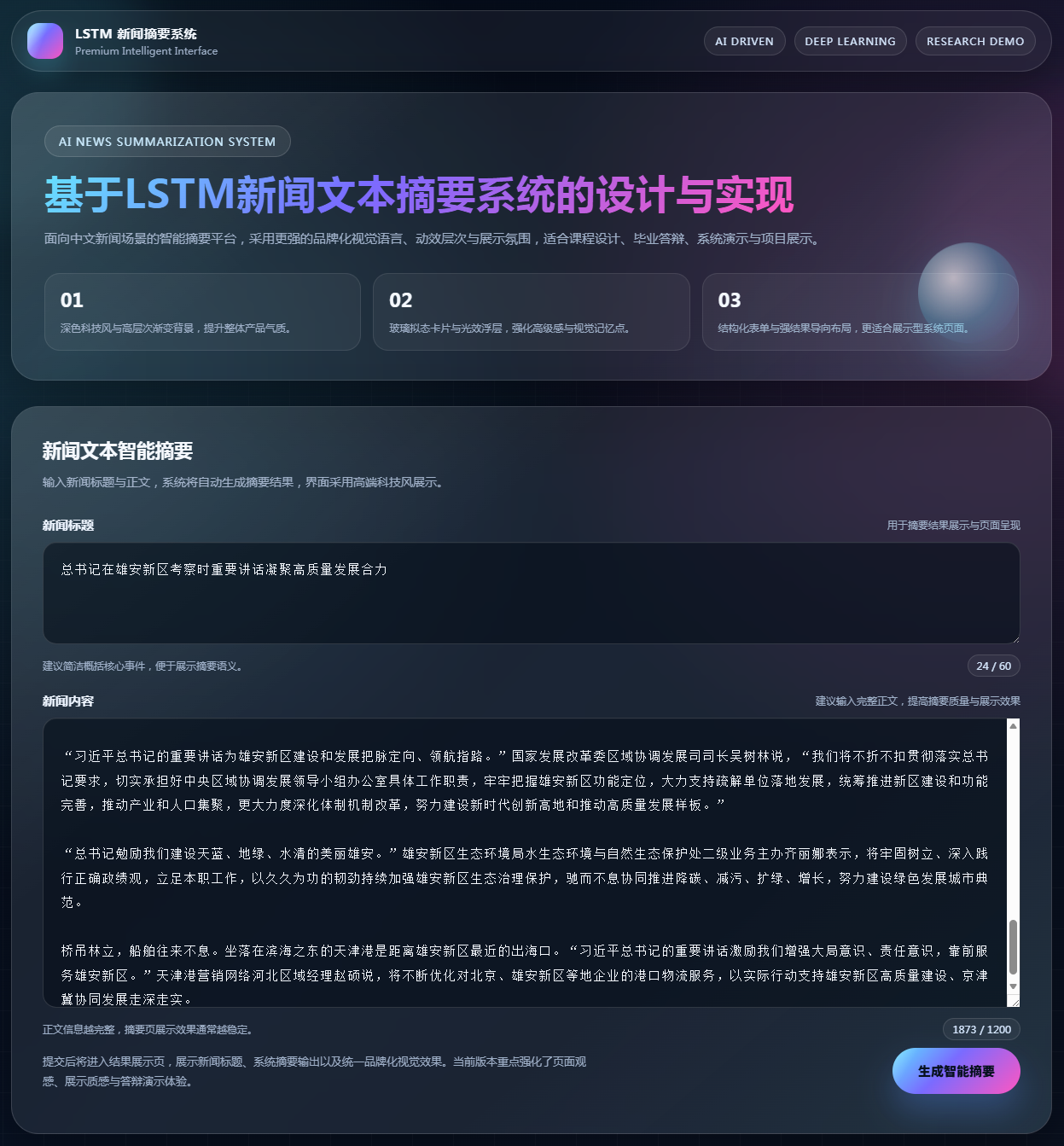
图6 长新闻内
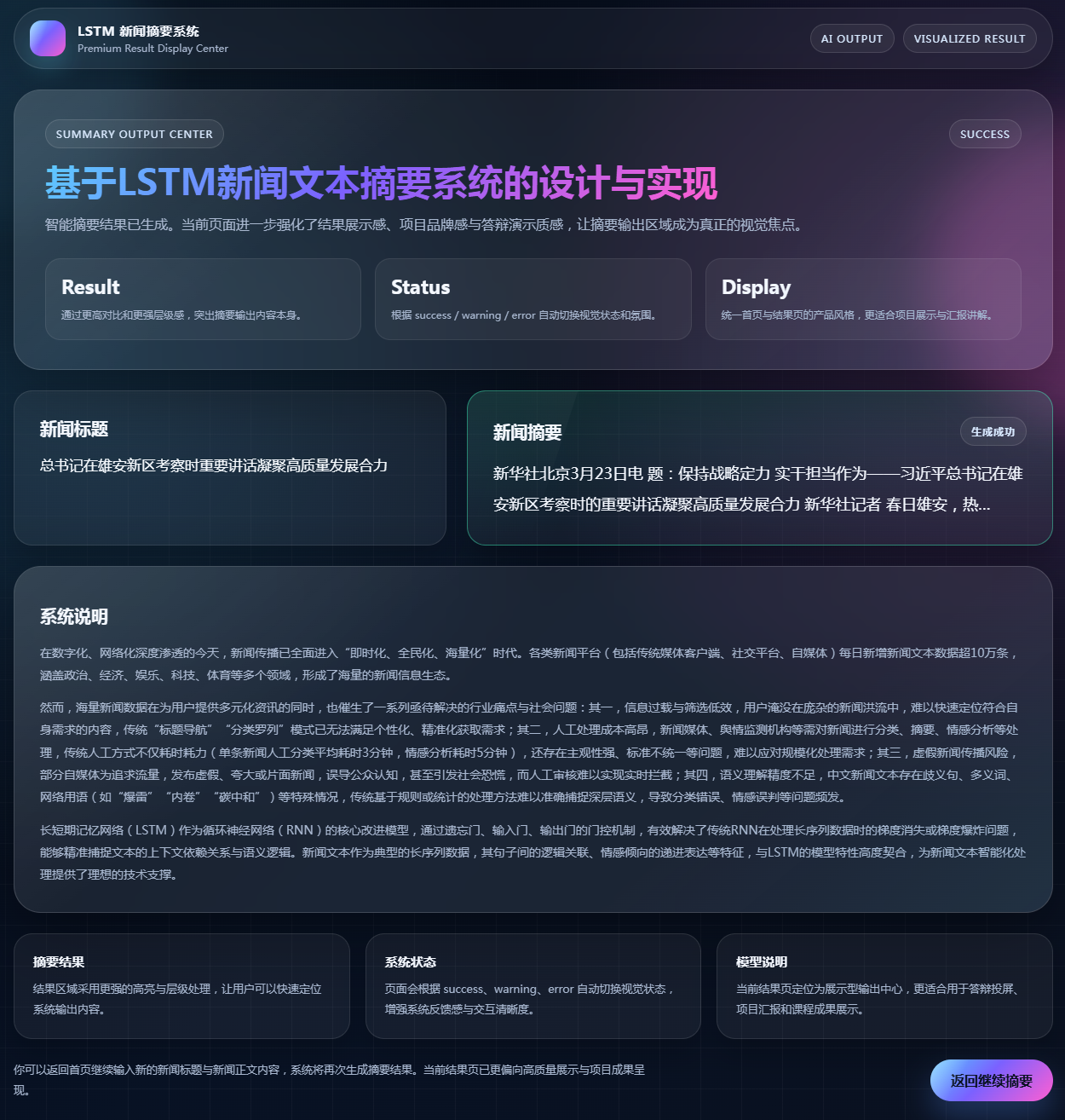
图7 长新闻摘要
结果点评
本项目设计并实现了一个基于 Seq2Seq with Attention 架构的中文抽取式文本摘要系统。在数据层面,项目基于约 2000 条中文新闻语料,通过 jieba 分词、停用词过滤等预处理构建训练集,并采用 token 丢弃、token 交换和随机截断三种数据增强策略将训练样本扩充至近 8000 条,有效缓解了小样本场景下的过拟合问题。在模型层面,采用双层 GRU 编码器-解码器结构,结合 Bahdanau 注意力机制实现对输入序列的动态对齐,并引入 teacher forcing 线性衰减、early stopping 和 dropout 等正则化手段保障训练稳定性。实验结果表明,模型在 245 条验证集上达到 95.5% 的 token 级准确率,训练与验证指标差距控制在 2% 以内,损失曲线收敛平滑,表明模型具备良好的泛化能力。在工程层面,项目基于 Flask 框架实现了 Web 端的摘要生成与可视化展示,具备完整的端到端部署能力。
项目资源
包括完整的项目源代码、演示视频、运行截图,开箱即用。

关于项目
原创论文
原创论文:基于LSTM的新闻文本摘要系统的设计与实现 注意:需要另外付费购买!
作者信息
作者:Bob (张家梁)
项目编号:YD-9
原创声明:本项目为原创作品

开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)